38. 【实战】分类式 Reranker 模型微调#
38.1. 任务背景#
检索式问答系统是一种基于已有知识库或文档库,通过检索和匹配技术来回答用户问题的智能问答系统。它的核心工作流程是:先理解用户用自然语言提出的问题,然后从海量数据中快速召回最相关的信息片段,再通过排序和匹配模型筛选出最精准的答案返回给用户,而不是像搜索引擎那样只返回一堆相关链接。
若只用轻量的检索策略(如BM25关键词匹配、轻量Embedding向量检索),虽然速度快,但精度有限:无法处理语义表述差异、同义词匹配问题,大规模知识库下召回的相关片段里噪声很多,容易漏掉真正相关的答案;
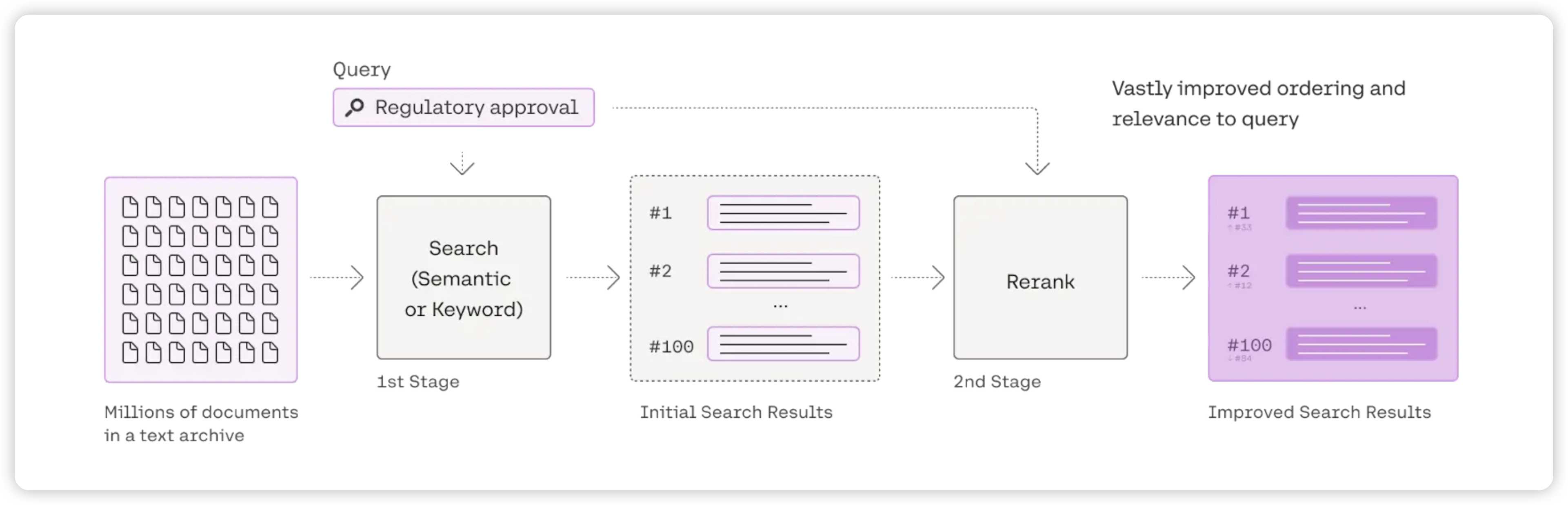
为了弥补轻量检索策略在语义理解和噪声过滤上的不足,进一步提升检索结果的准确性与排序质量,通常需要在召回阶段之后引入精排序(Reranker)模型。
38.2. 任务目标#
目前的 Reranker 模型的实现方式主要有两种:分类式和生成式。
分类式 Reranker:将重排序任务建模为相关性判断问题,本质上是二分类模型。对于每一个(查询 Query, 候选文档 Document)对,模型会输出一个相关性分数(如 0~1 之间的概率值),用以衡量文档与查询的匹配程度。
生成式 Reranker:则基于大语言模型(LLM),通过设计特定的提示(Prompt),让模型直接生成排序指令或相关性判断结果。
本次任务我们将会训练换一个分类式 Reranker 模型,对检索召回的问题进行重排序,提高问答系统的答案准确性和相关性。
本次任务使的模型、微调方式和微调框架如下:
基础模型:bge-reranker-v2-m3
微调方式:全量微调
微调框架:Swift
38.3. 学习收获#
通过本次任务,你将:
掌握基于语义的向量知识库的构建方法
学会利用语义相似度快速召回相关知识
理解 Reranker 模型的必要性及其训练目标
了解分类式与生成式 Reranker 模型的核心差异
掌握分类式 Reranker 模型训练数据的构造方法
掌握分类式 Reranker 模型的训练流程
38.4. 获取源码#
点击下方链接,获取任务完整源码 👇👇👇
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。