
16. 构造 Transformer 数据集#
基于训练语料构建加法计算数据集,并封装成数据模组供模型训练时使用。
Transformer 模型分为编码器和解码器,前者负责编码输入序列,后者负责解码输出序列。所以我们会将一个完整的计算算法处理成 3 部分:
原始数据:保留原始问题和答案,方便观察结果。
编码器数据:编码器的输入序列和填充掩码,填充掩码用于计算注意力。
解码器数据:解码器做的时自回归任务有输入和输出,所以解码器数据包含输入序列、输出出列以及填充掩码 3 部分。
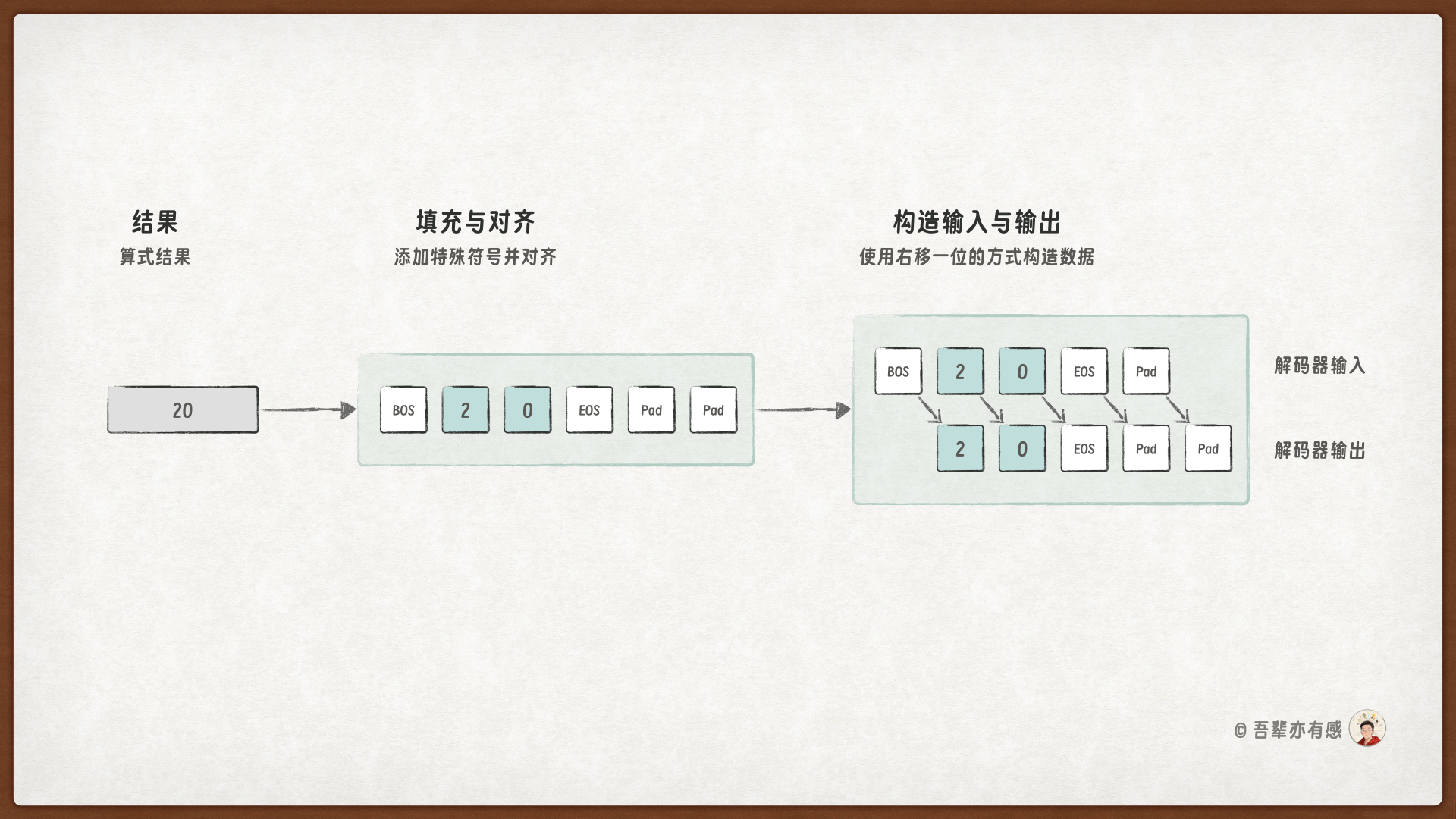
以 12+8=20 为例,我们会处理成如下 json 格式:
{
'question': '12+8',
'answer': '20',
'encoder_input_ids': tensor([ 1, 2, 10, 8, 12, 12, 12]),
'encoder_pad_mask': tensor([1, 1, 1, 1, 0, 0, 0]),
'decoder_input_ids': tensor([14, 2, 0, 15, 12]),
'decoder_pad_mask': tensor([1, 1, 1, 1, 0]),
'decoder_target_ids': tensor([ 2, 0, 15, 12, 12])
}
其中:
question: 问题文本,原始问题。answer: 问题的答案,原始答案。encoder_input_ids: 编码器的输入序列,问题文本对齐填充后的 token ID 序列。encoder_pad_mask: 编码器输入的填充掩码,用于计算注意力。decoder_input_ids: 解码器的输入序列。decoder_pad_mask: 解码器输入的填充掩码,用于计算注意力。decoder_target_ids: 解码器的目标序列。
Transformer 解码器做的任务是自回归任务,即根据前一个词预测下一个词。
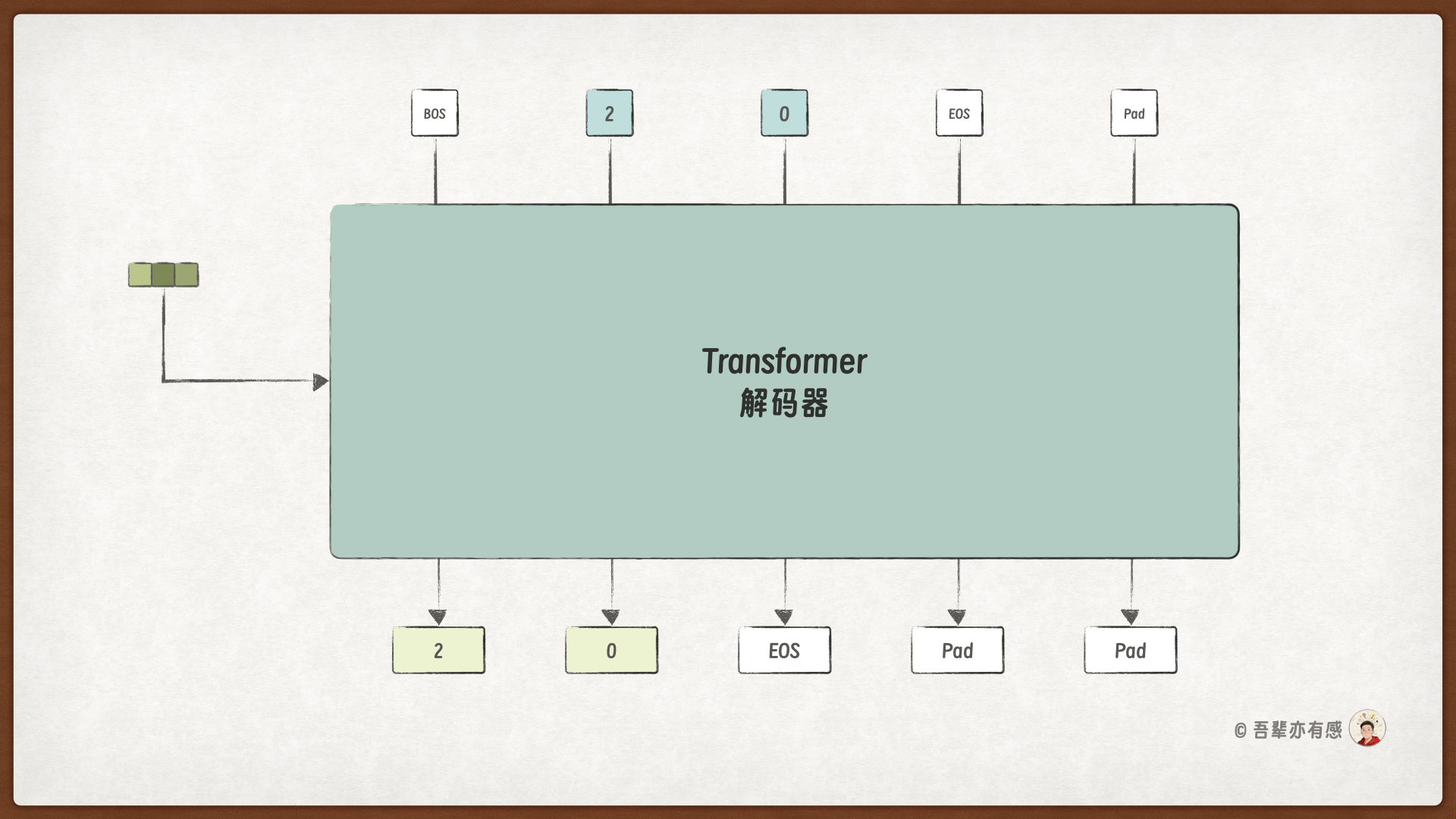
所以解码器处理数据的过程相对比较复杂,有两点需要注意:
首先,先在原始问题中添加开始和结束标记,让模型知道何时开始和停止生成答案。
其次,自回归任务采用右移 1 位的方式生成目标序列。
16.1. 环境配置#
16.1.1. 安装依赖#
!pip install --upgrade dsxllm
16.1.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
16.2. 数据集下载#
16.3. 观察数据#
处理数据之前,我们再观察一遍训练数据的格式。
# 打开文件并读取前5行
from dsxllm.util import load_first_n_lines
load_first_n_lines('./dataset/addition_train.txt', 5)
行数 内容
0 1 12+991=1003
1 2 188+350=538
2 3 60+899=959
3 4 122+72=194
4 5 727+52=779
16.4. 实现数据转换器#
使用 TransformerTokenizer 对问题和答案进行分词并对齐,生成对应的 token ID 序列和填充掩码。
from dsxllm.transformer.tokenizer import TransformerTokenizer
class TextTransform:
""" 文本转换类,用于将原始文本转换为模型可用的输入格式 """
def __init__(self, tokenizer: TransformerTokenizer, max_length=20):
"""
初始化文本转换器
参数:
tokenizer: Transformer 分词器实例
max_length: 序列最大长度,默认为 20
"""
self.tokenizer = tokenizer
self.max_length = max_length
def __call__(self, text):
"""
调用方法,将文本转换为 token ID 序列
参数:
text: 输入的原始文本字符串
返回:
经过分词、填充和截断后的张量数据
"""
return self.tokenizer(text, max_length=self.max_length, padding=True, return_tensors=True)
16.5. 自定义数据集#
在 __getitem__ 方法中,我们根据索引获取单个样本,并进行相应的处理和转换,最终返回符合 Transformer 模型需求的数据格式。
16.5.1. 自定义加法数据集的代码实现#
from torch.utils.data import Dataset
class TextGenerationDataset(Dataset):
def __init__(self, questions, answers, encoder_transform: TextTransform, decoder_transform: TextTransform):
"""
初始化数据集
参数:
questions: 问题列表
answers: 答案列表
encoder_transform: Encoder 端的文本转换器
decoder_transform: Decoder 端的文本转换器
"""
self.questions = questions
self.answers = answers
self.encoder_transform = encoder_transform
self.decoder_transform = decoder_transform
def __len__(self):
"""返回数据集的大小"""
return len(self.questions)
def __getitem__(self, idx):
"""
根据索引获取单个样本
参数:
idx: 样本索引
返回:
包含编码器输入、解码器输入和目标的字典
"""
question = self.questions[idx]
answer = self.answers[idx]
# 统一处理:始终为答案添加开始和结束标记
# bos_token 作为解码器的起始标记,eos_token 作为结束标记
processed_answer = self.decoder_transform.tokenizer.bos_token + answer + self.decoder_transform.tokenizer.eos_token
# 编码问题(Encoder 输入)
question_encoded = self.encoder_transform(question)
encoder_input_ids = question_encoded["input_ids"] # 问题 token ID 序列
encoder_pad_mask = question_encoded["attention_mask"] # 填充掩码,用于忽略 padding 位置
# 编码答案(用于构造 Decoder 的输入和目标)
answer_encoded = self.decoder_transform(processed_answer)
answer_ids = answer_encoded["input_ids"] # 答案 token ID 序列
answer_pad_mask = answer_encoded["attention_mask"] # 答案填充掩码
# 统一处理解码器输入输出序列
# decoder_input_ids: 去掉最后一个 token(作为输入序列)
# decoder_target_ids: 去掉第一个 token(作为预测目标)
# 这样实现了自回归 teacher forcing 训练方式
decoder_input_ids = answer_ids[:-1].clone().detach()
decoder_pad_mask = answer_pad_mask[:-1].clone().detach()
decoder_target_ids = answer_ids[1:].clone().detach()
return {
"question": question, # 原始问题文本
"answer": answer, # 原始答案文本
'encoder_input_ids': encoder_input_ids, # 编码器输入 ID
'encoder_pad_mask': encoder_pad_mask, # 编码器填充掩码
'decoder_input_ids': decoder_input_ids, # 解码器输入 ID
'decoder_pad_mask': decoder_pad_mask, # 解码器填充掩码
'decoder_target_ids': decoder_target_ids # 解码器预测目标 ID
}
@classmethod
def from_file(cls, file_path, encoder_transform: TextTransform, decoder_transform: TextTransform):
"""
从txt文件加载数据集
txt格式应包含标签和文本,使用制表符分隔
"""
questions = []
answers = []
# 读取txt文件
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
if line.strip() == '': # 跳过空行
continue
try:
# 查找等号的位置,将行分割为问题和答案
idx = line.find('=')
# 将样本添加到列表中: (question, answer),answer中去掉"="以及最后的"\n"
question = line[:idx]
answer = line[idx + 1:].strip()
questions.append(question)
answers.append(answer)
except Exception as e:
# 如果处理某行时出错,打印错误信息并跳过
print(f"Error processing line: {line}")
print(f"Error message: {e}")
continue
# 创建数据集实例
return cls(questions, answers, encoder_transform, decoder_transform)
16.5.2. 创建自定义加法数据集的实例#
from dsxllm.transformer.tokenizer import get_tokenizer
from pprint import pprint
# 1️⃣ 初始化分词器
tokenizer = get_tokenizer()
# 2️⃣ 初始化数据转换
encoder_transform = TextTransform(tokenizer, max_length=7)
decoder_transform = TextTransform(tokenizer, max_length=6)
# 3️⃣ 加载数据集
file_path = "./dataset/addition_train.txt"
dataset = TextGenerationDataset.from_file(file_path, encoder_transform=encoder_transform,
decoder_transform=decoder_transform)
pprint(dataset[0], sort_dicts=False)
{'question': '12+991',
'answer': '1003',
'encoder_input_ids': tensor([ 1, 2, 10, 9, 9, 1, 12]),
'encoder_pad_mask': tensor([1, 1, 1, 1, 1, 1, 0]),
'decoder_input_ids': tensor([14, 1, 0, 0, 3]),
'decoder_pad_mask': tensor([1, 1, 1, 1, 1]),
'decoder_target_ids': tensor([ 1, 0, 0, 3, 15])}
这里需要注意:
编码器的数据最长为
三位数 + 三位数,所以序列最大长度为 7。解码器的数据最长的长度为
开始符、四位数结果和结束符,所以序列最大长度为 6。
16.6. 构建数据模组#
加法数据模组继承自 LightningDataModule,用于统一管理训练、验证和测试数据集。
16.6.1. 加法数据模组的代码实现#
import lightning as L
from torch.utils.data import DataLoader
class TextDataModule(L.LightningDataModule):
"""
文本生成任务的数据模块
继承自LightningDataModule,用于管理训练、验证和测试数据的加载
"""
def __init__(
self,
batch_size,
encoder_transform: TextTransform,
decoder_transform: TextTransform,
train_data_file,
val_data_file="",
test_data_file="",
):
"""
初始化数据模块
Args:
batch_size: 批次大小
encoder_transform: 编码器文本转换器
decoder_transform: 解码器文本转换器
train_data_file: 训练数据文件路径
val_data_file: 验证数据文件路径(可选)
test_data_file: 测试数据文件路径(可选)
"""
super().__init__()
self.batch_size = batch_size # 设置批次大小
self.encoder_transform = encoder_transform # 编码器文本预处理转换器
self.decoder_transform = decoder_transform # 解码器文本预处理转换器
self.train_data_file = train_data_file # 训练数据文件路径
self.val_data_file = val_data_file # 验证数据文件路径
self.test_data_file = test_data_file # 测试数据文件路径
# 初始化数据集属性
self.test_dataset = None # 测试数据集
self.val_dataset = None # 验证数据集
self.train_dataset = None # 训练数据集
def prepare_data(self):
"""
准备数据的方法
用于下载数据集或进行一次性数据预处理操作
"""
pass
def setup(self, stage=None):
"""
设置数据集的方法
"""
# 加载训练数据集
self.train_dataset = TextGenerationDataset.from_file(
self.train_data_file,
encoder_transform=self.encoder_transform,
decoder_transform=self.decoder_transform,
)
# 加载验证数据集
if self.val_data_file == "":
# 如果没有指定验证集,则使用训练集作为验证集
self.val_dataset = self.train_dataset
else:
# 加载指定的验证数据集
self.val_dataset = TextGenerationDataset.from_file(
self.val_data_file,
encoder_transform=self.encoder_transform,
decoder_transform=self.decoder_transform,
)
# 加载测试数据集
if self.test_data_file == "":
# 如果没有指定测试集,则使用训练集作为测试集
self.test_dataset = self.train_dataset
else:
# 加载指定的测试数据集
self.test_dataset = TextGenerationDataset.from_file(
self.test_data_file,
encoder_transform=self.encoder_transform,
decoder_transform=self.decoder_transform,
)
def train_dataloader(self):
"""
返回训练数据加载器
Returns:
DataLoader: 训练数据的DataLoader对象
"""
return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
"""
返回验证数据加载器
Returns:
DataLoader: 验证数据的DataLoader对象
"""
return DataLoader(self.val_dataset, batch_size=self.batch_size)
def test_dataloader(self):
"""
返回测试数据加载器
Returns:
DataLoader: 测试数据的DataLoader对象
"""
return DataLoader(self.test_dataset, batch_size=self.batch_size)
16.6.2. 创建加法数据模组的实例#
from pprint import pprint
# 1️⃣ 初始化分词器
tokenizer = get_tokenizer()
# 2️⃣ 初始化数据转换
encoder_transform = TextTransform(tokenizer, max_length=7)
decoder_transform = TextTransform(tokenizer, max_length=6)
# 3️⃣ 加载数据模组
file_path = "./dataset/addition_train.txt"
text_datamodule = TextDataModule(batch_size=2, encoder_transform=encoder_transform, decoder_transform=decoder_transform,
train_data_file=file_path)
# 4️⃣ 调用 setup 方法初始化数据集
text_datamodule.setup()
# 5️⃣ 打印一个批次的数据
print("打印一个批次的数据:")
for batch in text_datamodule.train_dataloader():
pprint(batch, sort_dicts=False)
break
打印一个批次的数据:
{'question': ['89+65', '71+685'],
'answer': ['154', '756'],
'encoder_input_ids': tensor([[ 8, 9, 10, 6, 5, 12, 12],
[ 7, 1, 10, 6, 8, 5, 12]]),
'encoder_pad_mask': tensor([[1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0]]),
'decoder_input_ids': tensor([[14, 1, 5, 4, 15],
[14, 7, 5, 6, 15]]),
'decoder_pad_mask': tensor([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]]),
'decoder_target_ids': tensor([[ 1, 5, 4, 15, 12],
[ 7, 5, 6, 15, 12]])}
16.7. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。