
28. 实现 GPT 前馈网络层#
28.1. 介绍#
上一节我们已成实现 Transformer 块的带掩码的多头注意力层组件,本小节将继续实现 Transformer 块的前馈网络层。
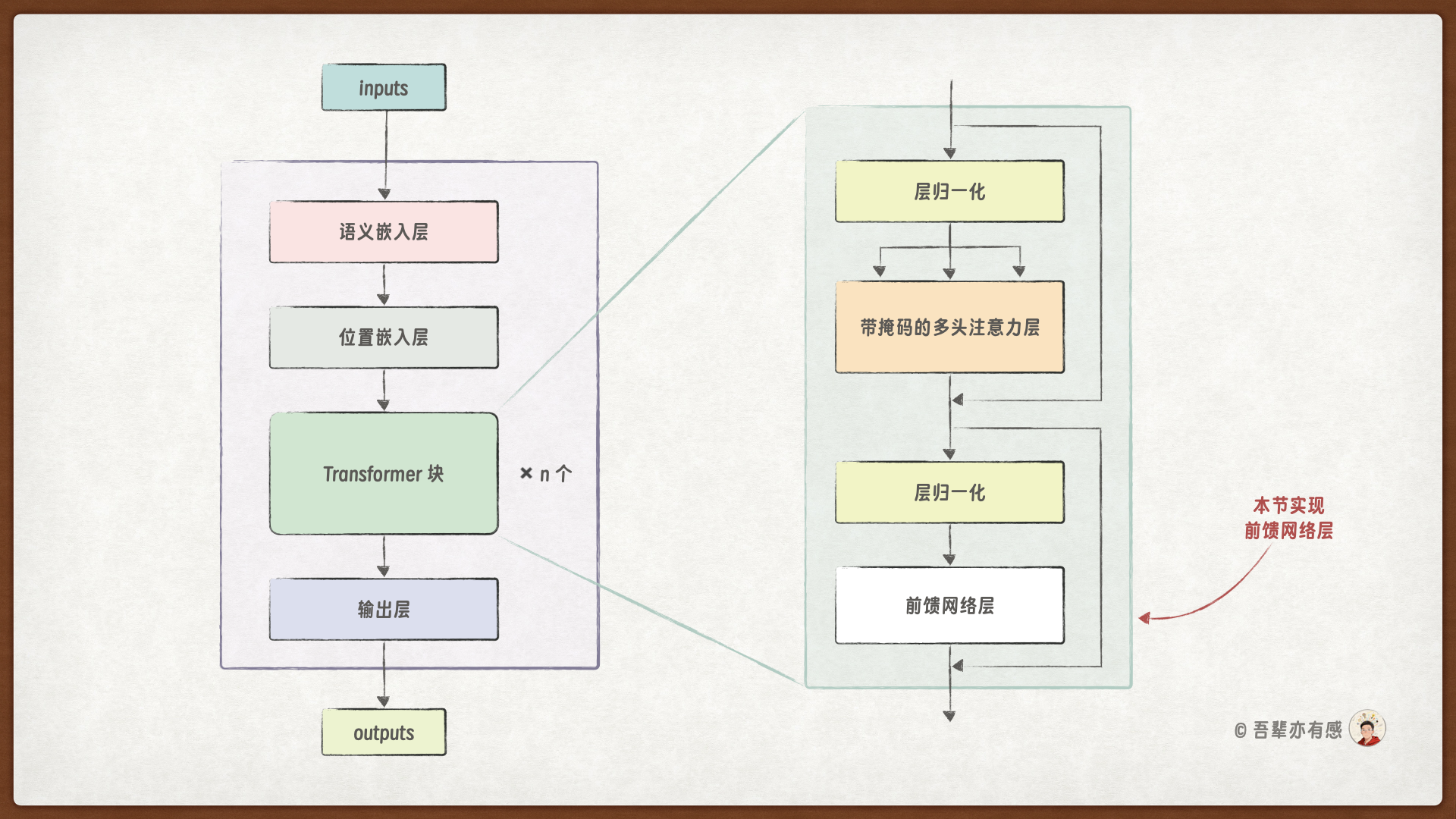
28.2. 环境配置#
28.2.1. 安装依赖#
!pip install --upgrade dsxllm
28.2.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
28.3. 前馈网络层#
前馈网络层是 Transformer 块的第二个子层,位于多头自注意力层之后。它通过非线性变换、维度扩展与压缩等方式,对 Token 的信息进一步的融合,从而增强模型的表达能力。
前馈网络层包括三个线性层:
第一个线性层是升维层,将输入升维到一个高维空间(通常是嵌入维度的 4 倍),然后通过激活函数进行非线性变换。
第二个线性层是门控层,目的是引入一个并行的”门”,来控制信息的流动,允许模型在某些特征上进行更重要的关注。
第三个线性层是降维层,将特征降维回原始维度。这种维度扩展与压缩的过程增加了模型的容量,允许更复杂的特征表示。
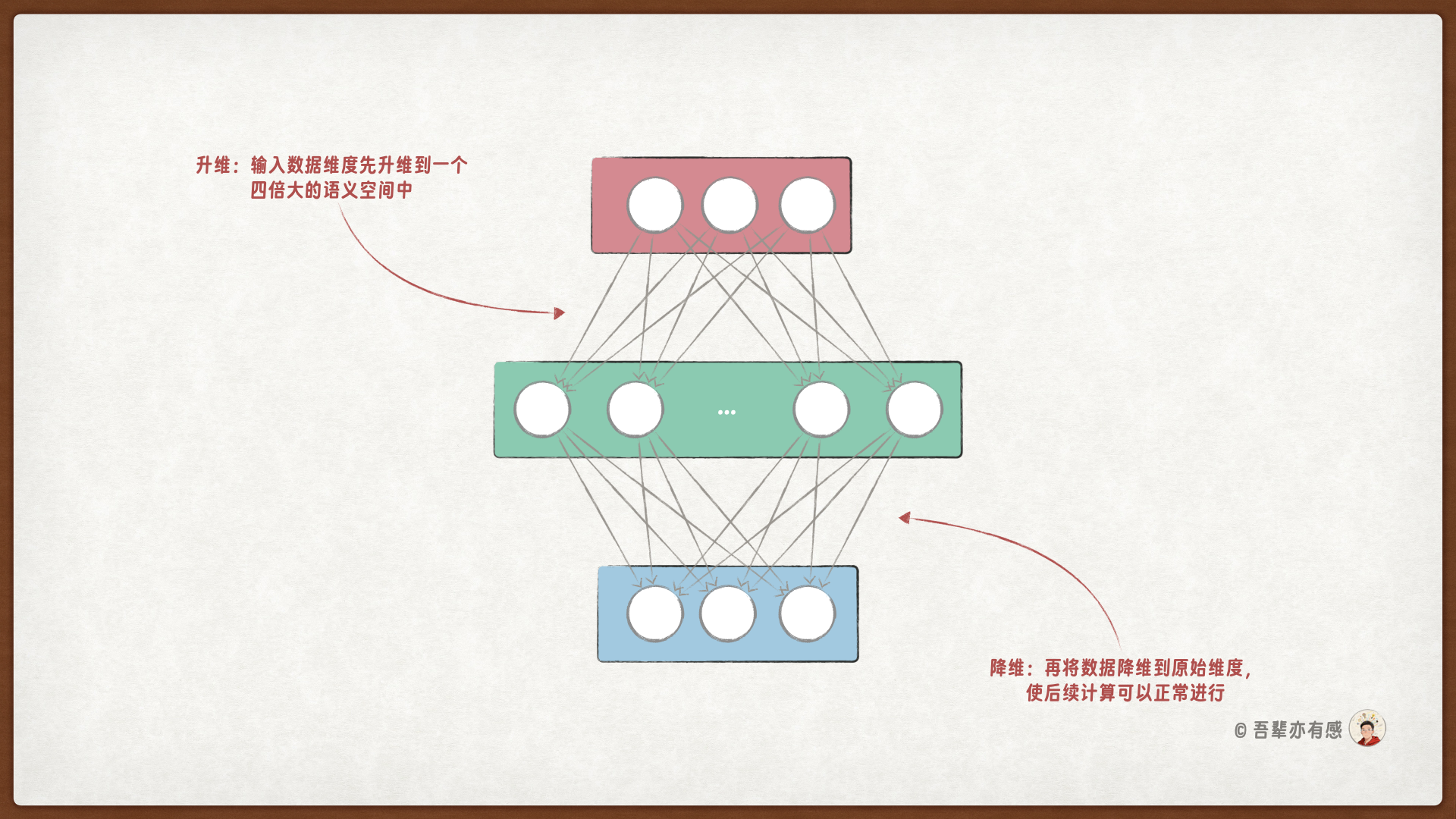
前馈网络层的内部结构如下图所示:
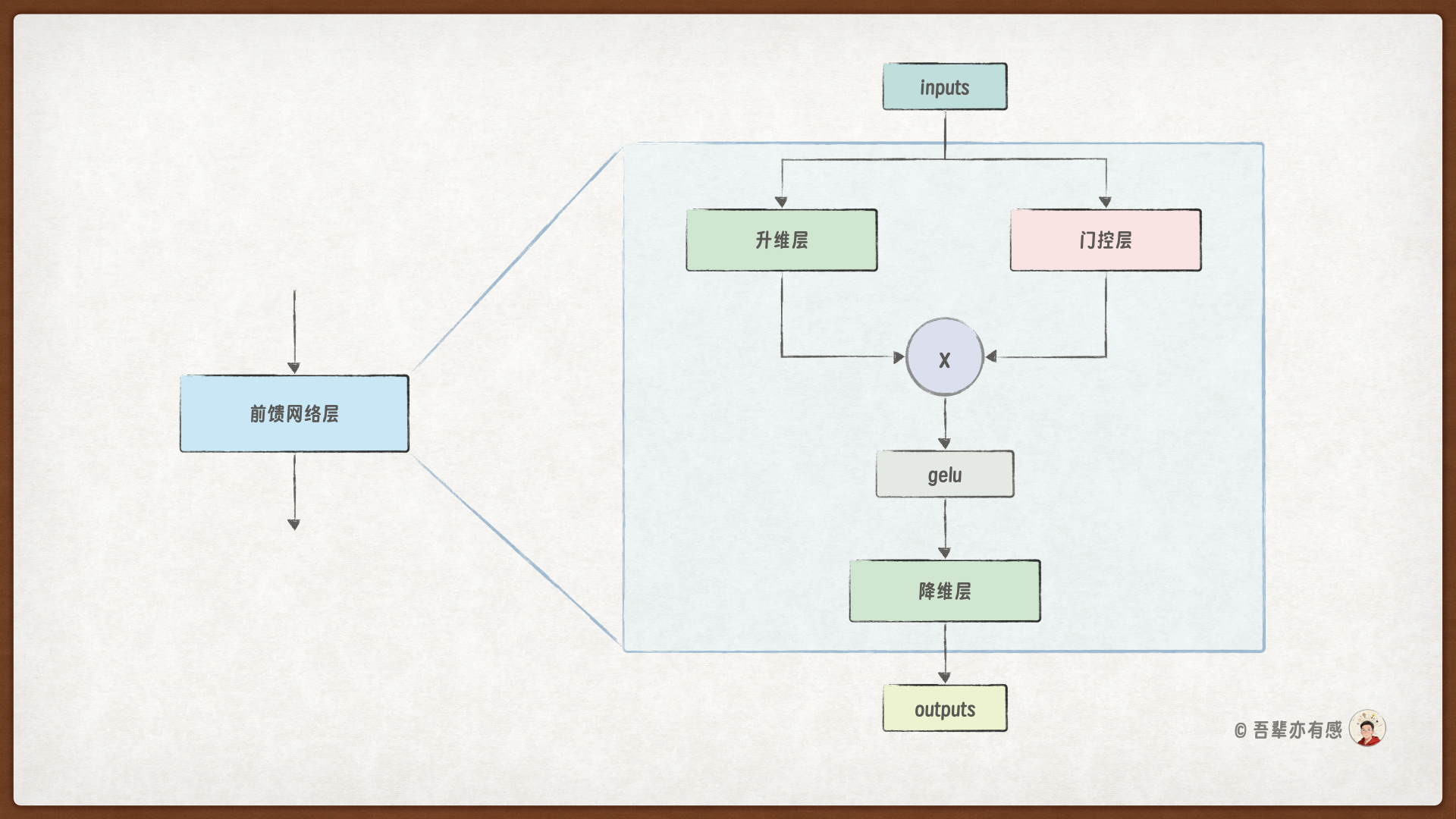
28.4. 前馈网络层的代码实现#
import torch
from transformers.activations import ACT2FN
class FeedForward(torch.nn.Module):
"""
带有门控机制的前馈神经网络(GLU变体)。
该模块包含三个线性变换:
- up_layer: 将输入维度从 d_model 扩展到 4 * d_model
- gate_layer: 同样将输入扩展到 4 * d_model,作为门控信号
- down_layer: 将合并后的 4 * d_model 维度压缩回 d_model
计算公式:
output = down_layer(activation(gate_layer(x)) * up_layer(x) )
其中 activation 默认为 GELU,通过门控机制实现特征选择。
Args:
config (dict): 配置字典,必须包含键 "d_model"(模型维度)。
hidden_act (str): 激活函数名称,默认为 "gelu"。
"""
def __init__(self, d_model, hidden_act="gelu"):
super().__init__()
feedforward_size = 4 * d_model
# 升维线性层:将输入升维到隐藏维度
self.up_layer = torch.nn.Linear(
in_features=d_model, out_features=feedforward_size, bias=False
)
# 门控线性层:生成门控信号,用于控制信息流动
self.gate_layer = torch.nn.Linear(
in_features=d_model, out_features=feedforward_size, bias=False
)
# 降维线性层:将隐藏维度降回原始维度
self.down_layer = torch.nn.Linear(
in_features=feedforward_size, out_features=d_model, bias=False
)
# 激活函数
self.activation_fn = ACT2FN[hidden_act]
def forward(self, x):
"""
前向传播。
Args:
x (torch.Tensor): 输入张量,形状为 (batch_size, seq_len, d_model)。
Returns:
torch.Tensor: 输出张量,形状与输入相同。
"""
# 门控机制:激活(门控(x)) * 升维(x)
gated = self.activation_fn(self.gate_layer(x)) * self.up_layer(x)
# 降维到原始维度
output = self.down_layer(gated)
return output
28.5. 前馈网络层的详细信息#
from torchinfo import summary
# 创建模型实例
ffn = FeedForward(d_model=128)
# 查看详细 Summary
summary(
ffn,
input_size=(32, 10, 128),
col_names=("input_size", "output_size", "num_params"),
row_settings=("var_names",),
)
===================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param #
===================================================================================================================
FeedForward (FeedForward) [32, 10, 128] [32, 10, 128] --
├─Linear (gate_layer) [32, 10, 128] [32, 10, 512] 65,536
├─GELUActivation (activation_fn) [32, 10, 512] [32, 10, 512] --
├─Linear (up_layer) [32, 10, 128] [32, 10, 512] 65,536
├─Linear (down_layer) [32, 10, 512] [32, 10, 128] 65,536
===================================================================================================================
Total params: 196,608
Trainable params: 196,608
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 6.29
===================================================================================================================
Input size (MB): 0.16
Forward/backward pass size (MB): 2.95
Params size (MB): 0.79
Estimated Total Size (MB): 3.90
===================================================================================================================
28.6. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。