
29. 实现 Transformer Block 模块#
29.1. 介绍#
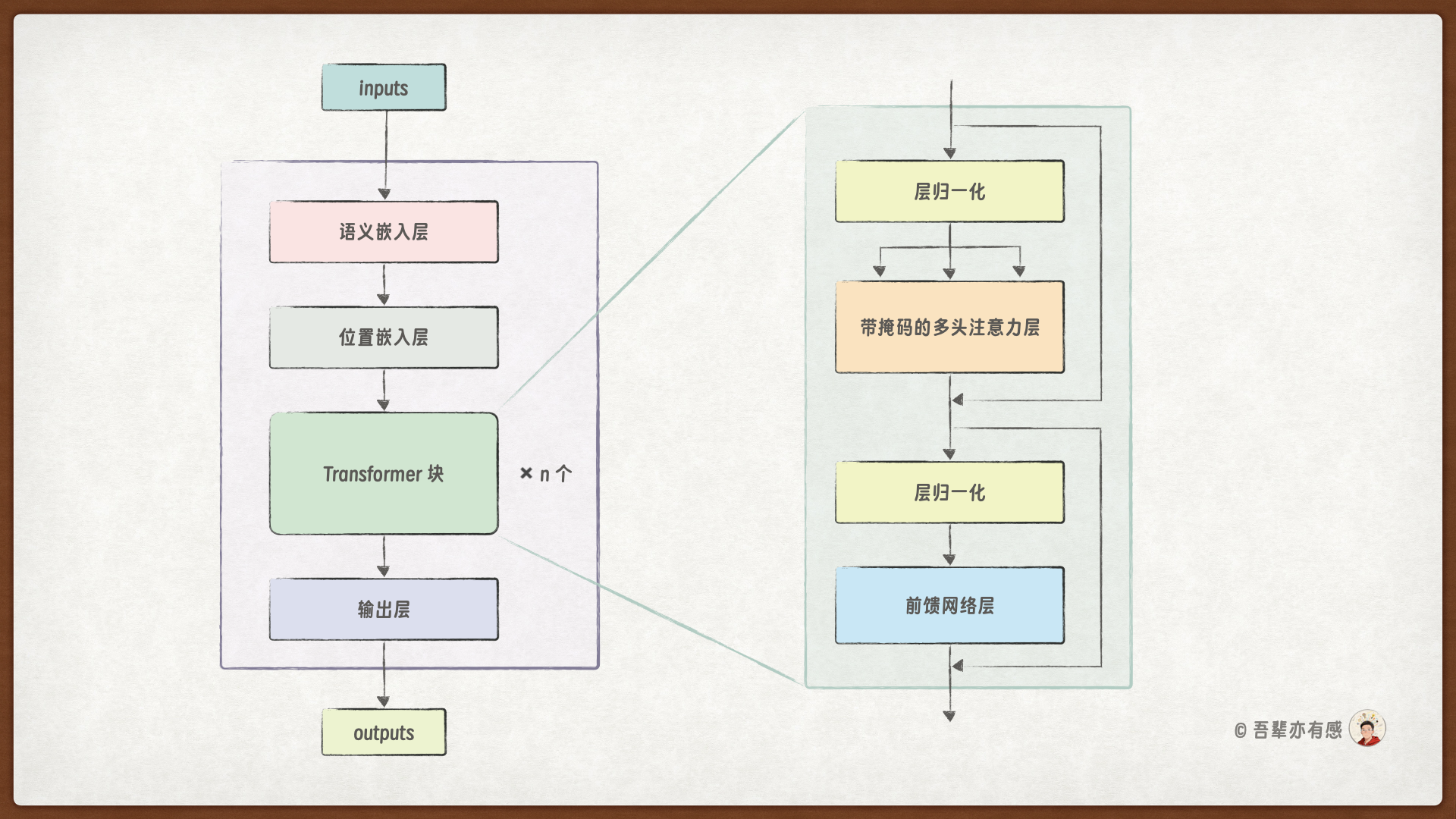
前面我们已经实现了 Transformer 块中所有的子层,本小节将继续实现完整的 Transformer 块。
29.2. 环境配置#
29.2.1. 安装依赖#
!pip install --upgrade dsxllm
29.2.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
29.3. Transformer Block#
在 GPT 模型中,Transformer Block 是模型的核心构建单元,它通过一些类复杂的计算,能不断提炼和深化对输入文本的理解,让每个位置的 Token 都能融合丰富的上下文信息。同时,GPT 模型可以使用多个 Transformer Block 层的堆叠来处理不同层次的特征,从而实现对复杂文本的有效建模。
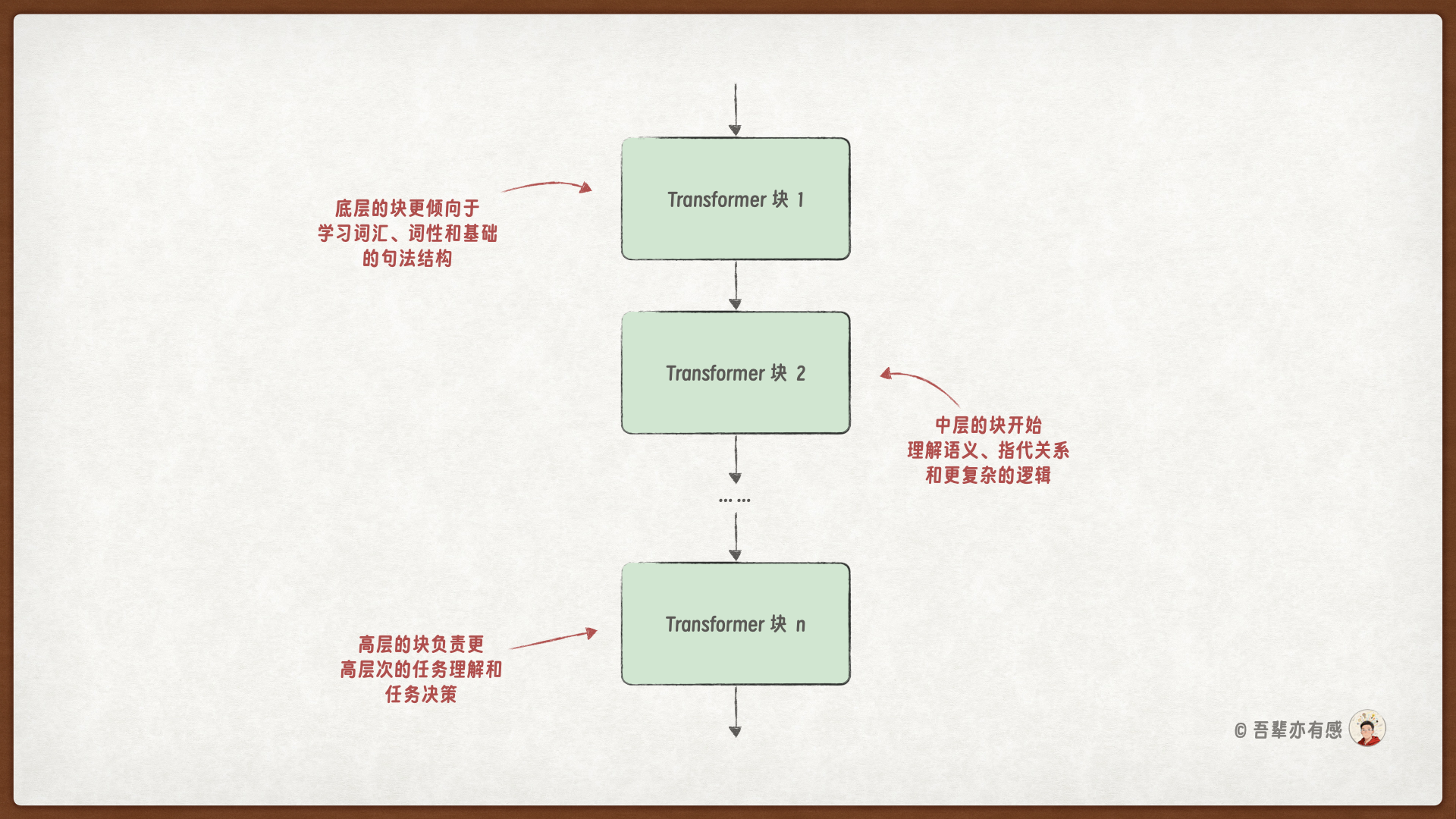
底层的块:更倾向于学习词汇、词性和基础的句法结构。
中层的块:开始理解语义、指代关系和更复杂的逻辑。
高层的块:负责主题归纳、概念抽象、逻辑推理等更高层次的语义理解和任务决策。
29.4. Transformer Block 的代码实现#
import torch
from dsxllm.gpt.layer import LayerNorm, MultiHeadAttention, FeedForward
class TransformerBlock(torch.nn.Module):
"""
标准 Transformer 编码器块,包含多头自注意力和前馈网络,每个子层后均有残差连接和层归一化。
Args:
config (dict): 配置字典,必须包含以下键:
- d_model: 模型维度
- seq_len: 上下文长度
- n_heads: 注意力头数
- drop_rate: Dropout 概率
- qkv_bias: QKV 投影是否使用偏置
"""
def __init__(self, d_model, seq_len, n_heads, drop_rate=0.1, qkv_bias=False):
super().__init__()
self.attention_norm = LayerNorm(d_model)
self.attention_layer = MultiHeadAttention(
input_dim=d_model,
output_dim=d_model,
seq_len=seq_len,
num_heads=n_heads,
dropout=drop_rate,
qkv_bias=qkv_bias,
)
self.feed_forward_norm = LayerNorm(d_model)
self.feed_forward_layer = FeedForward(d_model)
# Dropout 层,用于防止过拟合
self.residual_dropout = torch.nn.Dropout(drop_rate)
def forward(self, x):
"""
前向传播。
Args:
x (torch.Tensor): 输入张量,形状为 (batch_size, seq_len, d_model)。
Returns:
torch.Tensor: 输出张量,形状相同。
"""
# 注意力子层(残差连接)
residual = x # 保存输入作为残差连接
x = self.attention_norm(x) # 自注意力计算前对输入进行层归一化
x = self.attention_layer(
x
) # 应用多头注意力机制,输出形状为 [batch_size, seq_len, d_model]
x = self.residual_dropout(x) # 应用 Dropout 层,防止过拟合
x = x + residual # 将注意力子层的输出与输入残差相加,形成残差连接
# 前馈子层(残差连接)
residual = x # 保存注意力子层的输出作为残差连接
x = self.feed_forward_norm(x) # 前馈计算前对输入进行层归一化
x = self.feed_forward_layer(
x
) # 应用前馈网络,输出形状为 [batch_size, seq_len, d_model]
x = self.residual_dropout(x) # 应用 Dropout 层,防止过拟合
x = x + residual # 将前馈子层的输出与输入残差相加,形成残差连接
return x
29.5. Transformer Block 的详细信息#
from torchinfo import summary
# 超参配置
batch_size = 32
d_model = 128
num_heads = 8
seq_len = 10
# 创建模型实例
transformer_block = TransformerBlock(
d_model=d_model, seq_len=seq_len, n_heads=num_heads
)
# 查看详细 Summary
summary(
transformer_block,
input_size=(batch_size, seq_len, d_model),
col_names=("input_size", "output_size", "num_params"),
row_settings=("var_names",),
)
========================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param #
========================================================================================================================
TransformerBlock (TransformerBlock) [32, 10, 128] [32, 10, 128] --
├─LayerNorm (attention_norm) [32, 10, 128] [32, 10, 128] 256
├─MultiHeadAttention (attention_layer) [32, 10, 128] [32, 10, 128] --
│ └─Linear (query_layer) [32, 10, 128] [32, 10, 128] 16,384
│ └─Linear (key_layer) [32, 10, 128] [32, 10, 128] 16,384
│ └─Linear (value_layer) [32, 10, 128] [32, 10, 128] 16,384
│ └─Dropout (dropout) [32, 8, 10, 10] [32, 8, 10, 10] --
│ └─Linear (output_layer) [32, 10, 128] [32, 10, 128] 16,512
├─Dropout (residual_dropout) [32, 10, 128] [32, 10, 128] --
├─LayerNorm (feed_forward_norm) [32, 10, 128] [32, 10, 128] 256
├─FeedForward (feed_forward_layer) [32, 10, 128] [32, 10, 128] --
│ └─Linear (gate_layer) [32, 10, 128] [32, 10, 512] 65,536
│ └─GELUActivation (activation_fn) [32, 10, 512] [32, 10, 512] --
│ └─Linear (up_layer) [32, 10, 128] [32, 10, 512] 65,536
│ └─Linear (down_layer) [32, 10, 512] [32, 10, 128] 65,536
├─Dropout (residual_dropout) [32, 10, 128] [32, 10, 128] --
========================================================================================================================
Total params: 262,784
Trainable params: 262,784
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 8.39
========================================================================================================================
Input size (MB): 0.16
Forward/backward pass size (MB): 4.92
Params size (MB): 1.05
Estimated Total Size (MB): 6.13
========================================================================================================================
29.6. Transformer Block 的应用实例#
29.6.1. 单个 Transformer Block 层的计算#
from dsxllm.util import print_table
# 超参配置
batch_size = 32
d_model = 128
num_heads = 8
seq_len = 10
# 创建输入张量
x = torch.randn(batch_size, seq_len, d_model)
# 创建模型实例
transformer_block = TransformerBlock(
d_model=d_model, seq_len=seq_len, n_heads=num_heads
)
# 使用 Transformer Block 进行前向传播
attention_out = transformer_block(x)
# 打印 Transformer Block 的输入与输出
print_table(
table_name="Transformer Block 的输入与输出",
field_names=["Value", "Shape"],
data=[["输入", x.shape], ["输出", attention_out.shape]],
)
Transformer Block 的输入与输出:
+-------+---------------------------+
| Value | Shape |
+-------+---------------------------+
| 输入 | torch.Size([32, 10, 128]) |
| 输出 | torch.Size([32, 10, 128]) |
+-------+---------------------------+
29.6.2. 多个 Transformer Block 层的计算#
from dsxllm.util import print_table
# 超参配置
batch_size = 32
d_model = 128
num_heads = 8
seq_len = 10
n_layers = 4
# 创建输入张量
x = torch.randn(batch_size, seq_len, d_model)
# 创建 n_layers 个 TransformerBlock 层堆叠的实例
transformer_blocks = torch.nn.Sequential(
*[
TransformerBlock(d_model=d_model, seq_len=seq_len, n_heads=num_heads)
for _ in range(n_layers)
]
)
# 使用 Transformer Blocks 进行前向传播
attention_out = transformer_blocks(x)
# 打印 Transformer Blocks 的输入与输出
print_table(
table_name="Transformer Block 的输入与输出",
field_names=["Value", "Shape"],
data=[["输入", x.shape], ["输出", attention_out.shape]],
)
Transformer Block 的输入与输出:
+-------+---------------------------+
| Value | Shape |
+-------+---------------------------+
| 输入 | torch.Size([32, 10, 128]) |
| 输出 | torch.Size([32, 10, 128]) |
+-------+---------------------------+
29.7. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。