
17. 实现 Transformer Input 组件#
本章我们开始深入 Transformer 模型的细节,实现 Transformer 模型中输入模块的位置编码组件。
17.1. 环境配置#
17.1.1. 安装依赖#
!pip install --upgrade dsxllm
17.1.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
17.2. Transformer 模型架构#
Transformer 是一种基于编码器-解码器(Encoder-Decoder)架构的序列到序列(Seq2Seq)模型。在正式介绍 Transformer 模型之前,我们先简要回顾此前基于 GRU 实现的 Seq2Seq 加法计算模型。
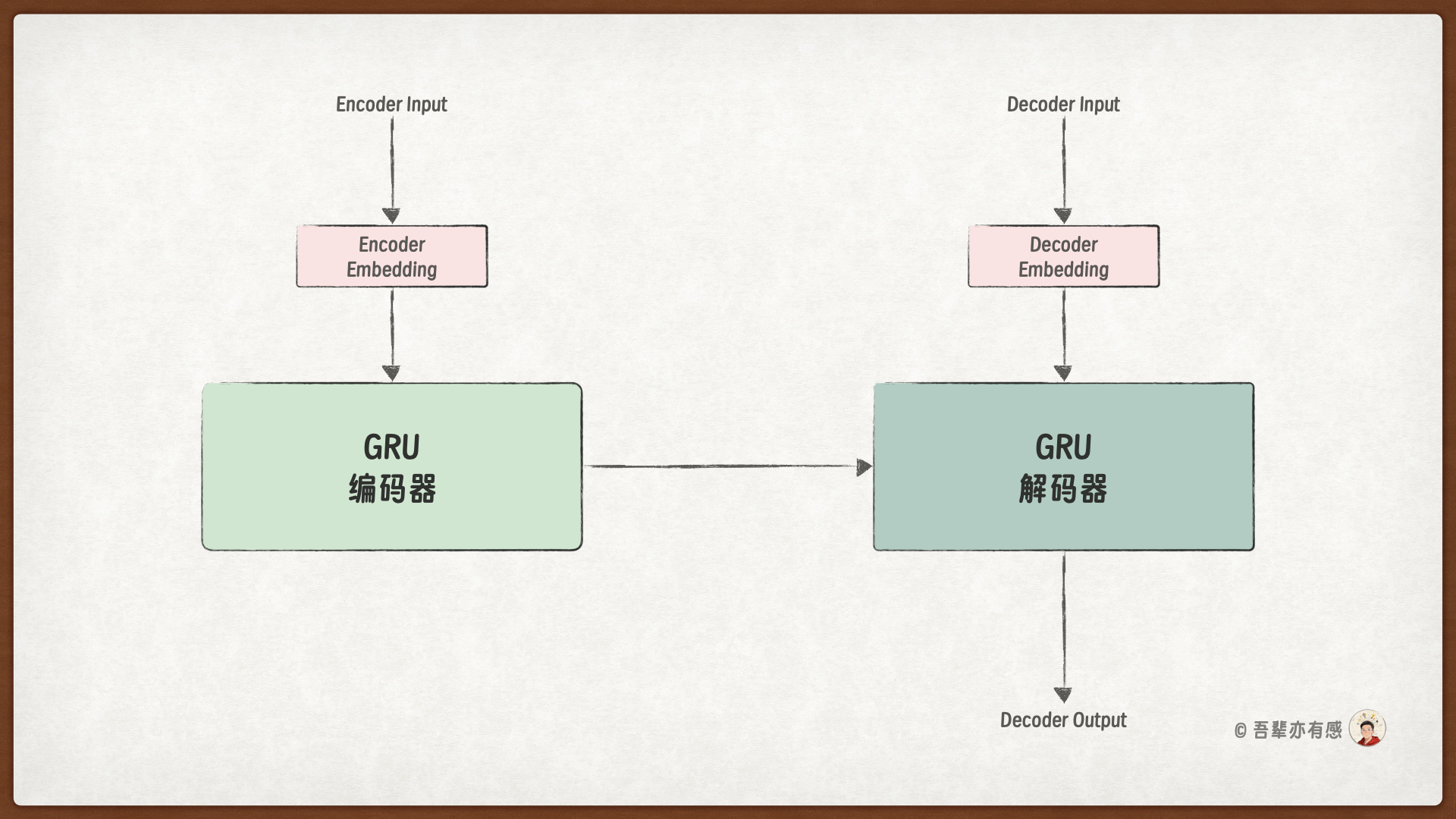
基于 GRU 的 Seq2Seq 加法计算模型整体上由三个部分组成:输入模块、编码器模块和解码器模块。类似地,Transformer 模型也由这三个部分组成,但在处理细节上有所不同。
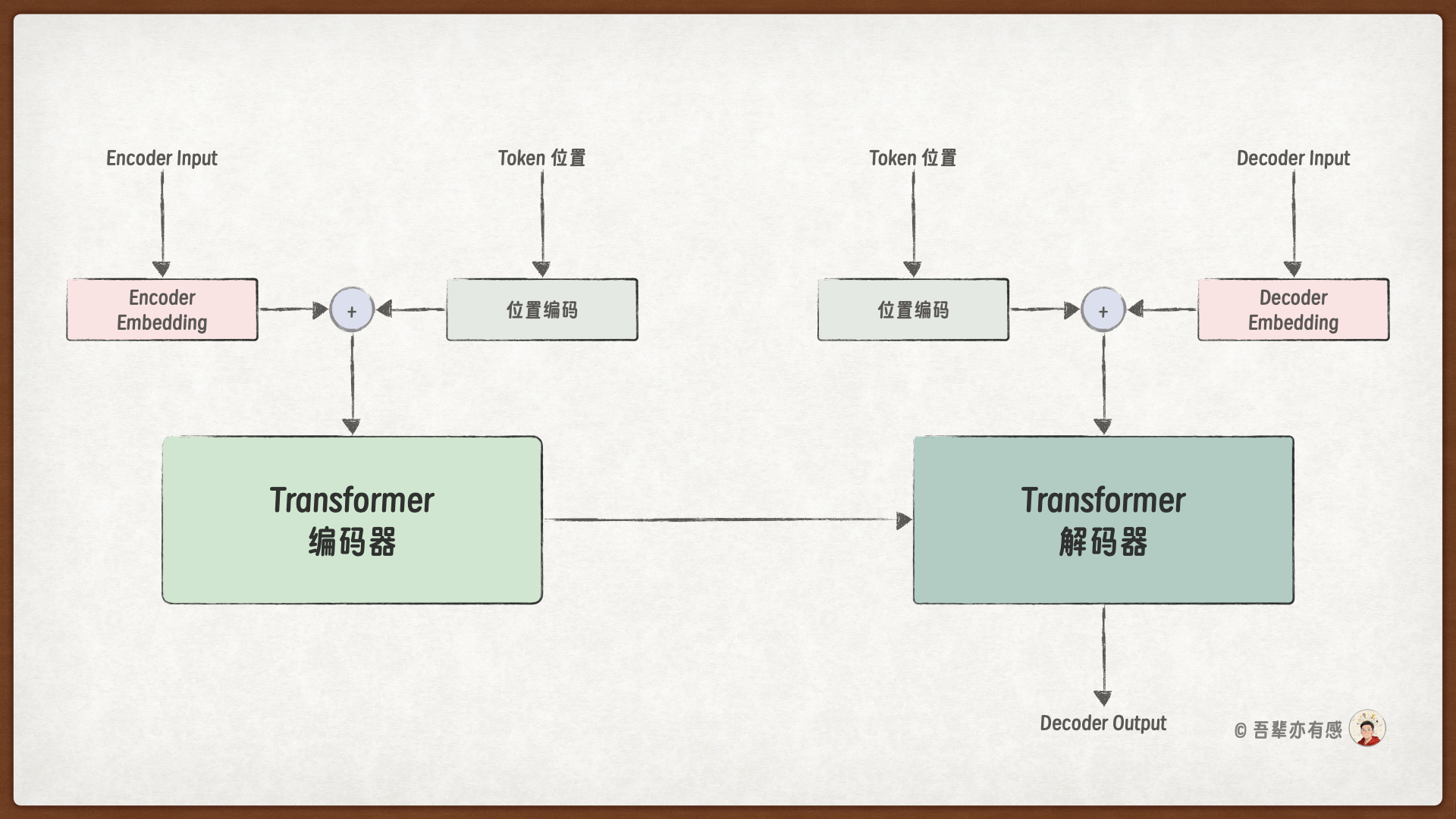
本章将详细介绍 Transformer 的输入模块。从两个架构图可以看出,Transformer 的输入模块引入了一个新的组件:位置编码。
17.2.1. 为什么要增加位置编码组件呢?#
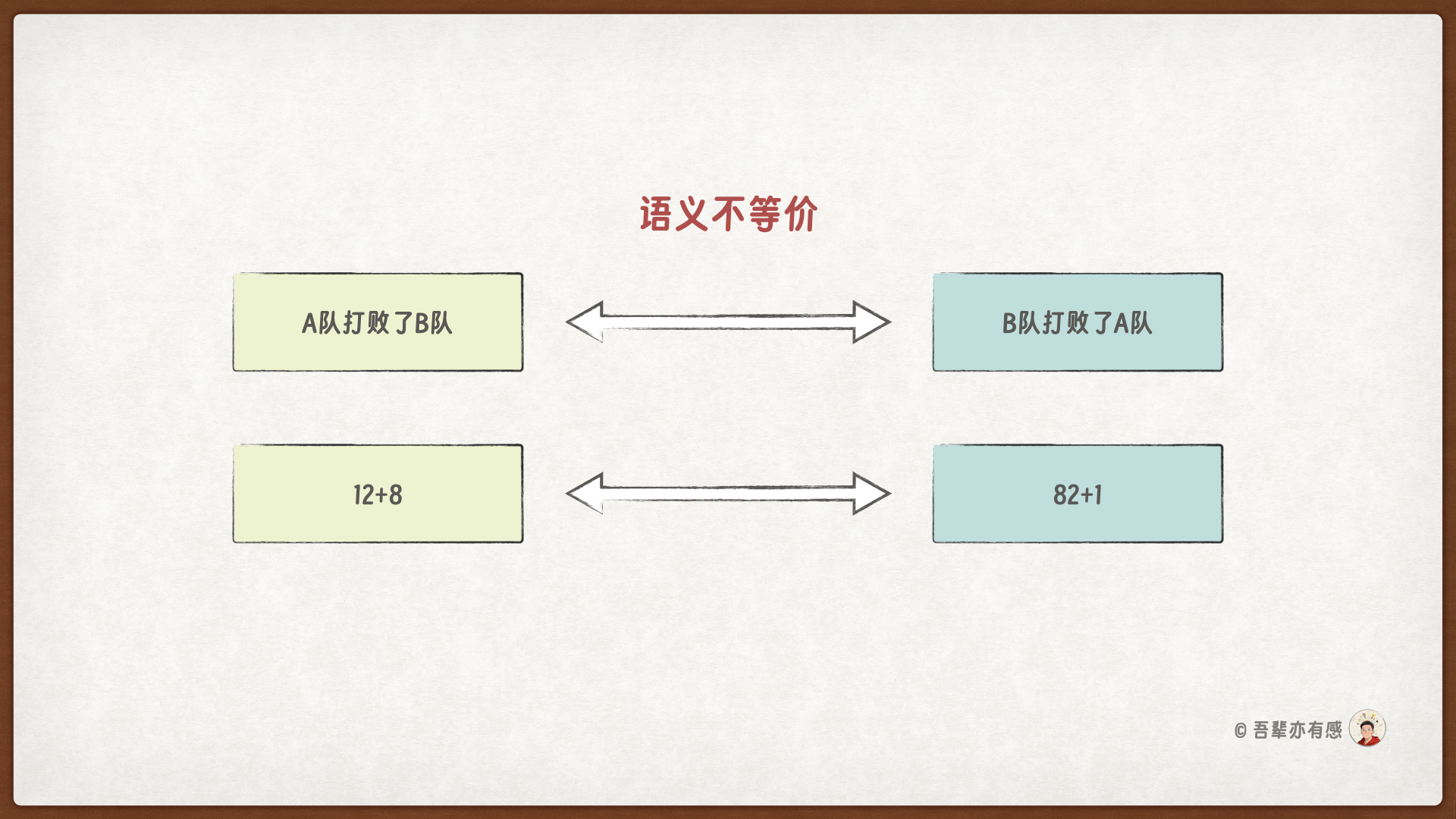
首先,位置信息对于理解自然语言至关重要。例如,相同词语构成的句子,其含义可能因词语顺序不同而迥异:
其次,在基于循环神经网络(RNN)的 Seq2Seq 模型中,由于其按时间步逐步处理输入序列的特性,模型能够在计算过程中自然地捕获词语的顺序关系。相比之下,Transformer 模型完全基于自注意力机制,放弃了循环结构,采用并行计算方式处理序列,这使得模型在计算时无法从输入数据本身感知到词语的先后顺序。因此,必须显式地向输入中添加位置信息,以弥补这一不足。
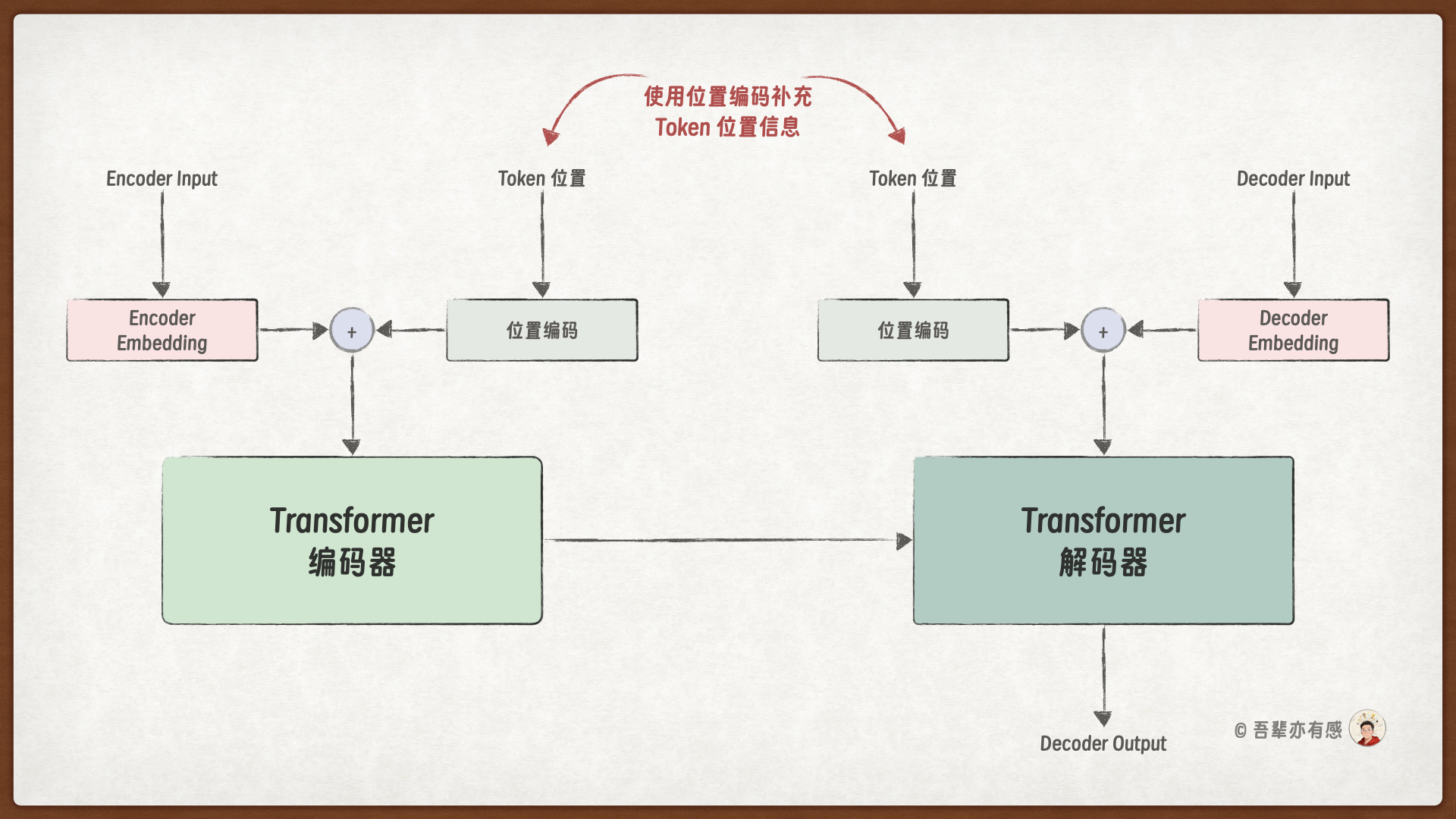
位置编码正是为了向输入序列注入位置信息而设计的组件。接下来,我们将详细介绍 Transformer 输入模块中位置编码的实现细节。
17.3. Transformer 输入模块#
17.3.1. Transformer 输入数据处理流程#
Transformer 在处理输入数据时,先使用词嵌入层将输入序列中的 Token 转换为语义向量,然后使用位置编码获取每一个位置的位置向量,最后将语义向量和位置向量相加,得到最终的输入向量。
输入模块的流程如下:
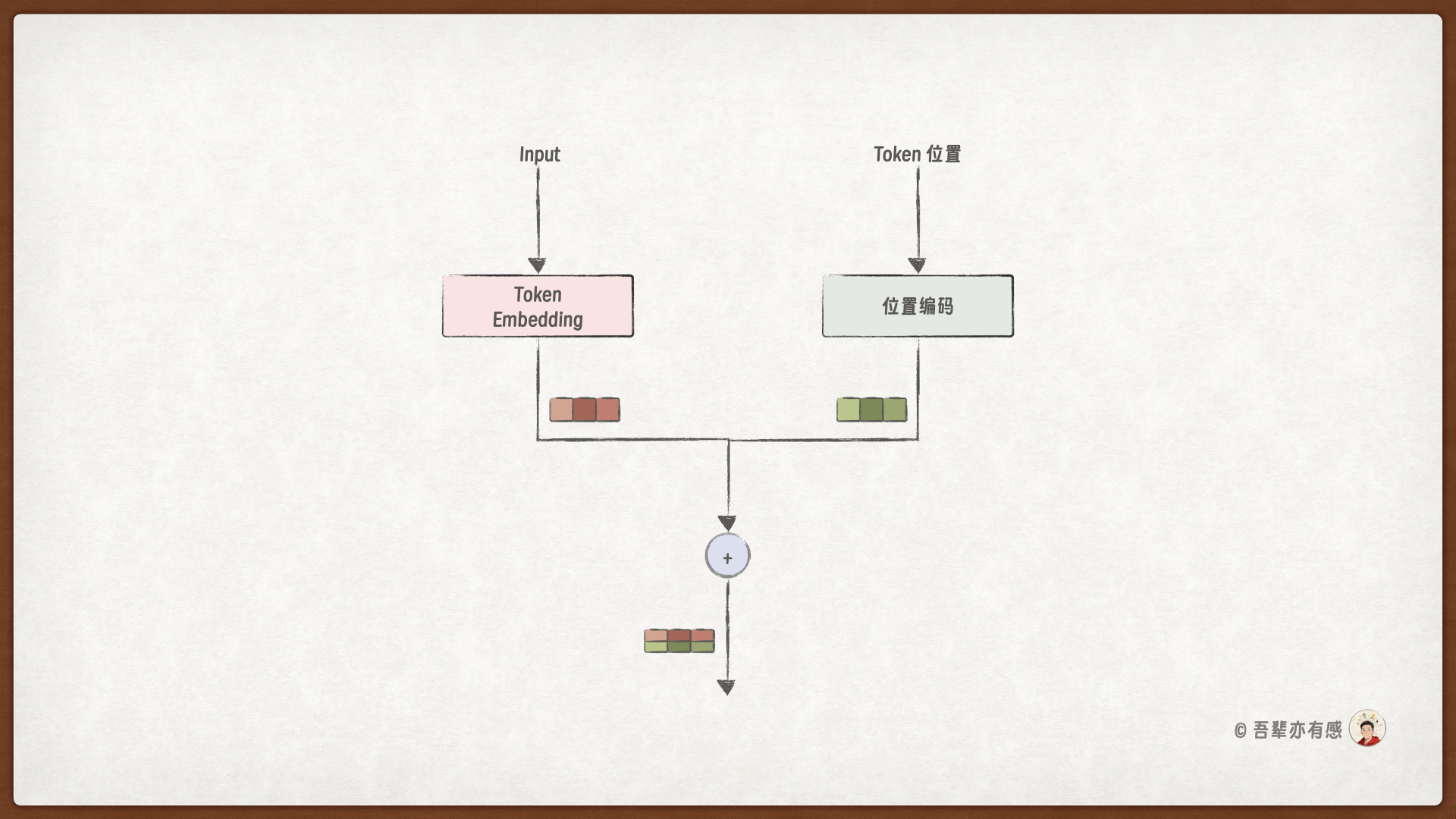
下面我们通过一个实例讲解为输入添加位置信息的具体过程。
17.3.2. 为加法算式添加位置编码#
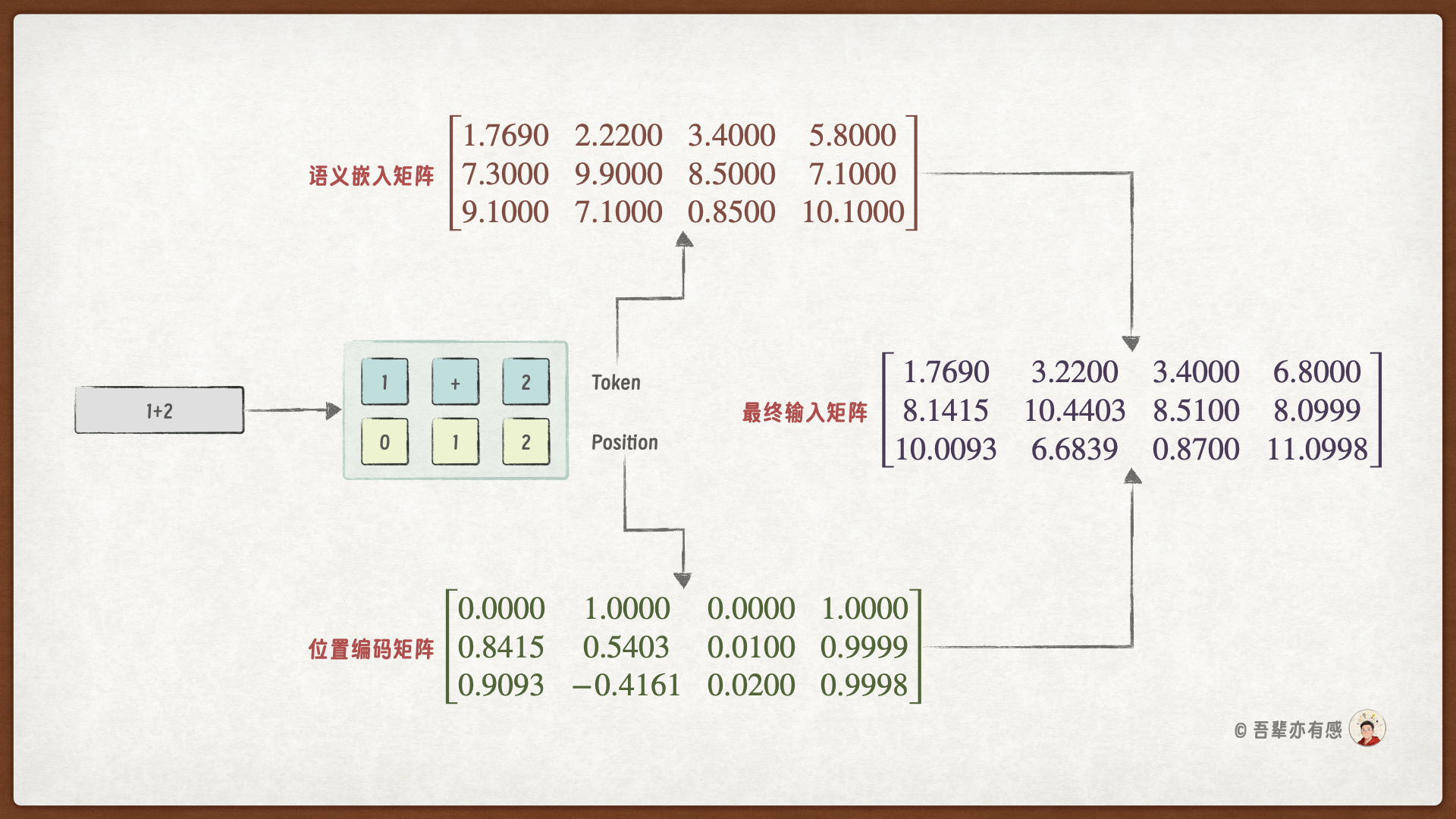
以算式 1+2 为例,首先分词器会将其分割为三个 Token:1、+、2,它们的位置索引依次为 0、1、2。
接下来,我们需要为每个 Token 计算其输入向量,该向量由 Token 的词嵌入(Embedding)与其对应的位置编码(Positional Encoding)相加得到。
步骤1:计算 1 的输入向量
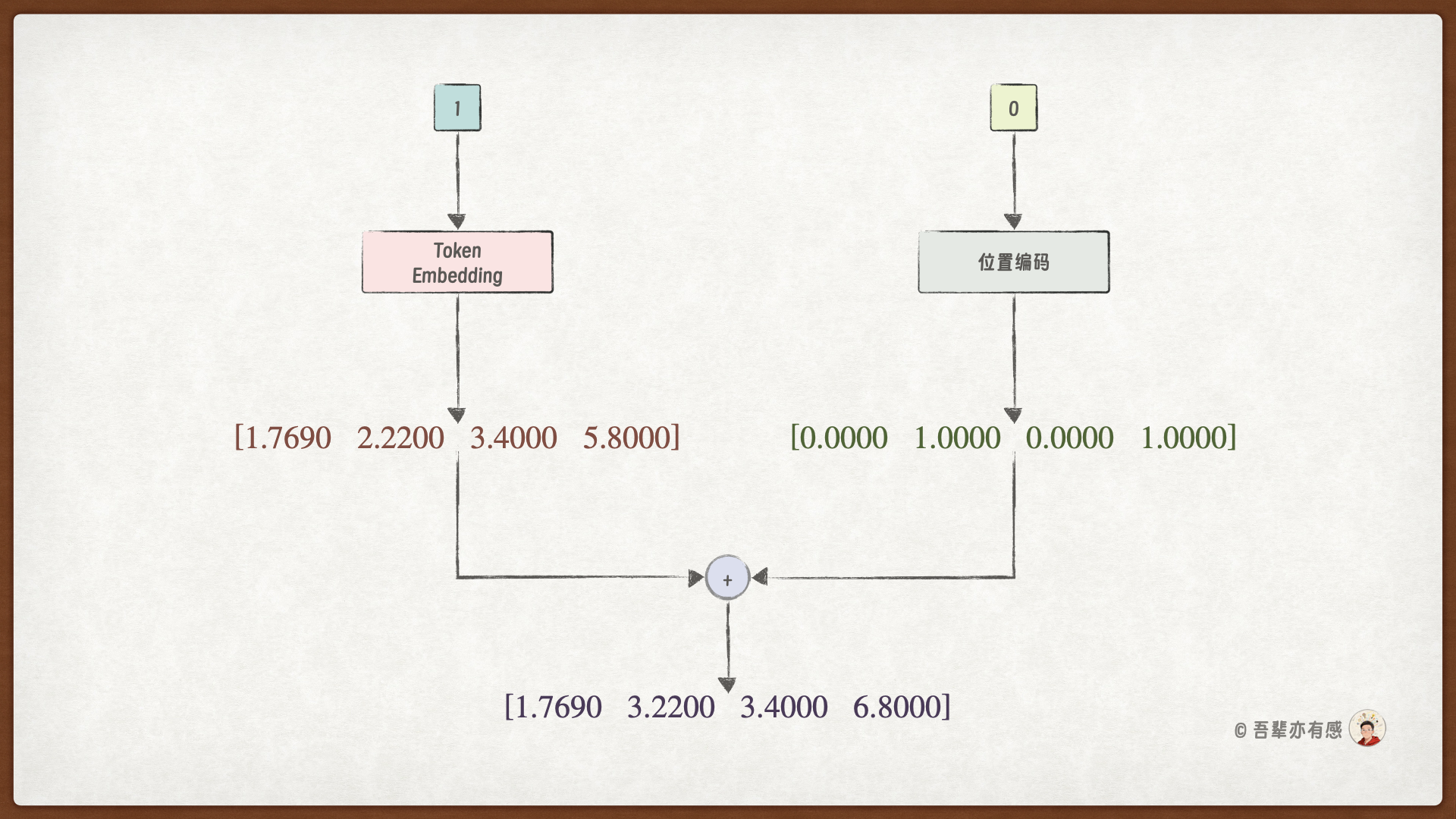
步骤2:计算 + 的输入向量
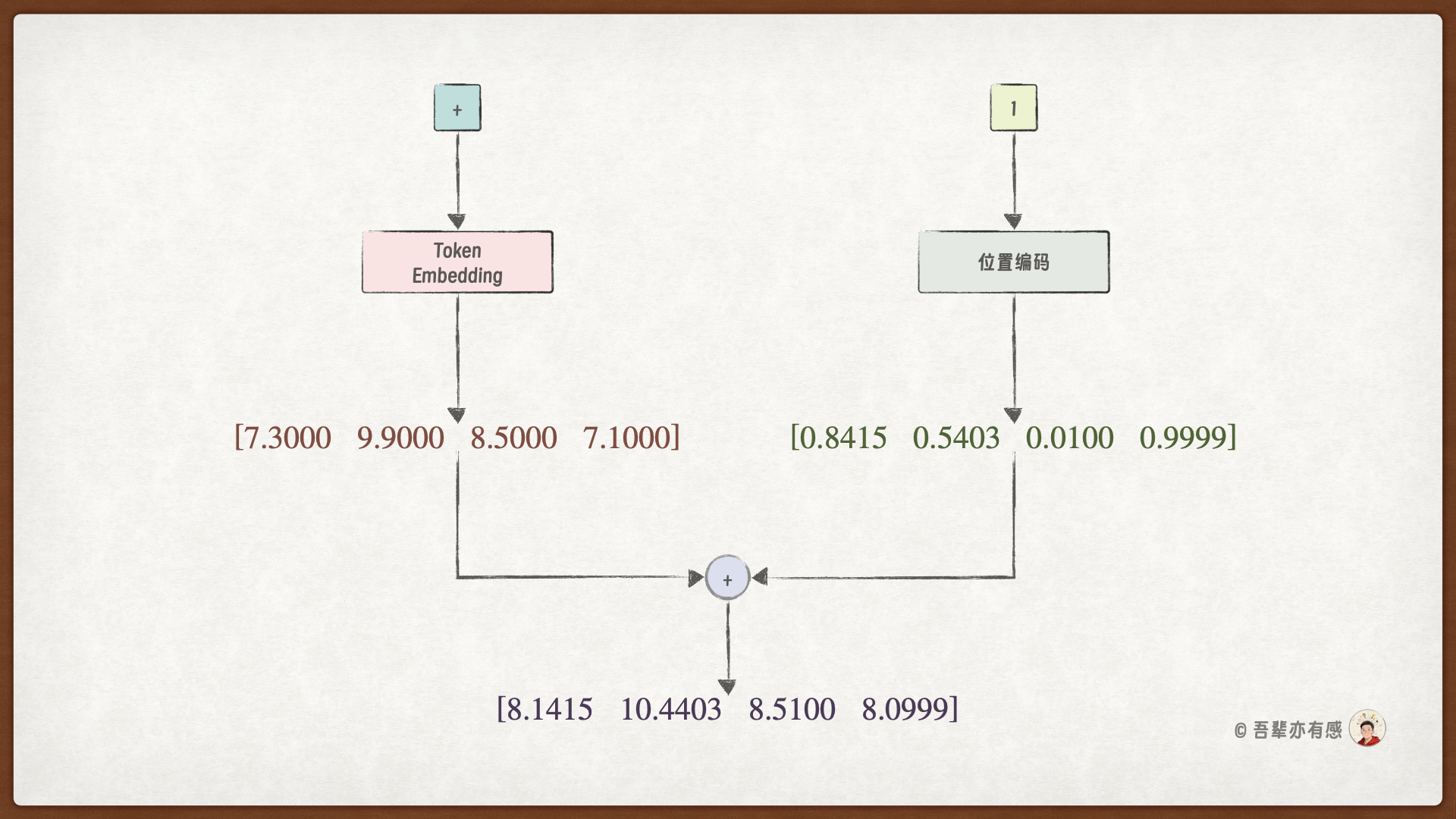
步骤3:计算 2 的输入向量
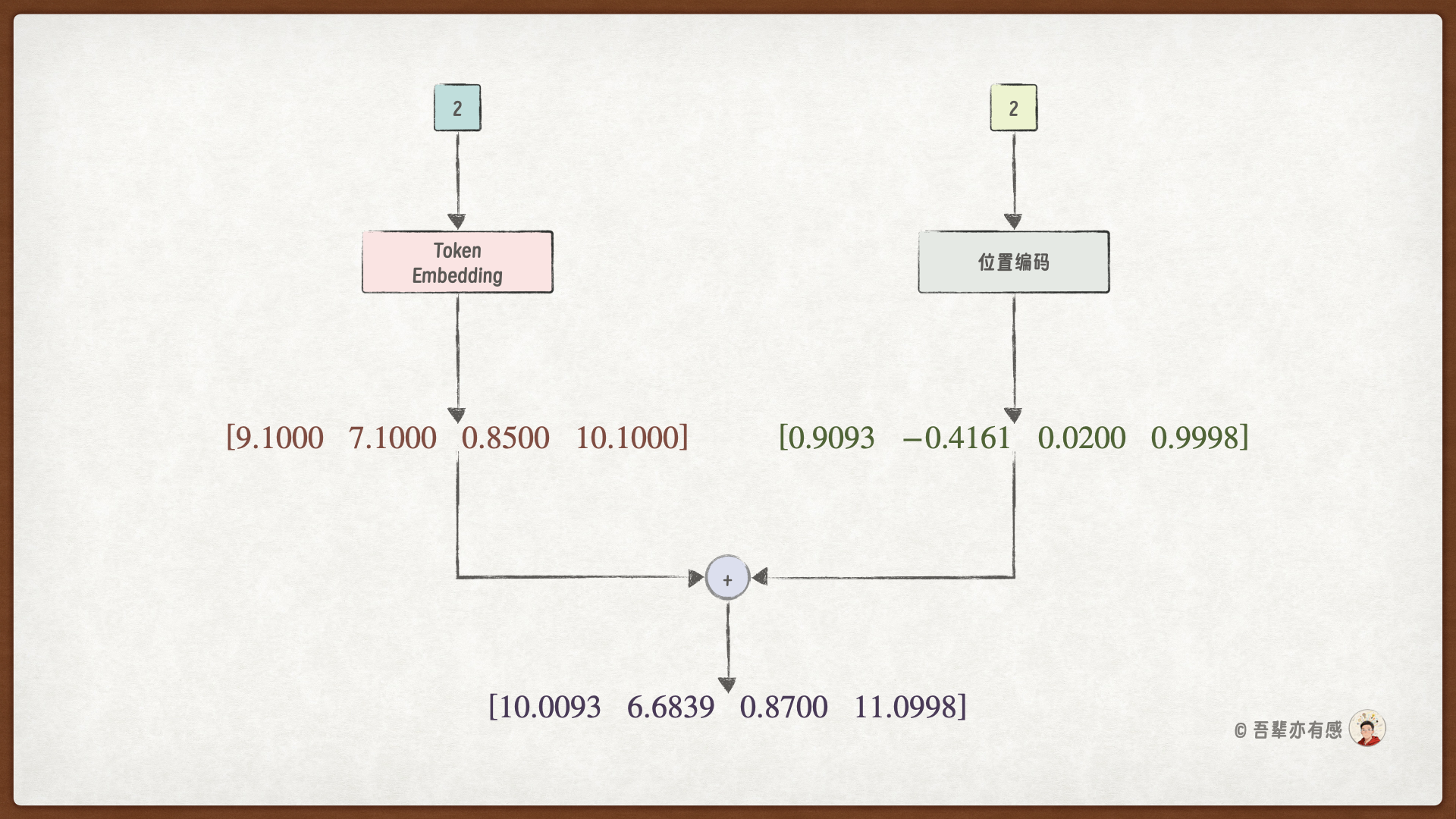
整个输入模块的处理流程如下图所示:
那么,每个位置的位置向量是如何生成的呢?
目前主流的位置信息生成方法可分为以下两类:
位置编码:通过预定义的数学函数生成位置表示,使用时直接通过查表获取指定位置的位置向量,最经典的实现来自原始 Transformer 论文中的正弦位置编码(Sinusoidal Position Encoding)。
位置嵌入:将位置信息视为可学习的参数,使用一个嵌入层在训练过程中学习得到与位置索引相关的特征向量,从而实现位置编码,类似于词嵌入(Word Embedding)。
17.4. Transformer 位置编码#
在众多位置编码方案中,原始 Transformer 提出了一种巧妙的正弦位置编码(Sinusoidal Position Encoding)。它利用不同频率的正弦和余弦函数为每个位置生成一个独一无二的标识向量,这个向量可以看作是位置的“指纹”。将该向量加到对应词的词嵌入上,模型便能够同时感知“这个词是什么”以及“它在哪个位置”。
正弦位置编码的具体公式如下:
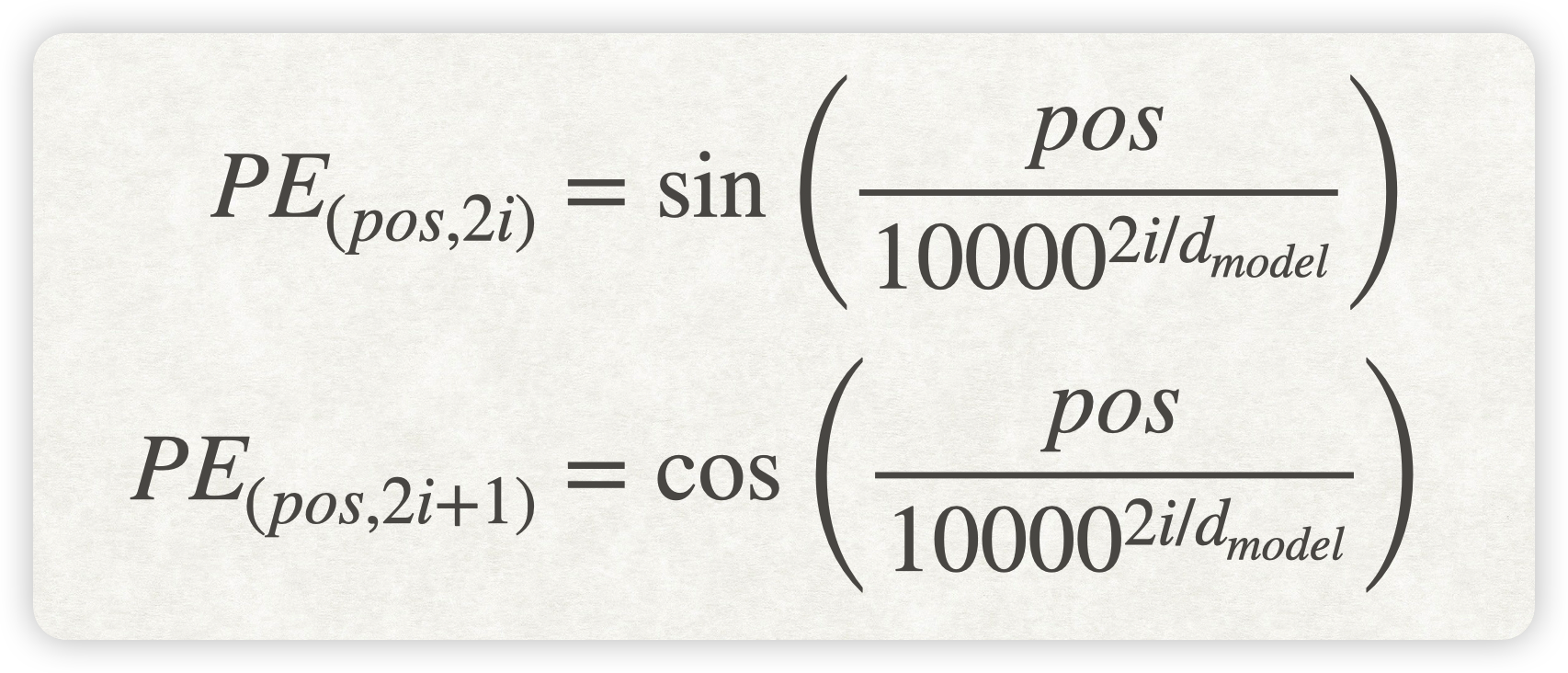
注意:公式中,\(d_{model}\) 是嵌入维度大小,\(i\) 表示维度索引,\(pos\) 表示位置索引。当维度为偶数时使用正弦函数,奇数时使用余弦函数。
仅从公式上看,正弦位置编码可能显得有些抽象。下面我们通过一个具体示例来直观理解它的运作方式。
17.4.1. Transformer 位置编码的计算实例#
依然以加法算式 1+2 为例,假设嵌入维度 \(d_{model}\) 为 4。则计算过程如下:
第
0、1维的i=0,第2、3维的i=1;第0、2偶数维使用正弦函数,第1、3奇数维使用余弦函数。代入 Transformer 位置编码公式,位置编码矩阵 P 如下(只计算前3个位置):
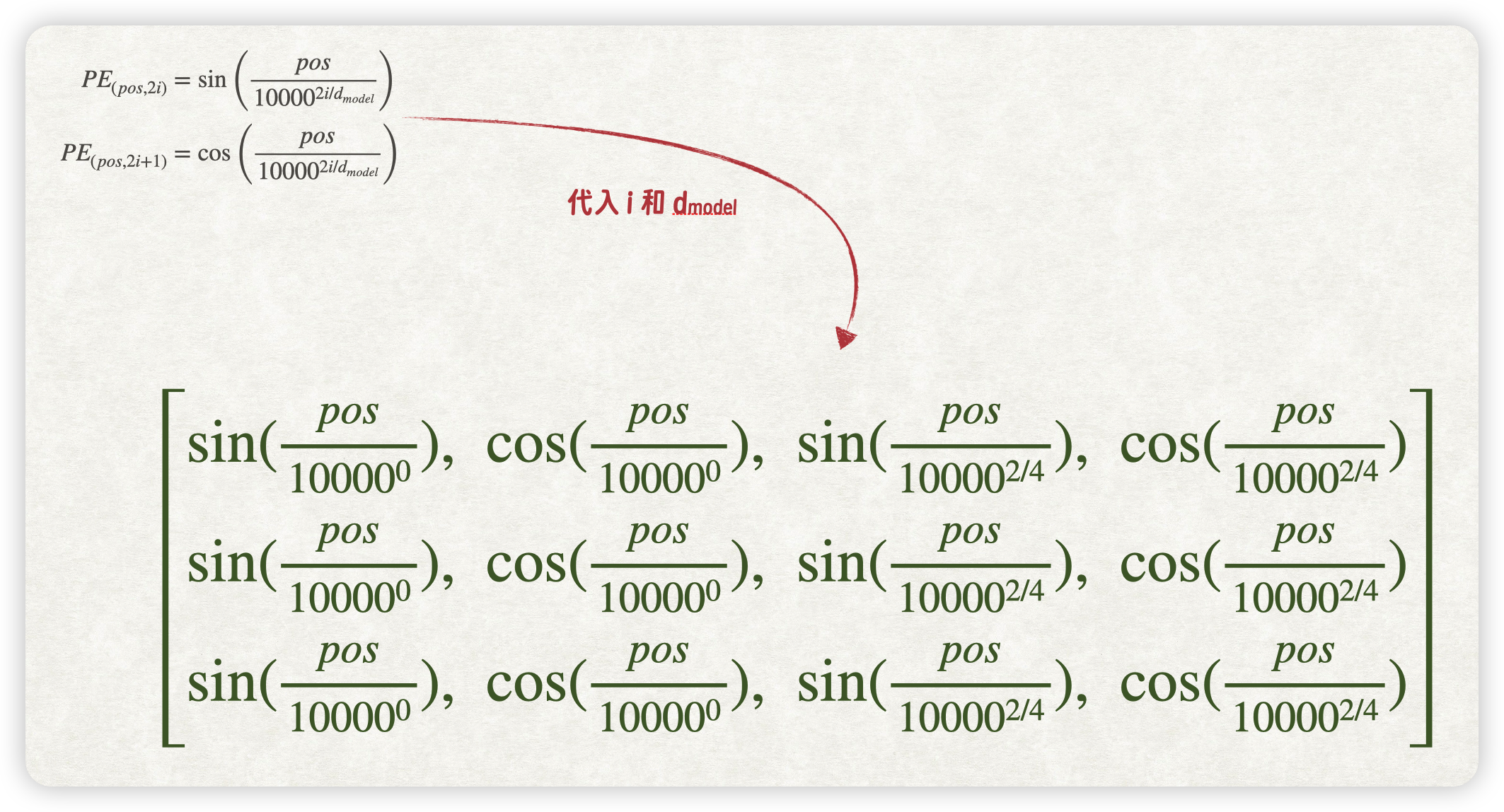
简化后位置编码矩阵 P 如下:

Token
1的位置pos=0,Token+的位置pos=1,Token2的位置pos=2。代入 pos 值,可得如下结果:
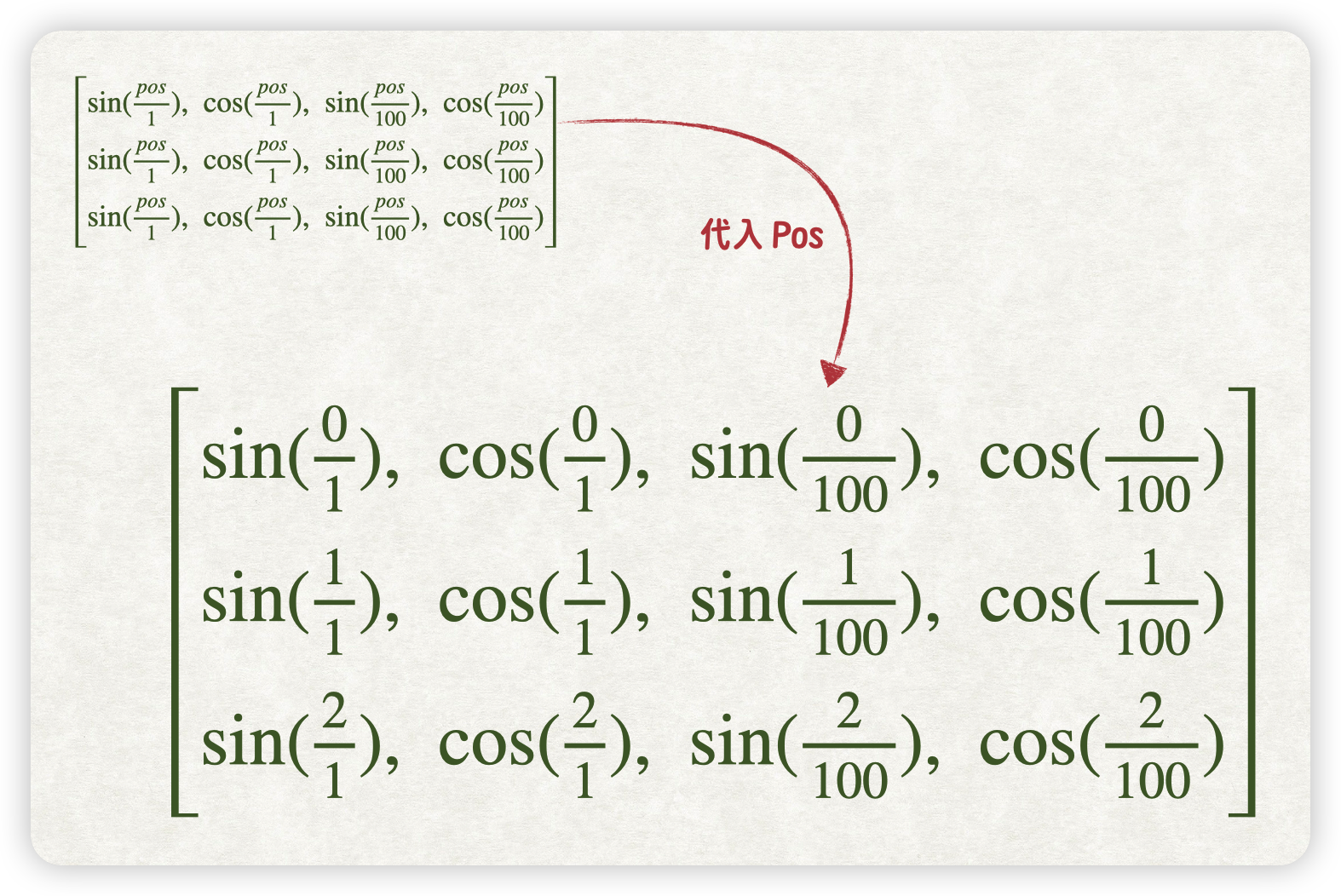
继续简化后的位置编码矩阵 P 如下所示:

计算正弦和余弦值,可得最终的位置编码矩阵 P 如下所示,其中第 1 行为位置索引为 0 的位置编码,第 2 行为位置索引为 1 的位置编码,第 3 行为位置索引为 2 的位置编码:

假设 1+2 的语义嵌入矩阵 X 为:

则算式 1+2 最终的输入矩阵为:
17.4.2. Transformer 位置编码的代码实现#
此处位置编码的实现和给定的公式不太一致,使用了对数简化计算,因为直接计算“大数的幂次”可能会导致 数值溢出 或 精度损失。通过取对数,我们可以将“指数运算”转换为“乘法运算”,从而简化计算过程。具体的推导过程未来会在附录中给出,有兴趣的同学可以自行查看。
import math
import torch
from torch import nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_len=512):
"""
位置编码类,用于给输入序列添加位置信息
参数:
d_model: 模型的隐藏维度大小
max_seq_len: 预期的最大序列长度
"""
super().__init__()
# 创建一个形状为[max_seq_len, d_model]的位置编码矩阵
pe = torch.zeros(max_seq_len, d_model)
# 生成位置索引序列,形状为[max_seq_len, 1]
position = torch.arange(0, max_seq_len, dtype=torch.float).unsqueeze(1)
# 计算位置编码中的分母项,用于缩放不同维度的位置信息
# 1、torch.arange(0, d_model, 2):生成从0到d_model-1的偶数列,例如当d_model=4时,生成[0, 2]
# 2、使用指数还原等价计算,即e^(-log(10000.0)/d_model),解决直接计算“大数的幂次”可能会导致 数值溢出 或 精度损失的问题
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
)
# 偶数列使用正弦函数计算位置编码
pe[:, 0::2] = torch.sin(position * div_term)
# 奇数列使用余弦函数计算位置编码
pe[:, 1::2] = torch.cos(position * div_term)
# 增加批次维度,形状变为[1, max_seq_len, d_model]
pe = pe.unsqueeze(0)
# register_buffer用于注册一个不属于模型参数但需要保存的状态张量
# 这样可以在模型保存和加载时自动处理这个张量
# persistent=False表示在保存模型时不将其包含在状态字典中
self.register_buffer("pe", pe, persistent=False)
def forward(self, x):
"""
前向传播函数
参数:
x: 输入张量,形状为[batch_size, seq_len, d_model]
返回:
添加了位置编码的输入张量
"""
# 将位置编码添加到输入张量中
# 仅使用与输入序列长度相等的位置编码部分
x = x + self.pe[:, : x.size(1)]
return x
17.4.3. 给输入添加位置编码#
17.4.3.1. 初始化输入#
# '1+2'的语义嵌入
X = [[1.769, 2.22, 3.4, 5.8], [7.3, 9.9, 8.5, 7.1], [9.1, 7.1, 0.85, 10.1]]
# 将列表转换为张量
X_tensor = torch.tensor(X)
# 输出张量
print(f"语义嵌入矩阵 X:\n{X_tensor}")
语义嵌入矩阵 X:
tensor([[ 1.7690, 2.2200, 3.4000, 5.8000],
[ 7.3000, 9.9000, 8.5000, 7.1000],
[ 9.1000, 7.1000, 0.8500, 10.1000]])
17.4.3.2. 创建位置编码#
# 位置编码:使用 4 维的嵌入维度生成 3 个位置的嵌入矩阵
pe = PositionalEncoding(d_model=4, max_seq_len=3)
print(f"位置编码矩阵 P:\n{pe.pe}")
位置编码矩阵 P:
tensor([[[ 0.0000, 1.0000, 0.0000, 1.0000],
[ 0.8415, 0.5403, 0.0100, 0.9999],
[ 0.9093, -0.4161, 0.0200, 0.9998]]])
我们生成的位置编码和上面使用公式推导的结果一致。
17.4.3.3. 添加位置编码#
X_with_pe = pe(X_tensor)
print(f"添加位置信息后的输入矩阵:\n{X_with_pe}")
添加位置信息后的输入矩阵:
tensor([[[ 1.7690, 3.2200, 3.4000, 6.8000],
[ 8.1415, 10.4403, 8.5100, 8.0999],
[10.0093, 6.6839, 0.8700, 11.0998]]])
最终的输入矩阵也和示例中的一致,说明我们的位置编码实现是正确的。
17.5. 本章小结#
本章围绕 Transformer 的位置编码展开,首先阐述了引入位置编码的必要性:由于 Transformer 摒弃了循环结构,采用并行计算的自注意力机制,无法从输入序列本身感知词的顺序,因此需要显式注入位置信息。接着介绍了两种主流的位置信息注入方式——基于固定函数的位置编码(如正弦位置编码)和基于可学习参数的位置嵌入。我们重点剖析了原始 Transformer 提出的正弦位置编码,其通过不同频率的正弦和余弦函数为每个位置生成唯一的标识向量,使得模型能够同时捕获词语的语义与位置信息。通过加法算式的示例,我们直观展示了位置编码如何与词嵌入结合,构成 Transformer 的最终输入。理解位置编码的工作原理,是深入掌握 Transformer 模型的基础。
17.6. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。