
24. 构造 GPT 预训练数据集#
24.1. 介绍#
上一节我们已成功实现了GPT分词器的编码与解码方法。本节将在此基础上,构建用于GPT模型预训练的数据集。
在构建数据集之前,我们首先需要明确GPT模型在预训练阶段的核心任务及其对数据的具体要求,然后依据这些要求对原始文本进行处理,最终形成可供模型训练使用的数据集。
24.2. 预训练阶段的自回归任务#
在GPT的预训练阶段,核心任务是自回归语言建模。自回归(Autoregressive)是 GPT 预训练的灵魂,它决定了模型如何“阅读”和“生成”信息,是 GPT 模型理解语言能力的关键。
从本质上讲,自回归任务类似于一个“填空”游戏:给定一段文本的前文,模型需要预测下一个最可能出现的词(Token)。该过程是单向的——模型只能依据已出现的上文信息进行预测,而不能“偷看”未来的内容。通俗来说,就是“根据上文预测下一个词”。
种训练模式采用的是自监督学习。这意味着我们无需为海量的训练数据手动标注标签,而是可以直接利用数据自身的结构,将句子或文档中的“下一个词”作为模型预测的目标标签。由于标签可以“动态”生成,因此能够充分利用互联网上规模庞大、多样化的无标注文本数据来训练大语言模型。
通过在海量文本上反复执行这一预测任务,模型逐渐掌握了语言的统计规律、语法结构以及常见的知识关联,从而为其后续的生成与理解能力奠定基础。
24.3. 自回归任务的数据需求#
基于上述任务,预训练数据的核心需求就变得非常明确:我们需要将原始的长文本,改造为一个个输入-目标对(input-target pairs)。
具体而言:
输入(Input):是一段连续的文本序列。
目标(Target):是紧接在这段输入序列之后的下一个词元(Next Token)。
因此,我们的核心工作就是遍历整个语料库,将每一段文本都切割成这种“上文”与“下文”的配对关系,为模型提供明确的学习目标。
24.4. 自回归任务的具体流程#
GPT 的预训练是一个无监督(或自监督)学习过程,不需要人工标注的标签,文本本身既是输入也是标签。假设我们有一句话:动 手 学 大 语 言 模 型,下面我们看看 GPT 模型是如何根据这一句话进行预训练的。
GPT 模型的任务是根据前 k 个词预测第 k+1 个词。
输入:
动 手 学 大 语 言 模标签:
手 学 大 语 言 模 型(模型需要预测的下一个词)
更具体地说,对于序列中的每一个位置,模型都在学习:
给定
动,预测手给定
动 手,预测学给定
动 手 学,预测大给定
动 手 学 大,预测语给定
动 手 学 大 语,预测言给定
动 手 学 大 语 言,预测模给定
动 手 学 大 语 言 模,预测型给定
动 手 学 大 语 言 模 型,预测[EOS]
从上面的过程中我们可以看到,将完整的词元序列整体向右移动一个位置,就能构造出输入序列和对应的目标序列。那么如何从一个长序列中提取出多个这样的输入-标签对呢?这就需要使用滑动窗口(Sliding Window)了。
24.5. 使用滑动窗口构造数据#
在 GPT 的预训练阶段,滑动窗口是一种用于处理长文本数据的方法。滑动窗口的作用就是将超长文本切分成多个符合长度限制的、可能重叠的短序列,从而生成大量训练样本。
以句子 “动手学大语言模型是很有趣的一本书……” 为例,假设模型最大长度为 4,步长设为 2,文本 token 序列为:[动,手,学,大,语,言,模,型,是,很,有,趣,的,一,本,书,…]
使用滑动窗口构建预训练数据集:
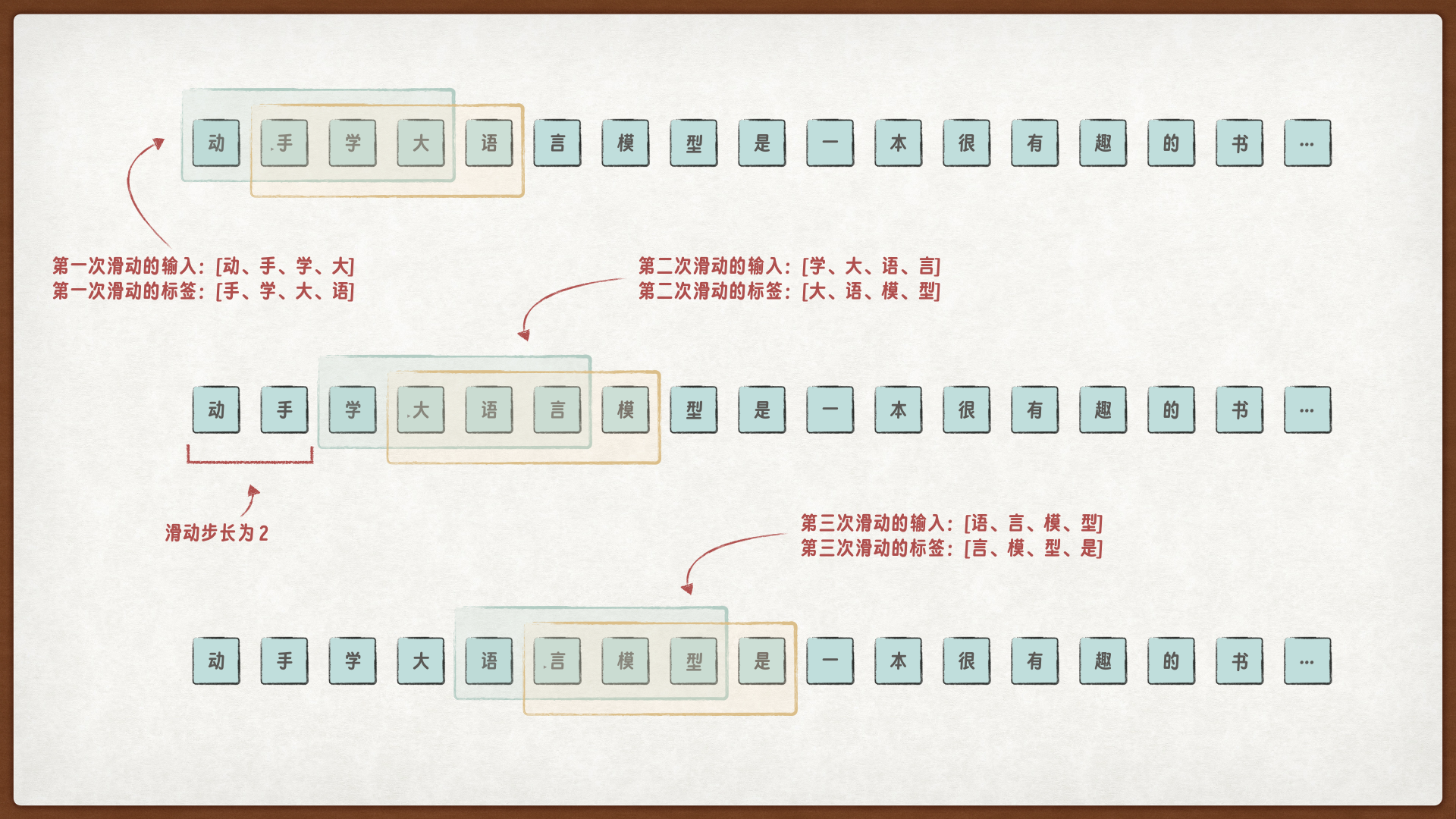
通过滑动窗口生成的训练样本如下:
窗口1(位置 0-3):输入
动 手 学 大,标签手 学 大 语窗口2(位置 2-5):输入
学 大 语 言,标签大 语 言 模窗口3(位置 4-7):输入
语 言 模 型,标签言 模 型 是…
每个窗口内的序列都会按照自回归任务的要求构造输入-标签对(即每个 token 预测下一个 token)。需要注意的是,为了保持因果性,窗口内的 token 仍然使用带掩码的注意力,保证预测时只能看到左侧的 token。
接下来,我们将动手构建 GPT 预训练数据集。在开始之前,请确保已安装 dsxllm 库,并确认运行环境已准备就绪。
24.6. 环境配置#
24.6.1. 安装依赖#
!pip install dsxllm -i https://pypi.org/simple
Requirement already satisfied: dsxllm in /Users/kong/opt/anaconda3/envs/dsx-ai/lib/python3.12/site-packages (0.1.0)
24.6.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
24.7. 数据集下载#
24.8. 加载预训练语料文件#
24.8.1. 定义加载训练语料文件的方法#
def load_text_data(file_path):
"""
加载文本数据文件
"""
text_data = ""
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
return text_data
24.8.2. 加载预训练语料并划分训练集/验证集#
def load_text_data_and_split(filepath, train_ratio=0.9):
"""
加载文本数据文件并进行训练/验证集划分
"""
text_data = load_text_data(filepath)
# Train/Validation 划分比例
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
return train_data, val_data
24.9. 自定义 GPT 预训练数据集#
24.9.1. 预训练数据集的代码实现#
import torch
from torch.utils.data import Dataset
class GPTDataset(Dataset):
"""
使用滑动窗口构造GPT预训练数据集
参数:
txt (str): 输入文本字符串
tokenizer: 分词器对象,用于将文本转换为token ID
max_length (int): 每个样本的最大长度(输入序列长度)
stride (int): 滑动窗口的步长,控制样本之间的重叠程度
"""
def __init__(self, txt, tokenizer, max_length, stride):
# 初始化一个列表来保存所有样本(input_ids, target_ids)对
self.samples = []
# 将整个文本编码为token ID序列
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
# 使用滑动窗口将文本分割为长度为最大长度的重叠序列
for i in range(0, len(token_ids) - max_length, stride):
# 当前窗口的token作为输入数据
input_ids = token_ids[i : i + max_length]
# 向右偏移一位的token作为监督数据
target_ids = token_ids[i + 1 : i + max_length + 1]
# 转换为张量并添加到样本列表中
self.samples.append((torch.tensor(input_ids), torch.tensor(target_ids)))
def __len__(self):
# 返回数据集中样本的总数
return len(self.samples)
def __getitem__(self, idx):
# 获取单个样本,形式为(input_ids, target_ids)
return self.samples[idx]
24.9.2. 创建预训练数据集实例#
import tiktoken
from dsxllm.util import print_table
from dsxllm.gpt.tokenizer import token_ids_to_text
# 1️⃣ 加载文本数据并进行训练集和验证集的划分
data_filepath = "./dataset/llm_corpus.txt"
train_data, val_data = load_text_data_and_split(data_filepath)
# 2️⃣ 初始化分词器
tokenizer = tiktoken.get_encoding("gpt2")
# 3️⃣ 创建数据集
dataset = GPTDataset(train_data, tokenizer, max_length=4, stride=2)
# 4️⃣ 查看数据集示例
input_ids, target_ids = dataset[0]
print_table(
"数据集示例",
field_names=["Information", "Value"],
data=[
["输入序列长度", input_ids.shape[0]], # 显示输入序列的长度
["输入序列", token_ids_to_text(input_ids, tokenizer)], # 显示输入序列的文本
["输入序列 IDs", input_ids], # 显示输入序列的ID
["目标序列长度", target_ids.shape[0]], # 显示目标序列的长度
["目标序列", token_ids_to_text(target_ids, tokenizer)], # 显示目标序列的文本
["目标序列 IDs", target_ids], # 显示目标序列的ID
],
)
数据集示例:
+--------------+----------------------------------+
| Information | Value |
+--------------+----------------------------------+
| 输入序列长度 | 4 |
| 输入序列 | I HAD always |
| 输入序列 IDs | tensor([ 40, 367, 2885, 1464]) |
| 目标序列长度 | 4 |
| 目标序列 | HAD always thought |
| 目标序列 IDs | tensor([ 367, 2885, 1464, 1807]) |
+--------------+----------------------------------+
24.10. 构造 GPT 预训练数据集模组#
24.10.1. GPT 预训练数据集模组的代码实现#
import lightning as L
from torch.utils.data import DataLoader
class GPTDataModule(L.LightningDataModule):
def __init__(self, batch_size, tokenizer, train_data_file, max_length, stride, train_ratio=0.9):
super().__init__()
# 初始化数据模块的属性
self.batch_size = batch_size # 设置批次大小
self.tokenizer = tokenizer # 文本转换器
self.train_data_file = train_data_file # 训练数据文件路径
self.max_length = max_length # 最大序列长度
self.stride = stride # 滑动窗口步长
self.train_ratio = train_ratio # 训练集比例
# 初始化数据集
self.train_dataset: GPTDataset # 训练数据集
self.val_dataset: GPTDataset # 评估数据集
self.test_dataset: GPTDataset # 测试数据集
def prepare_data(self):
"""
准备数据的方法
用于下载数据集或进行一次性数据预处理操作
"""
pass
def setup(self, stage=None):
"""
设置数据集的方法
"""
# 1️⃣ 加载文本数据并进行训练集和验证集的划分
train_data, val_data = load_text_data_and_split(self.train_data_file, self.train_ratio)
# 2️⃣ 初始化训练数据集、评估集和测试集
self.train_dataset = GPTDataset(train_data, tokenizer, max_length=self.max_length, stride=self.stride)
self.val_dataset = GPTDataset(val_data, tokenizer, max_length=self.max_length, stride=self.stride)
self.test_dataset = self.val_dataset
def train_dataloader(self):
"""
返回训练数据加载器
Returns:
DataLoader: 训练数据的DataLoader对象
"""
return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
"""
返回验证数据加载器
Returns:
DataLoader: 验证数据的DataLoader对象
"""
return DataLoader(self.val_dataset, batch_size=self.batch_size)
def test_dataloader(self):
"""
返回测试数据加载器
Returns:
DataLoader: 测试数据的DataLoader对象
"""
return DataLoader(self.test_dataset, batch_size=self.batch_size)
24.10.2. 创建 GPT 预训练数据集模组的实例#
import tiktoken
# 1️⃣ 加载文本数据并进行训练集和验证集的划分
data_filepath = "./dataset/llm_corpus.txt"
# 2️⃣ 初始化分词器
tokenizer = tiktoken.get_encoding("gpt2")
# 3️⃣ 初始化数据模块
gpt_data_module = GPTDataModule(
batch_size=2,
tokenizer=tokenizer,
train_data_file=data_filepath,
max_length=4,
stride=2,
)
# 4️⃣ 准备数据
gpt_data_module.setup()
# 5️⃣ 打印一个批次的数据
print("打印一个批次的数据:")
for batch in gpt_data_module.train_dataloader():
input_ids, target_ids = batch # 获取输入和目标token ID序列
print("input_ids:", input_ids.shape) # 打印输入序列的形状
print("target_ids:", target_ids.shape) # 打印目标序列的形状
break
打印一个批次的数据:
input_ids: torch.Size([2, 4])
target_ids: torch.Size([2, 4])
24.11. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。