
30. 构建完整的 GPT 模型#
30.1. 介绍#
前面我们已经实现了 GPT 模型中的所有核心组件,本小节将继续使用它们构建完整的 GPT 模型。
30.2. 环境配置#
30.3. 安装依赖#
!pip install --upgrade dsxllm
30.3.1. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
30.4. GPT 模型架构#
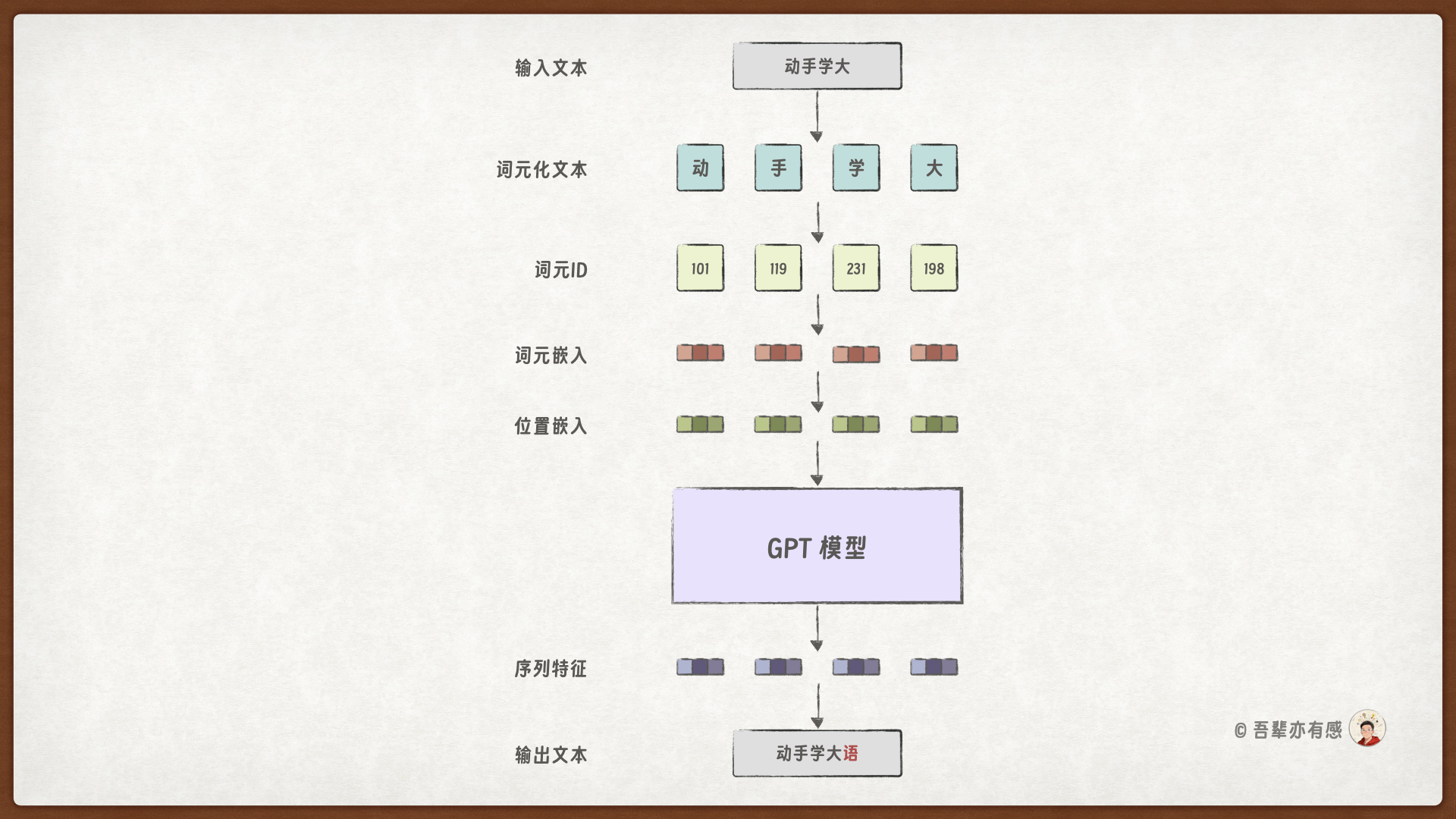
在动手写代码之前,我们重新温习一下 GPT 模型的结构和计算的流程。
GPT 模型的总体结构:
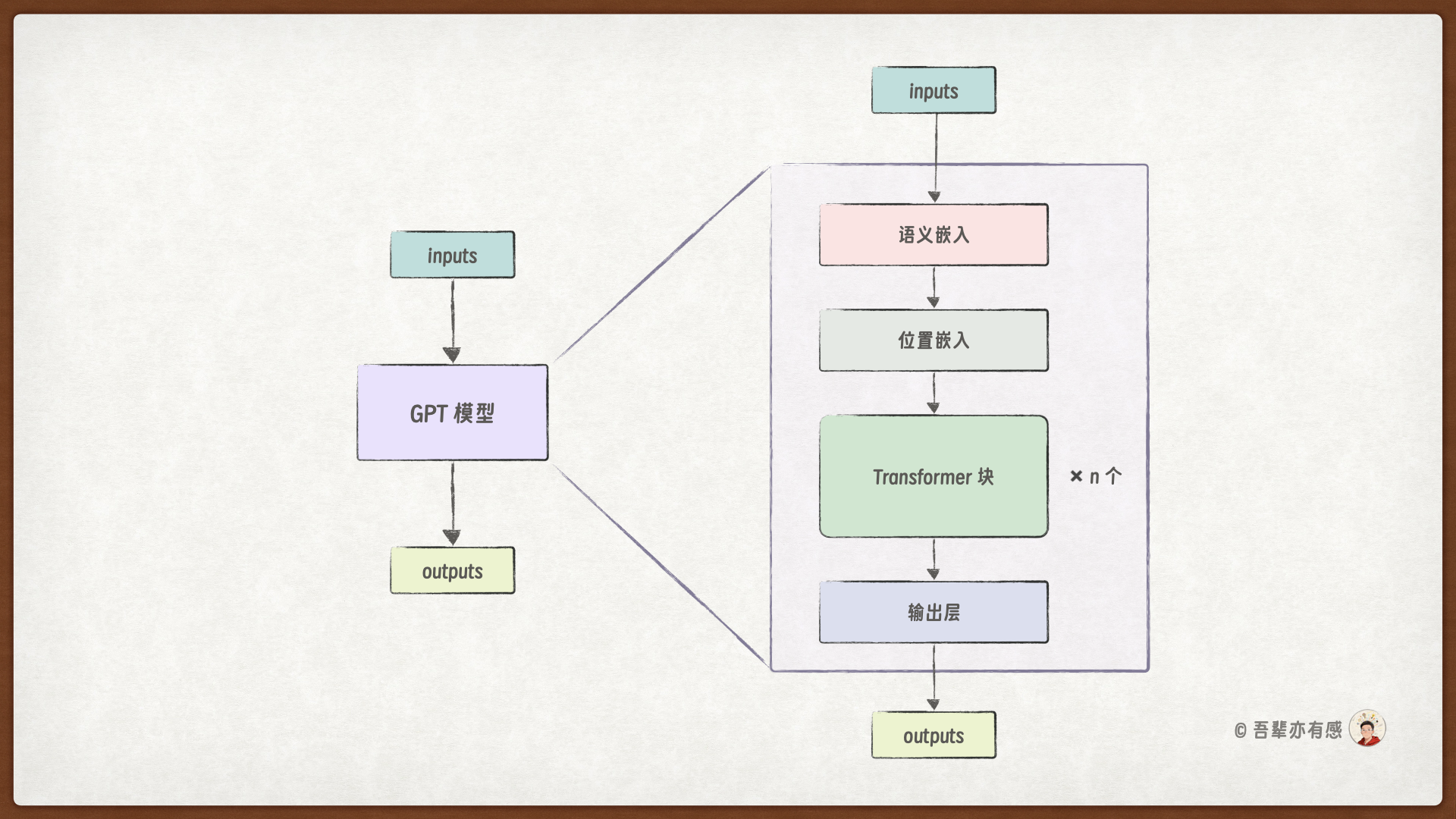
使用GPT 模型计算的流程:
30.5. GPT 模型的代码实现#
由于 GPT 模型需要配置的参数较多,我们在初始化模型时,将这些参数封装在一个配置字典 cfg 中,方便统一管理。在下面的代码中有以下几点需要注意:
在
__init__方法中,我们为了防止过拟合添加了 Dropout 层,为了训练的稳定性在输出层之前又添加了一个 LayerNorm 层。我们使用
torch.nn.Sequential创建了几个相互堆叠的 Transfomer 块,在forward计算时,会顺序执行这些 Transformer 块。另外还添加了用于记录训练和验证过程中的损失的列表和方便展示模型结构的示例输入
example_input_array。
import lightning as L
import torch
from dsxllm.gpt.layer import TransformerBlock, LayerNorm
class GPTModel(L.LightningModule):
"""
GPT 语言模型,基于 Transformer 解码器架构。
模型结构:
- Token Embedding:将 token ID 映射为 d_model 维向量
- Position Embedding:为每个位置添加可学习的位置编码
- Dropout:对嵌入向量进行正则化
- Transformer 块堆叠:多个 TransformerBlock
- 最终层归一化
- 输出线性层(LM Head):将 d_model 映射回词汇表大小
Args:
cfg (dict): 配置字典,必须包含以下键:
- vocab_size: 词汇表大小
- d_model: 嵌入维度
- seq_len: 最大上下文长度
- drop_rate: Dropout 概率
- n_layers: Transformer 块的数量
"""
def __init__(self, cfg):
super().__init__()
# Token 嵌入层
self.token_embedding = torch.nn.Embedding(cfg["vocab_size"], cfg["d_model"])
# 位置嵌入层
self.position_embedding = torch.nn.Embedding(cfg["seq_len"], cfg["d_model"])
# 嵌入后的 Dropout
self.embedding_dropout = torch.nn.Dropout(cfg["drop_rate"])
# Transformer 块堆叠
self.transformer_blocks = torch.nn.Sequential(
*[
TransformerBlock(
d_model=cfg["d_model"],
seq_len=cfg["seq_len"],
n_heads=cfg["n_heads"],
drop_rate=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"],
)
for _ in range(cfg["n_layers"])
]
)
# 最终层归一化
self.final_layer_norm = LayerNorm(cfg["d_model"])
# 输出层(语言模型头),无偏置
self.lm_head = torch.nn.Linear(cfg["d_model"], cfg["vocab_size"], bias=False)
# 用于记录训练和验证过程中的损失
self.train_step_losses = [] # 每个 step 的损失
self.train_epoch_losses = [] # 每个 epoch 的平均损失
self.val_step_losses = [] # 每个 step 的验证损失
self.val_epoch_losses = [] # 每个 epoch 的平均验证损失
# 示例输入
self.example_input_array = torch.randint(
0, cfg["vocab_size"], (2, cfg["seq_len"])
)
def forward(self, input_ids):
"""
前向传播,计算下一个 token 的 logits。
Args:
input_ids (torch.Tensor): 输入 token ID 序列,形状为 (batch_size, seq_len)
Returns:
torch.Tensor: 预测 logits,形状为 (batch_size, seq_len, vocab_size)
"""
batch_size, seq_len = input_ids.shape
device = input_ids.device
# Token 嵌入
token_embeds = self.token_embedding(input_ids) # (batch, seq_len, d_model)
# 位置嵌入(生成位置索引 [0, 1, ..., seq_len-1])
position_ids = torch.arange(seq_len, device=device)
position_embeds = self.position_embedding(position_ids) # (seq_len, d_model)
# 将 token 嵌入和位置嵌入相加,得到最终的输入表示,形状为 (batch, seq_len, d_model)
hidden_states = token_embeds + position_embeds
# 应用 Dropout
hidden_states = self.embedding_dropout(hidden_states)
# 通过所有 Transformer 块
hidden_states = self.transformer_blocks(hidden_states)
# 最终层归一化
hidden_states = self.final_layer_norm(hidden_states)
# 通过语言模型头得到 logits,形状为 (batch, seq_len, vocab_size)
logits = self.lm_head(hidden_states)
return logits
def training_step(self, batch, batch_idx):
pass
def on_train_epoch_end(self):
pass
def validation_step(self, batch, batch_idx):
pass
def on_validation_epoch_end(self):
pass
def configure_optimizers(self):
pass
def clear_loss_history(self):
"""清空所有缓存的损失列表,释放内存。"""
self.train_step_losses.clear()
self.train_epoch_losses.clear()
self.val_step_losses.clear()
self.val_epoch_losses.clear()
30.6. GPT 模型的详细信息#
# 导入PyTorch Lightning的模型摘要工具,用于查看模型结构和参数信息
from lightning.pytorch.utilities.model_summary import ModelSummary
# 定义GPT模型的配置参数(对应124M参数版本的GPT)
GPT_CONFIG_124M = {
"vocab_size": 50257, # 词汇表大小,即模型可以表示的不同token的数量
"seq_len": 256, # 上下文长度(原为1024,此处缩短为256),决定模型一次处理的最大序列长度
"d_model": 768, # 嵌入维度(embedding dimension),每个token被映射到的向量维度
"n_heads": 12, # 注意力头数量(number of attention heads),用于多头注意力机制
"n_layers": 12, # 层数,Transformer块的数量
"drop_rate": 0.1, # Dropout率,用于防止过拟合的概率值
"qkv_bias": False, # 查询-键-值偏置(query-key-value bias),是否在注意力计算中使用偏置项
}
# 根据定义的配置创建GPT模型实例
model = GPTModel(GPT_CONFIG_124M)
# 创建模型摘要对象,max_depth=-1表示显示完整的模型层次结构
summary = ModelSummary(model, max_depth=2)
# 打印模型摘要信息
print(summary)
| Name | Type | Params | Mode | FLOPs | In sizes | Out sizes
---------------------------------------------------------------------------------------------------------------
0 | token_embedding | Embedding | 38.6 M | train | 0 | [2, 256] | [2, 256, 768]
1 | position_embedding | Embedding | 196 K | train | 0 | [256] | [256, 768]
2 | embedding_dropout | Dropout | 0 | train | 0 | [2, 256, 768] | [2, 256, 768]
3 | transformer_blocks | Sequential | 113 M | train | 120 B | [2, 256, 768] | [2, 256, 768]
4 | transformer_blocks.0 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
5 | transformer_blocks.1 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
6 | transformer_blocks.2 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
7 | transformer_blocks.3 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
8 | transformer_blocks.4 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
9 | transformer_blocks.5 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
10 | transformer_blocks.6 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
11 | transformer_blocks.7 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
12 | transformer_blocks.8 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
13 | transformer_blocks.9 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
14 | transformer_blocks.10 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
15 | transformer_blocks.11 | TransformerBlock | 9.4 M | train | 10.1 B | [2, 256, 768] | [2, 256, 768]
16 | final_layer_norm | LayerNorm | 1.5 K | train | 0 | [2, 256, 768] | [2, 256, 768]
17 | lm_head | Linear | 38.6 M | train | 39.5 B | [2, 256, 768] | [2, 256, 50257]
---------------------------------------------------------------------------------------------------------------
190 M Trainable params
0 Non-trainable params
190 M Total params
762.741 Total estimated model params size (MB)
186 Modules in train mode
0 Modules in eval mode
160 B Total Flops
30.7. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。