
18. 实现 Transformer Encoder 组件#
18.1. Transformer Encoder 概览#
在 Transformer 架构中,编码器(Encoder)的核心作用是将输入序列转换为一系列富含上下文信息的连续向量表示。简单来说,编码器负责“理解”输入内容,提取融合了整个序列信息的隐藏特征,并为后续的解码器(Decoder)提供高质量的语义表示。
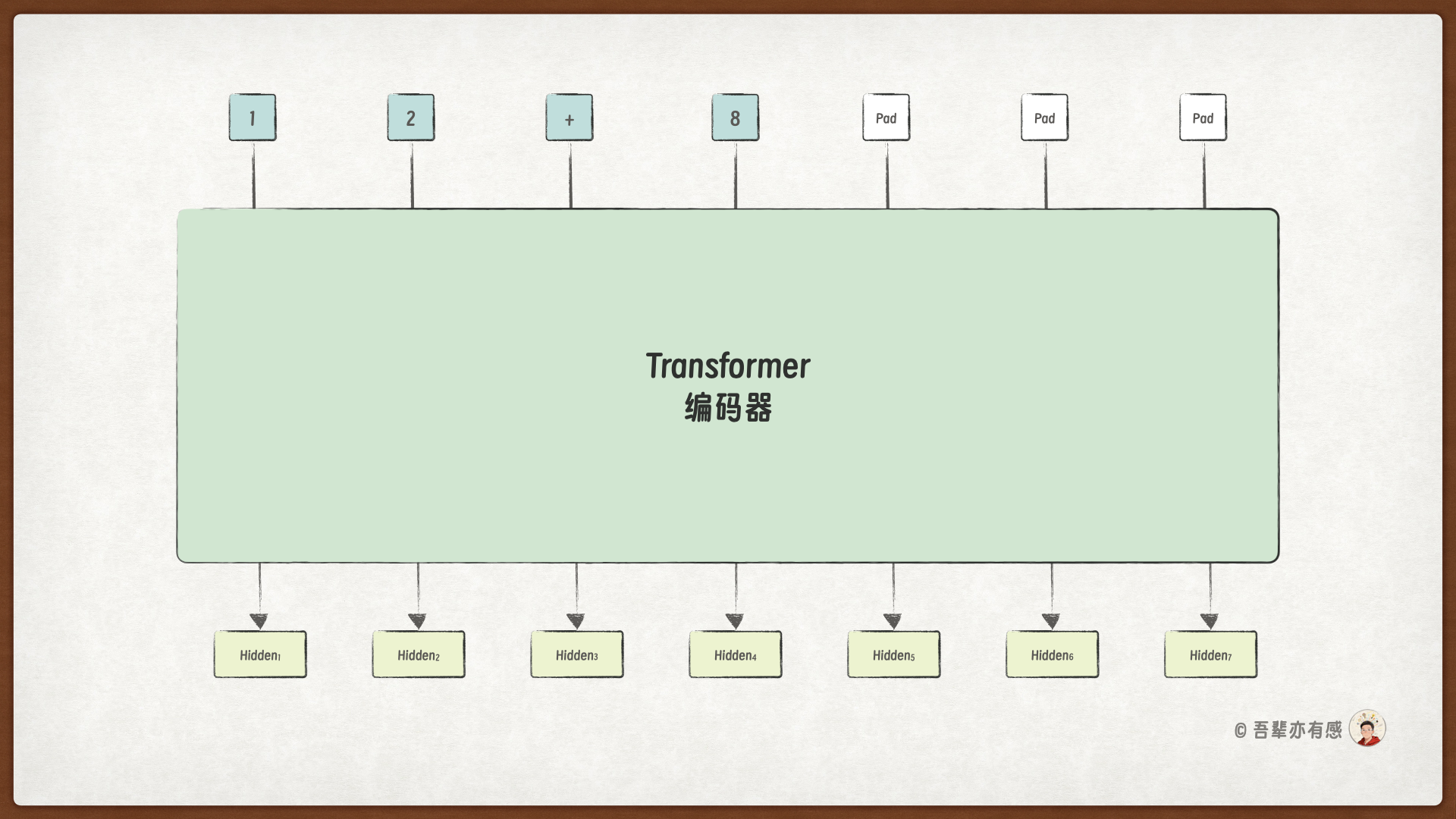
Transformer 编码器通常由多个结构相同的编码器层(Encoder Layer)堆叠而成。这种分层结构使得模型能够逐层提炼信息:
底层更倾向于捕捉表面的词法特征(如词形、词性);
中层开始关注句法结构和局部上下文信息;
高层则能够提炼出抽象的语义概念和整体的主题信息。
通过这种逐层抽象的过程,编码器输出的表示越来越富含语义信息,也越来越适合各类下游任务。
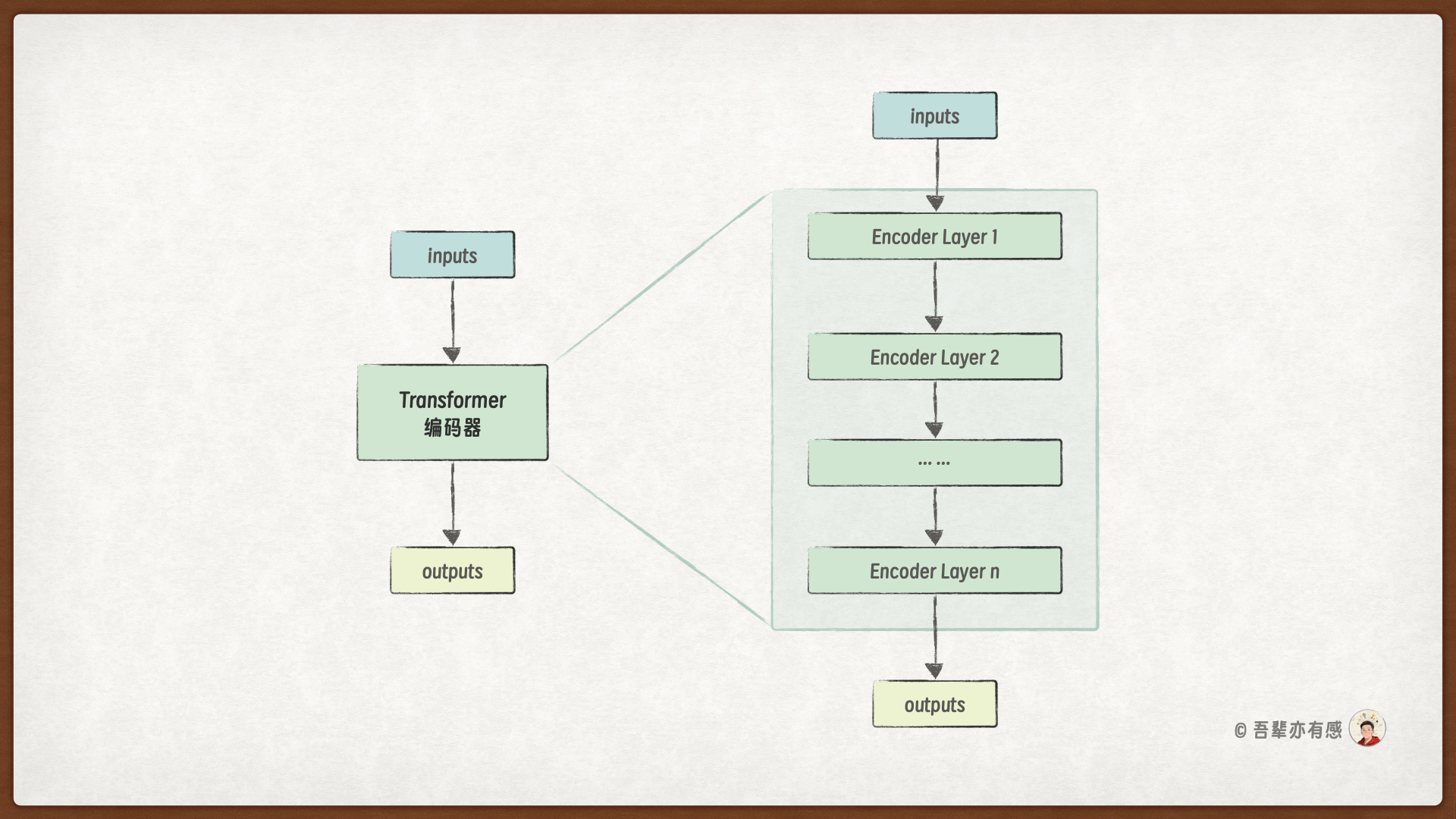
每一个编码器层(Encoder Layer)均由两个核心子层组成——多头自注意力层和前馈神经网络层,并且每个子层都配备了残差连接和层归一化。具体的层结构如下图所示:
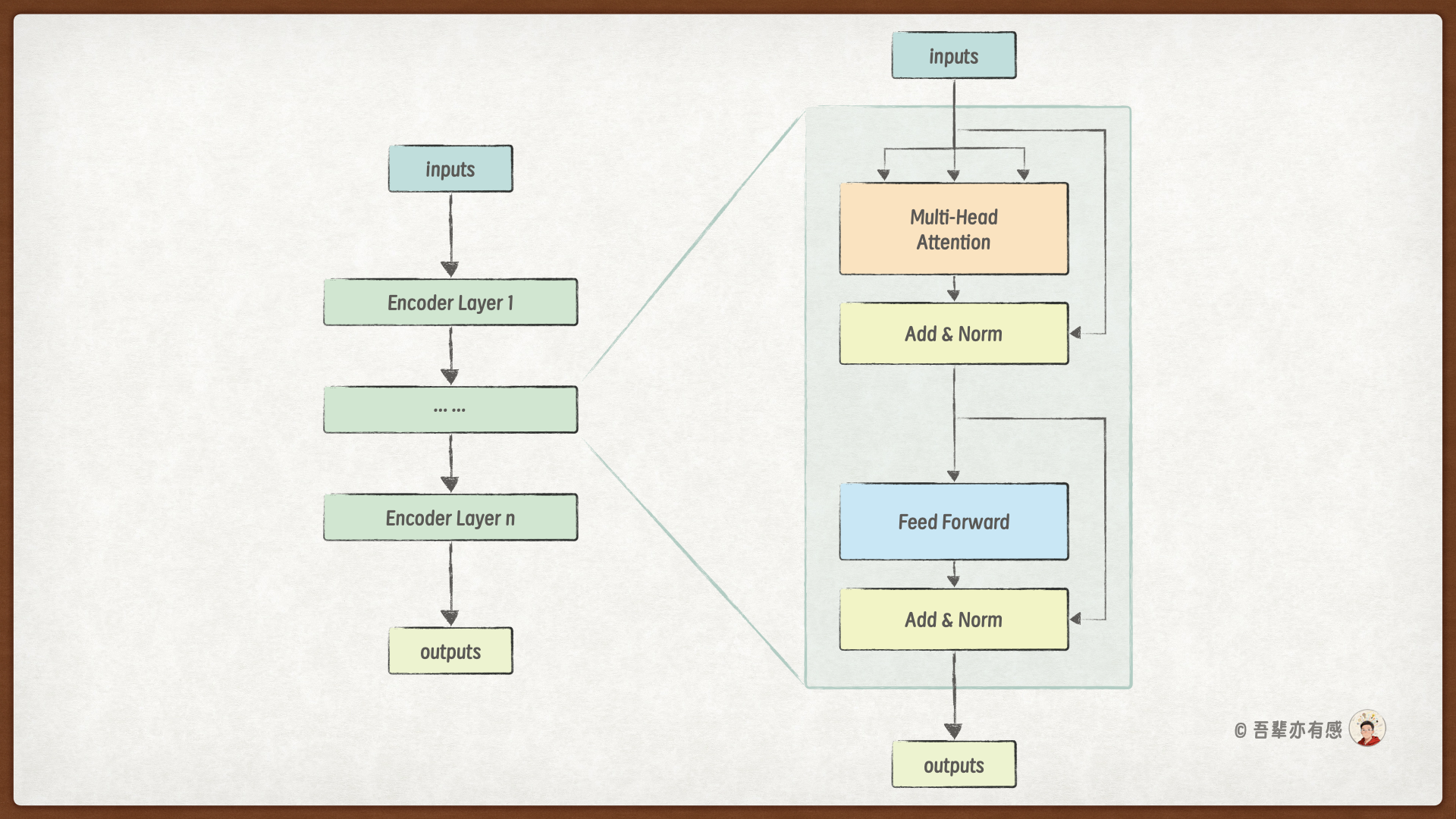
各组件的作用如下:
自注意力层:允许输入序列中的每个位置关注序列中的所有其他位置,动态捕捉序列内部的依赖关系和结构信息。
前馈神经网络层:通过非线性变换、维度扩展与压缩,对注意力层的输出进行进一步的特征提取和抽象,增强模型的表达能力。它与自注意力机制形成互补,共同提升模型性能。
残差连接:将子层的输入直接加到输出上,为梯度提供一条“捷径”,有效缓解深层网络中的梯度消失/梯度爆炸问题,使得训练深层Transformer成为可能。
层归一化:对每个子层的输出进行归一化处理,稳定参数的分布和尺度,加快模型收敛速度,提升训练过程的稳定性。
接下来,我们将进入实战环节,亲手搭建 Transformer 编码器中的各个核心组件。
18.2. 自注意力层#
在 Transformer 的编码器中,自注意力层是最核心的组件之一。它的目标是让模型在处理每个词时,能够动态地关注输入序列中所有其他词,从而捕捉全局依赖关系。下面我们一步步拆解它的工作原理。
自注意力层的底层原理是注意力机制,通过计算输入序列中每个位置与所有其他位置之间的权重,来决定每个位置所关注的信息来源。
假设我们有一个句子:“那只动物没过马路,因为它太累了”。当模型处理“它”这个词时,需要知道“它”指的是“动物”还是“马路”?自注意力机制会计算“它”与句子中所有词的关联度(注意力权重),然后根据这些权重将其他词的信息融合到“它”的表示中。如果“动物”的权重最高,那么“它”的最终向量就会富含“动物”的特征,从而解决指代问题。
Transformer 中使用的是多头自注意力层,为方便理解注意力的核心原理,此处使用单头自注意力层替代。
18.2.1. 自注意力机制的计算过程#
在循环神经网络(RNN)中,每个 Token 需要依赖上一时刻的隐藏状态来逐步传递和融合上下文信息。那么,自注意力层又是如何让每个 Token 获取全局上下文,并生成新的表示向量的呢?其核心计算过程如下图所示:
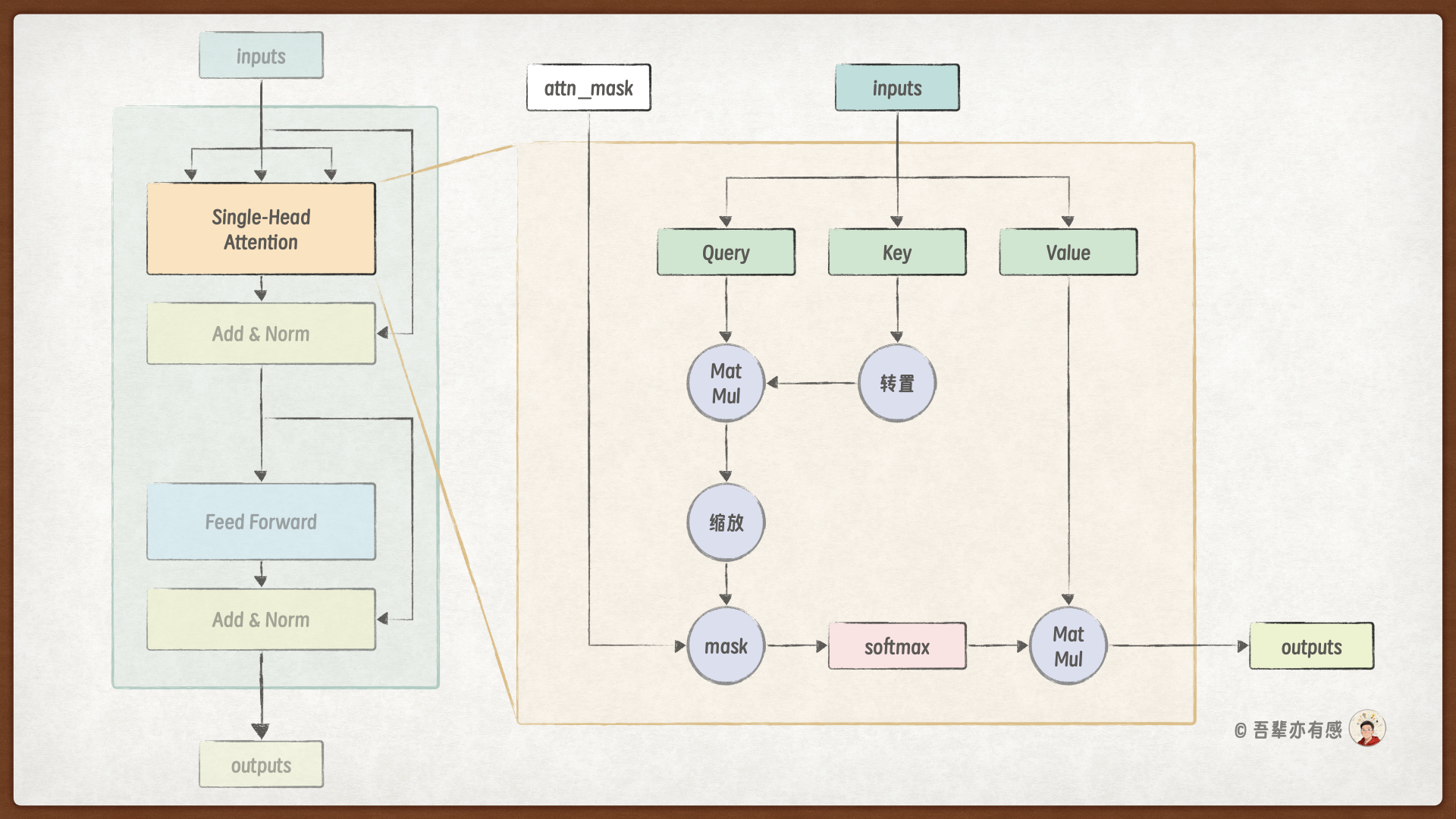
我们可以借助一个直观的比喻来理解这一过程:将每个 Token 视为持有三张功能各异的“牌”——Query 牌、Key 牌和 Value 牌。
Query 牌:代表当前 Token “要什么”,它就像一个提问,向其他 Token 征询相关的信息。
Key 牌:代表当前 Token “是什么”,相当于一个标签或索引,供其他 Token 的 Query 来匹配。
Value 牌:代表当前 Token “有什么”,是 Token 自身携带的实际信息内容。
当为某个 Token 计算其在下一层的表示向量时,将经历以下四个步骤:
匹配求相似:该 Token 首先亮出自己的 Query 牌,与序列中所有 Token 的 Key 牌进行一一匹配(通常通过点积运算),计算出它与每个 Token 的关联程度。这个关联程度就是注意力分数。
屏蔽无关项:为了防止填充的无效 Token 干扰计算结果,需要将对应位置的注意力分数替换为一个极小的负数(如负无穷),使其在后续归一化中权重趋近于零。
归一化得权重:将经过屏蔽的注意力分数输入 Softmax 函数进行归一化,使所有位置的分数之和为 1。此时得到的便是注意力权重,它反映了当前 Token 应该给予其他每个 Token 多大的关注度。
聚合信息:根据这些注意力权重,从每个 Token 的 Value 牌中提取相应比例的信息,并将所有信息整合起来(即加权求和)。最终得到的向量,就是融合了全局上下文信息的、当前 Token 的新表示。
那么,Token 的 Query、Key、Value 又是如何生成的呢?Transformer 采用了简洁而有效的做法:通过三个独立的线性变换层,从输入的 Token 向量中分别映射出 Query、Key 和 Value。这三个线性变换的权重矩阵会在模型训练过程中自动学习优化,从而使生成的 Query、Key、Value 能够更好地适配注意力机制的需求。
18.2.2. 自注意力机制的代码实现#
在自注意力机制的计算中,我们可以看到一个关键步骤:对 Key 矩阵进行转置。这一步是为了通过矩阵乘法,一次性并行计算出所有位置之间的相似度。
使用线性变换得到的 Query 和 Key 矩阵的形状都是 [序列长度,特征维度] 。我们的目标是计算每一个 Query 和每一个 Key 的点积,最终得到一个 [序列长度,序列长度] 的注意力分数矩阵。
根据矩阵乘法的规则(左矩阵的列数必须等于右矩阵的行数),我们需要把 Key 矩阵的行列互换(即转置),将其形状从 [序列长度,特征维度] 变为 [特征维度,序列长度] 。
这样,计算过程就变成了:[序列长度,特征维度]×[特征维度,序列长度]=[序列长度,序列长度]
从而高效地得到了注意力分数矩阵。
缩放注意力机制
Transformer 自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再用 \(\sqrt{d_k}\) 对结果进行缩放。这样做的目的主要是获得稳定的梯度。
因为当输入信息的维度 d 比较高,会导致 softmax 函数接近饱和区,梯度会比较小。因此,缩放点积模型可以较好地解决这一问题。
import torch
from torch import nn
import numpy as np
from dsxllm.util import print_red
class SingleHeadAttention(nn.Module):
def __init__(self, d_model):
super(SingleHeadAttention, self).__init__()
self.hidden_size = d_model
# Query的变换矩阵
self.q_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
# Key的变换矩阵
self.k_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
# Value的变换矩阵
self.v_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
def forward(self, q_input, k_input, v_input, attn_mask):
print_red("【步骤1】计算query、key和value向量\n")
query = self.q_proj(q_input)
key = self.k_proj(k_input)
value = self.v_proj(v_input)
# 计算注意力分数:计算 query 和 key的转置 的点积,然后除以根号 hidden_size 进行缩放
scores = torch.matmul(query, key.transpose(-1, -2)) / np.sqrt(self.hidden_size)
print_red("【步骤 2】计算注意力分数,掩码前的scores:")
print(scores, "\n")
if attn_mask is not None:
scores.masked_fill_(attn_mask == 0, -1e9)
print_red("【步骤 2-1】掩码后的scores:")
print(scores, "\n")
# 计算注意力权重:使用softmax函数,对每个样本的注意力分数进行归一化
attention_weights = nn.functional.softmax(scores, dim=-1)
print_red("【步骤 3】计算注意力权重,注意力权重:")
print(attention_weights, "\n")
# 计算加权和
output = torch.matmul(attention_weights, value)
print_red("【步骤 4】 计算加权和:")
print(output, "\n")
return output, attention_weights
18.2.3. 自注意力机制的应用实例#
from dsxllm.util import print_red
# 1️⃣ 创建输入数据
batch_size = 2
seq_len = 3
d_model = 4
# 创建输入张量
x = torch.randn(batch_size, seq_len, d_model)
print_red("原始输入:")
print(x, "\n")
# 2️⃣ 设置数据的填充情况:第一条数据未填充,第二条数据的最后一个位置是填充的。
# 创建注意力掩码矩阵,注意掩码矩阵为了告诉每一个 Token 哪些位置是填充的,所以这里创建的矩阵的形状是 [batch_size, seq_len, seq_len]
attn_mask = torch.ones(batch_size, seq_len, seq_len)
# 将第二条数据(索引为1)的最后一个位置设为填充(0)
attn_mask[1, :, -1] = 0 # 将第2个样本的所有行的最后一个位置设为0,表示该位置是填充的
# 3️⃣ 初始化单头自注意力层
attn = SingleHeadAttention(d_model)
print_red("单头注意力层:")
print(attn, "\n")
# 4️⃣ 使用单头自注意力层进行计算
hidden_states, _ = attn(q_input=x, k_input=x, v_input=x, attn_mask=attn_mask)
原始输入:
tensor([[[ 0.9029, 0.1884, -3.5338, 0.7972],
[-0.4688, -0.1722, -0.3909, -0.6140],
[ 0.3304, 0.6514, 0.7144, 0.0405]],
[[ 0.6229, 0.3723, -0.0573, -1.3910],
[-0.5353, -1.2963, -1.7738, -0.9884],
[ 0.0204, 2.1202, 0.8002, -1.8564]]])
单头注意力层:
SingleHeadAttention(
(q_proj): Linear(in_features=4, out_features=4, bias=False)
(k_proj): Linear(in_features=4, out_features=4, bias=False)
(v_proj): Linear(in_features=4, out_features=4, bias=False)
)
【步骤1】计算query、key和value向量
【步骤 2】计算注意力分数,掩码前的scores:
tensor([[[ 1.5383, 0.4359, -0.6984],
[ 0.1596, 0.0670, -0.1410],
[-0.3198, -0.0908, 0.1471]],
[[-0.2235, 0.0154, -0.1355],
[-0.0538, 0.9528, -0.6552],
[-0.5346, -0.2195, -0.4333]]], grad_fn=<DivBackward0>)
【步骤 2-1】掩码后的scores:
tensor([[[ 1.5383e+00, 4.3592e-01, -6.9842e-01],
[ 1.5962e-01, 6.7045e-02, -1.4101e-01],
[-3.1977e-01, -9.0802e-02, 1.4713e-01]],
[[-2.2349e-01, 1.5379e-02, -1.0000e+09],
[-5.3758e-02, 9.5279e-01, -1.0000e+09],
[-5.3462e-01, -2.1949e-01, -1.0000e+09]]],
grad_fn=<MaskedFillBackward0>)
【步骤 3】计算注意力权重,注意力权重:
tensor([[[0.6950, 0.2308, 0.0742],
[0.3771, 0.3437, 0.2792],
[0.2596, 0.3264, 0.4140]],
[[0.4406, 0.5594, 0.0000],
[0.2677, 0.7323, 0.0000],
[0.4219, 0.5781, 0.0000]]], grad_fn=<SoftmaxBackward0>)
【步骤 4】 计算加权和:
tensor([[[-0.9885, -0.5199, 0.4081, 0.7878],
[-0.5386, -0.2718, 0.2932, 0.3942],
[-0.3856, -0.1897, 0.2493, 0.2249]],
[[-0.0747, 0.6024, 0.4616, 0.6949],
[-0.0043, 0.5680, 0.3469, 0.7681],
[-0.0671, 0.5986, 0.4492, 0.7028]]], grad_fn=<UnsafeViewBackward0>)
18.3. 层归一化#
在Transformer架构中,层归一化(Layer Normalization)是确保模型稳定训练、加速收敛的关键技术。它通过对每个神经元层的输出进行标准化,将激活值调整到均值为0、方差为1的分布,有效缓解了深度网络中的梯度消失和爆炸问题。
18.3.1. 层归一化的计算公式#
18.3.2. 层归一化的计算步骤#
假设我们有一个输入向量 \(x\),它代表了神经网络中某一层(例如Transformer中的前馈神经网络层或多头注意力层)的输出,这个向量有 \(H\) 个特征维度(可以理解为神经元的个数)。层归一化的计算过程可以分解为以下四个清晰的步骤,整个过程是针对单个样本,在其特征维度上进行的。具体过程如下:
步骤 1:计算均值和方差。
对于这个包含 \(H\) 个数值的输入向量,我们首先计算它的均值 \(μ\) 和方差 \(σ^2\) 。
均值计算:把向量里所有的数值加起来,然后除以特征的数量 \(H\),得到平均值 \(μ\)。
方差计算:衡量这 \(H\) 个数值偏离均值的程度。计算每个数值与均值的差的平方,把这些平方值加起来,再除以 \(H\),得到方差 \(σ^2\) 。
步骤 2:归一化。
得到均值和方差后,我们对输入向量的每一个分量 \(x_i\) 进行归一化处理。将每个数值减去均值(使其中心化为 0),再除以标准差(即方差的平方根,使其缩放到单位方差)。
为了确保计算过程防止除数为 0,会在分母上加上一个非常小的正数 \(ϵ\)。 经过这一步,原始的输入向量 \(x\) 就被转换成了一个均值为 0、方差为 1 的全新向量 \(\hat{x}\) 。此时,所有特征的数值尺度都统一了。
步骤 3:进行缩放平移,恢复与增强模型的表示能力。
数据全部变成标准的正态分布虽然稳定,但可能会破坏原始数据本身的分布特性,从而降低模型的表达能力。例如,原始数据中某些特征本身就具有较大的方差(即比较重要),这一步可能会抹掉这种差异。
为了解决这个问题,层归一化引入了两个可学习的参数:缩放参数 \(γ\) 和平移参数 \(β\)。
缩放:将归一化后的向量 \(\hat{x}\) 与 \(γ\) 逐元素相乘。\(γ\) 的作用是调整每个特征的方差(可以放大或缩小特征的重要性)。
平移:再在乘积结果上加上 \(β\)。\(β\) 的作用是调整每个特征的均值(可以决定激活函数的饱和区)。
18.3.3. 层归一化的代码实现#
import torch
class LayerNorm(torch.nn.Module):
"""
层归一化(Layer Normalization)。
计算公式:
y = γ * (x - μ) / √(σ² + ε) + β
其中:
- x: 输入张量
- μ: 在特征维度上计算的均值
- σ²: 在特征维度上计算的方差(无偏估计)
- ε: 一个小常数(默认为 1e-5),防止除零
- γ: 可学习的缩放参数(初始化为全1)
Args:
normalized_shape (int): 特征维度。
"""
def __init__(self, normalized_shape):
super().__init__()
# 小常数 ε,防止除零
self.epsilon = 1e-5
# 可学习的缩放参数 γ
self.scale = torch.nn.Parameter(torch.ones(normalized_shape))
# 可学习的平移参数 β
self.shift = torch.nn.Parameter(torch.zeros(normalized_shape))
def forward(self, x):
"""
对最后一维进行归一化。
Args:
x (torch.Tensor): 输入张量,形状为 (..., normalized_shape)。
Returns:
torch.Tensor: 归一化后的张量,形状相同。
"""
# 1️⃣ 计算特征维度上的均值,用于归一化
mean = x.mean(dim=-1, keepdim=True)
# 1️⃣ 计算特征维度上的方差,用于归一化(无偏=False表示使用有偏估计,样本方差直接除以样本数 n)
var = x.var(dim=-1, keepdim=True, unbiased=False)
# 2️⃣ 归一化输入 x,将其转换为零均值、单位方差的分布
norm_x = (x - mean) / torch.sqrt(var + self.epsilon)
# 3️⃣ 缩放和平移标准化后的输出
return self.scale * norm_x + self.shift
18.3.4. 层归一化的应用实例#
from dsxllm.util import print_table
# 创建 LayerNorm 层
emb_dim = 100
layer_norm = LayerNorm(emb_dim)
# 创建虚拟输入数据
dummy_input = torch.randn(2, 5, emb_dim) # [batch_size, sequence_length,embedding_dimension]
# 应用 LayerNorm 层
normalized_output = layer_norm(dummy_input)
# 在样本维度上计算输出的均值和方差
dummy_input_mean = dummy_input.mean(dim=-1)
dummy_input_variance = dummy_input.var(dim=-1, unbiased=False)
# 重新在样本维度计算输出的均值和方差,用于验证层归一化的效果
normalized_output_mean = normalized_output.mean(dim=-1)
normalized_output_variance = normalized_output.var(dim=-1, unbiased=False)
print_table("层归一化示例", field_names=["Information", "Value"], data=[
["归一化前的数据均值", [[round(val, 4) for val in row] for row in dummy_input_mean.tolist()]],
["归一化前的数据方差", [[round(val, 4) for val in row] for row in dummy_input_variance.tolist()]],
["归一化后的数据均值", [[round(val, 4) for val in row] for row in normalized_output_mean.tolist()]],
["归一化后的数据方差", [[round(val, 4) for val in row] for row in normalized_output_variance.tolist()]]
])
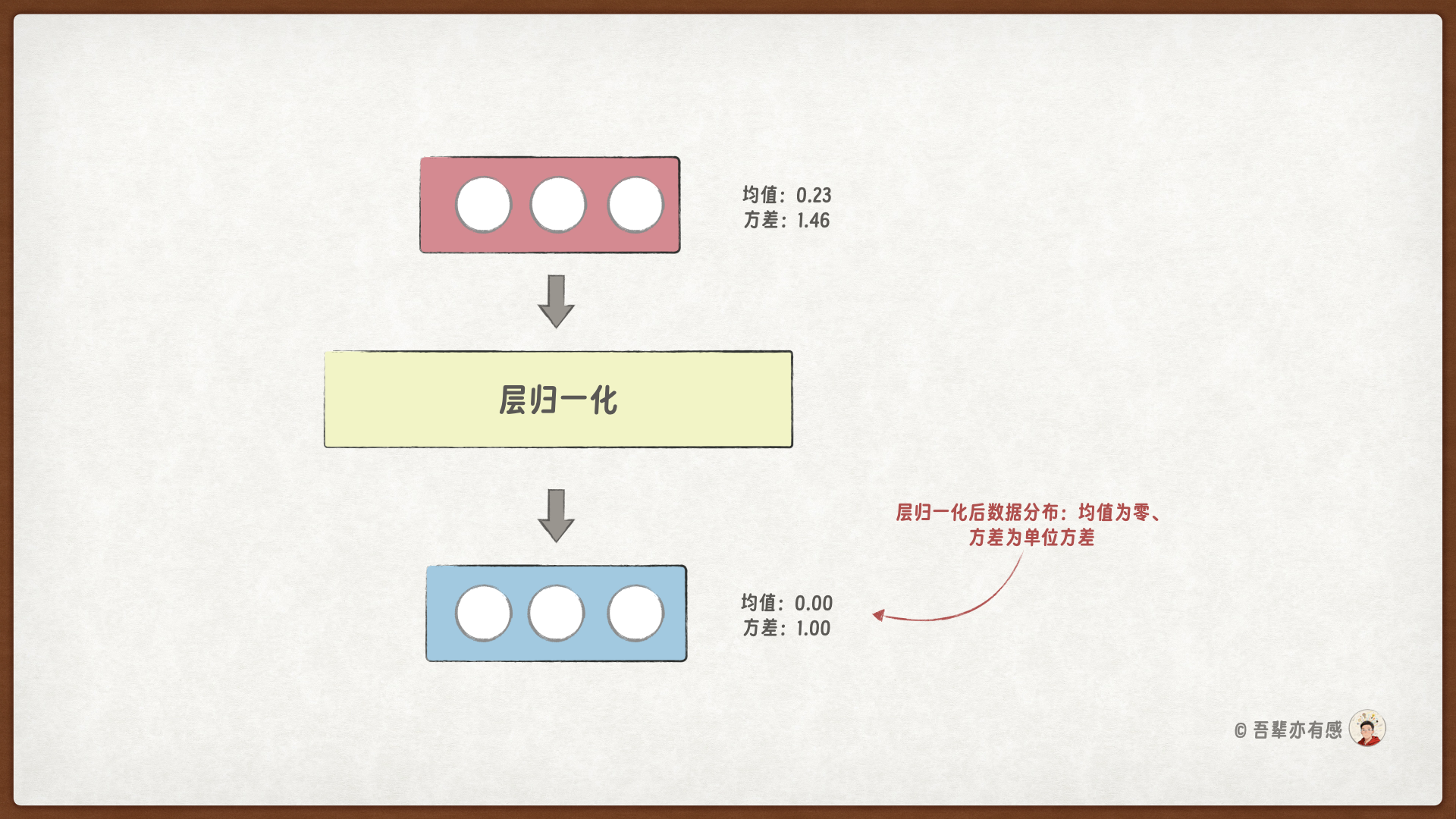
层归一化示例:
+--------------------+------------------------------------------------------------------------------------------+
| Information | Value |
+--------------------+------------------------------------------------------------------------------------------+
| 归一化前的数据均值 | [[0.0471, 0.2317, -0.1051, -0.1338, 0.0305], [0.0856, -0.0461, 0.0033, 0.0874, -0.0156]] |
| 归一化前的数据方差 | [[0.9303, 1.2771, 0.9971, 0.9122, 0.9878], [0.931, 0.8498, 0.9758, 0.8169, 1.062]] |
| 归一化后的数据均值 | [[-0.0, -0.0, 0.0, 0.0, 0.0], [0.0, -0.0, 0.0, 0.0, -0.0]] |
| 归一化后的数据方差 | [[1.0, 1.0, 1.0, 1.0, 1.0], [1.0, 1.0, 1.0, 1.0, 1.0]] |
+--------------------+------------------------------------------------------------------------------------------+
观察输出结果可知,经过层归一化处理后,数据的均值等于 0,方差为单位方差 1。这表明层归一化层起到了预期的作用。
18.4. 残差连接#
在 Transformer 模型中,残差连接(Residual Connection),也称为跳跃连接(Skip Connection),是架构中一个至关重要的组件。它最早由 He 等人在 ResNet 中提出,用于解决深层神经网络训练中的梯度消失和网络退化问题。Transformer 将其与层归一化结合,使得模型能够构建非常深的堆叠结构,同时保持训练的稳定性和效率。
残差连接和之前优化 Seq2Seq 模型中使用的信息偷窥的思路基本一致。即将子层(如自注意力或前馈网络)的输入直接加到该子层的输出上。这保证了信息可以无损地绕过子层直接传递到后续层,梯度也能通过这条“捷径”反向传播,从而缓解梯度消失。这样,模型能够更充分的利用输入数据中的信息,防止信息丢失。
18.5. 前馈神经网络层#
前馈网络层是 Transformer 编码器层中的第二个子层,位于多头自注意力层之后。它通过非线性变换、维度扩展与压缩等方式,对 Token 的信息进一步的融合,从而增强模型的表达能力。
前馈网络层包括三个线性层:
第一个线性层是升维层,将输入升维到一个高维空间(通常是嵌入维度的 4 倍),然后通过激活函数进行非线性变换。
第二个线性层是门控层,目的是引入一个并行的”门”,来控制信息的流动,允许模型在某些特征上进行更重要的关注。
第三个线性层是降维层,将特征降维回原始维度。这种维度扩展与压缩的过程增加了模型的容量,允许更复杂的特征表示。
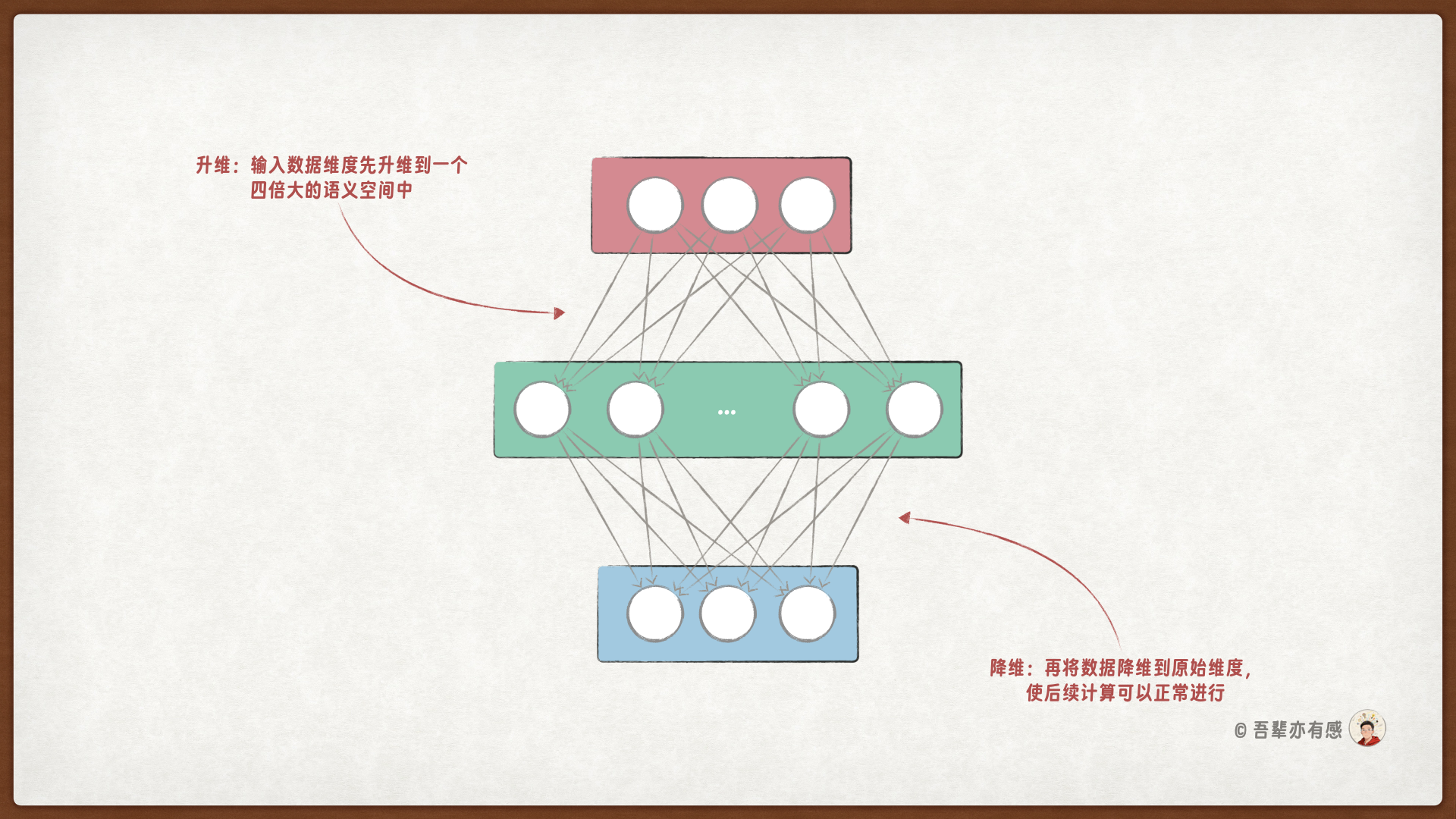
前馈网络层的内部结构如下图所示:
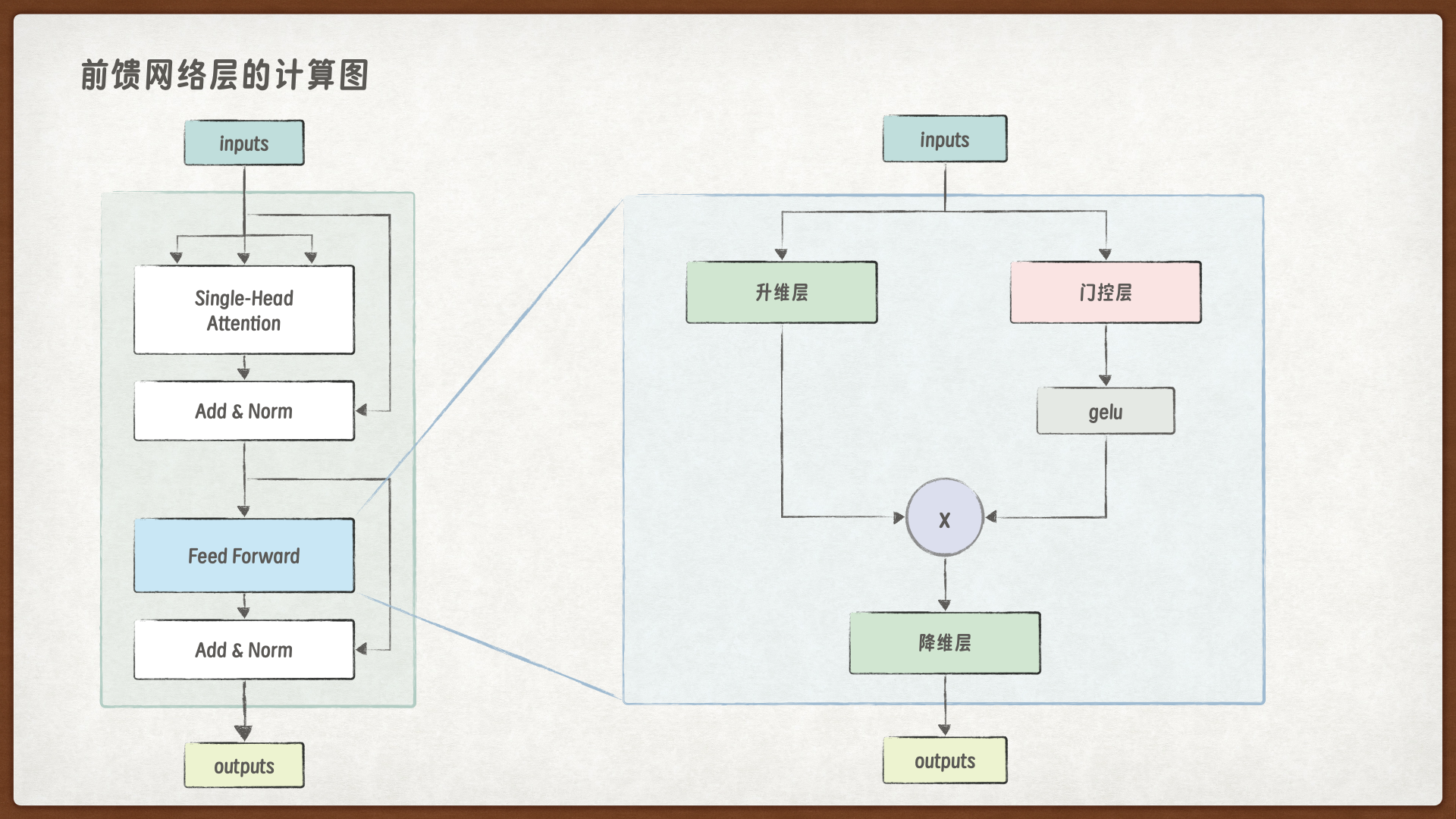
18.5.1. 前馈网络层的代码实现#
from transformers.activations import ACT2FN
class MLP(nn.Module):
"""
带有门控机制的前馈神经网络(GLU变体)。
该模块包含三个线性变换:
- up_layer: 将输入维度从 d_model 扩展到 4 * d_model
- gate_layer: 同样将输入扩展到 4 * d_model,作为门控信号
- down_layer: 将合并后的 4 * d_model 维度压缩回 d_model
计算公式:
output = down_layer(activation(gate_layer(x)) * up_layer(x) )
其中 activation 默认为 GELU,通过门控机制实现特征选择。
Args:
config (dict): 配置字典,必须包含键 "d_model"(模型维度)。
hidden_act (str): 激活函数名称,默认为 "gelu"。
"""
def __init__(self, d_model, feedforward_size, hidden_act="gelu"):
super().__init__()
# 升维线性层:将输入升维到隐藏维度
self.up_layer = torch.nn.Linear(
in_features=d_model, out_features=feedforward_size, bias=False
)
# 门控线性层:生成门控信号,用于控制信息流动
self.gate_layer = torch.nn.Linear(
in_features=d_model, out_features=feedforward_size, bias=False
)
# 降维线性层:将隐藏维度降回原始维度
self.down_layer = torch.nn.Linear(
in_features=feedforward_size, out_features=d_model, bias=False
)
# 激活函数
self.activation_fn = ACT2FN[hidden_act]
def forward(self, x):
"""
前向传播。
Args:
x (torch.Tensor): 输入张量,形状为 (batch_size, seq_len, d_model)。
Returns:
torch.Tensor: 输出张量,形状与输入相同。
"""
# 门控机制:激活(门控(x)) * 升维(x)
gated = self.activation_fn(self.gate_layer(x)) * self.up_layer(x)
# 降维到原始维度
output = self.down_layer(gated)
return output
18.5.2. 前馈网络层的详细信息#
# 设置前馈网络的中间层大小为模型维度的 4 倍
feedforward_size = 4 * d_model
# 创建MLP实例,输入维度为d_model,隐藏层大小为feedforward_size
mlp = MLP(d_model, feedforward_size)
# 打印MLP对象的信息
print(mlp)
MLP(
(up_layer): Linear(in_features=4, out_features=16, bias=False)
(gate_layer): Linear(in_features=4, out_features=16, bias=False)
(down_layer): Linear(in_features=16, out_features=4, bias=False)
(activation_fn): GELUActivation()
)
18.6. 本章小结#
本章我们深入剖析了 Transformer 编码器的内部结构,并一步步动手实现了其中的核心组件。通过代码实践,我们不仅理解了每个模块的数学原理,更直观地看到了它们如何协同工作——自注意力机制捕捉序列内部依赖,层归一化稳定训练过程,前馈网络增强模型的非线性表达能力。
这些组件的组合构成了现代 Transformer 编码器的基本单元,动手实现的过程也让我们体会到,从理论到代码的转化是真正掌握模型精髓的关键一步。
18.7. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。