37. 【实战】AIGC 时代大模型信息安全隐私保护#
37.1. 任务背景#
随着大语言模型(LLM)应用的广泛普及,用户对数据隐私的担忧日益加剧。这类担忧主要源于用户在与云端模型交互时,所输入的提示词(Prompts)中可能无意间泄露个人或企业的隐私敏感信息。在多数实际场景中,用户并不需要保护提示词中的所有信息,而只需防止其中的隐私实体被泄露即可。
然而,传统的匿名化处理方法无法在 LLM 的生成结果中将已替换的隐私敏感信息予以还原,这在一定程度上限制了该技术在实际应用中的可用性与准确性。
所以,我们需要设计一种可逆的隐私保护机制:在将提示词发送给云端模型之前,先识别并脱敏其中的隐私实体;待模型生成结果返回后,再将结果中替换的实体精准还原为原始实体。这样既能避免敏感信息直接暴露给云端,又能保证模型输出的完整性和可用性,从而在不显著影响生成质量的前提下,有效平衡隐私保护与功能需求。
37.2. 任务内容#
本次任务我们将微调一个本地的小参数量的 HideAndSeek 模型,使其具备脱敏和还原的能力:
脱敏(Hide):采用平行替换策略,识别提示词中的隐私实体(如人名、地名、身份证号等),并将它们平行替换为隐私实体。
还原(Seek):在云端模型返回生成结果后,本地模型负责将结果中的隐私实体精准还原为原始实体以恢复可用性。
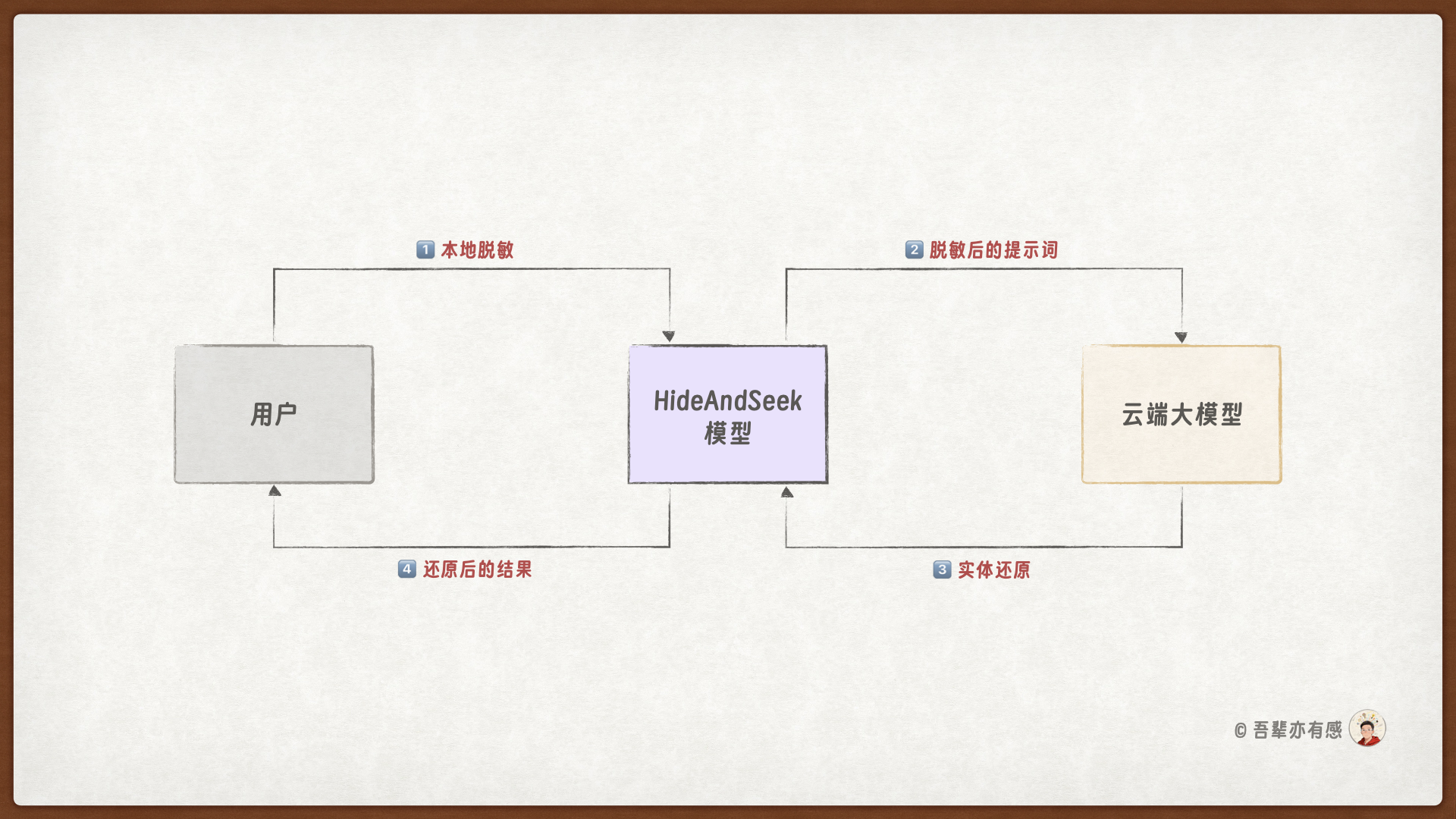
本次任务使的模型、微调方式和微调框架如下:
基础模型:Qwen2.5-0.5B-Instruct
微调方式:LoRA
微调框架:Swift
37.3. 学习收获#
完成本次任务,你将能够:
理解大模型交互中的隐私保护核心挑战
掌握端云协同的可逆脱敏服务逻辑
学会构建脱敏与还原任务的高质量数据的范式
掌握面向脱敏-还原多任务学习的模型训练技巧
熟练运用 Swift 框架完成 LoRA 高效微调的全流程
37.4. 获取源码#
点击下方链接,获取任务完整源码 👇👇👇
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。