34. 【实战】基于 Qwen2.5 微调加法计算模型#
34.1. 任务背景#
在之前基于 Transformer 模型的加法计算任务中,我们已经成功地通过模型实现了加法计算功能。但是,训练的模型只能识别固定格式的加法表达式,不支持类似 12 加 34 等于多少? 这样的口语化问法。
在先前基于 Transformer 的加法计算实验中,我们成功实现了模型对加法算式的解析与计算。然而,该模型仅能处理结构固定的表达式,无法理解诸如“12 加 34 等于多少?”这类口语化的自然语言提问。
若要实现口语化理解,需使用预训练大语言模型(LLM)。但直接使用通用的大模型存在输出随机性高、格式不可控的问题。
当用户使用同一个问题和大模型对话时,模型输出的结果不一致:
🧑 用户问题:12 加 34 等于多少? 🤖 模型回答:12 加 34 等于 46。
🧑 用户问题:12 加 34 等于多少? 🤖 模型回答:12 加 34 还是 46 啦!就像你手里有 12 颗糖,朋友又给了你 34 颗,那你现在一共有 46 颗糖。跟刚才算的一样,没变哦!
所以,若我们想让大模型具备对计算结果的精准输出能力,我们需要对其进行微调(Fine-tuning)。
34.2. 任务目标#
本次任务将在 Qwen2.5 基座模型上进行微调,使其能够直接输出整数加法的数值结果,不包含多余的解释、标点或自然语言前缀,仅输出结果数字。
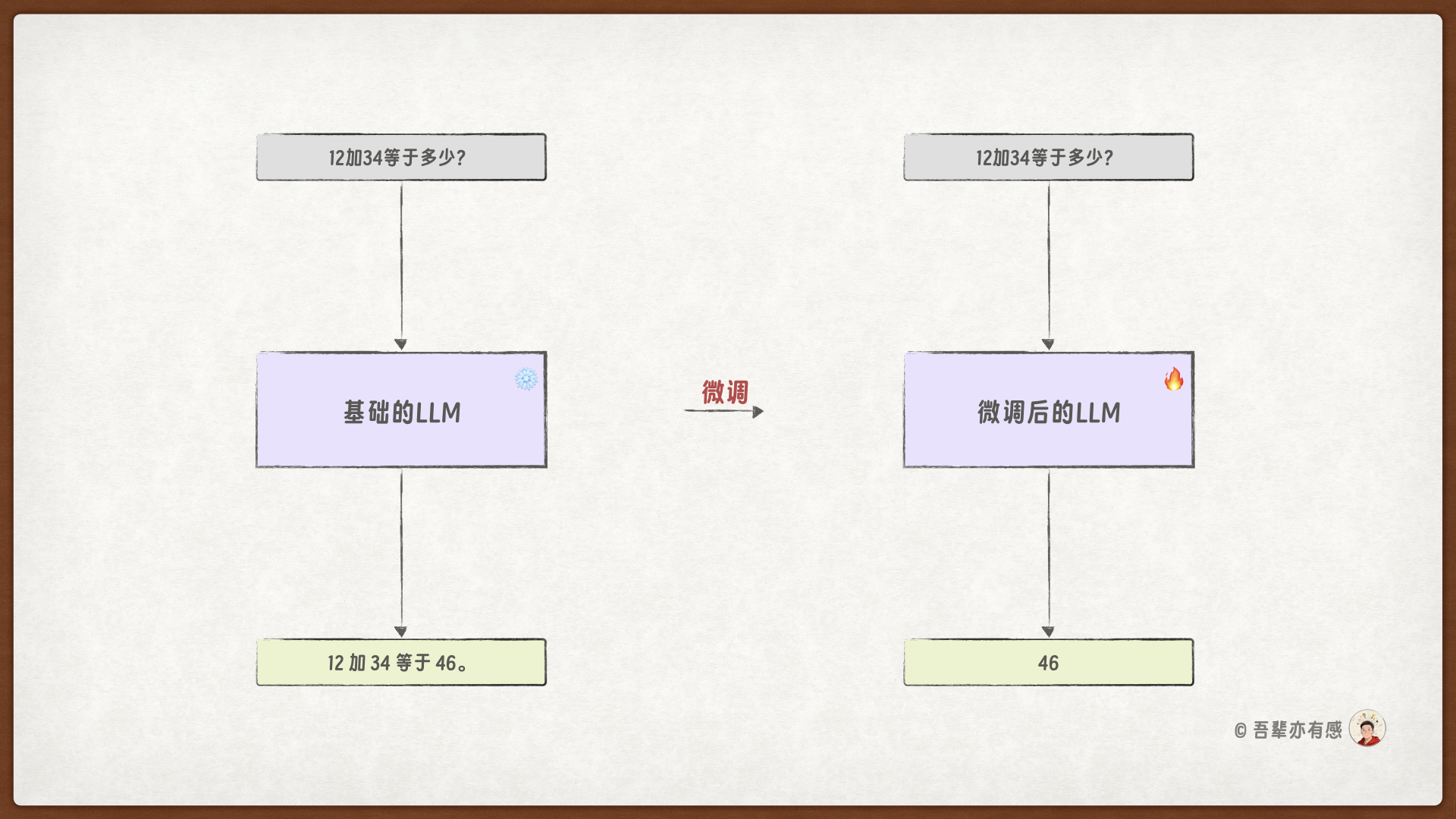
本次任务使用的基模、微调方式和微调框架如下:
基础模型:Qwen2.5-0.5B-Instruct
微调方式:LoRA
微调框架:Swift
34.3. 学习收获#
完成本次任务,你将能够:
理解微调的必要性与应用场景
掌握 LoRA 微调的核心原理与参数作用
学会组织监督微调(SFT)阶段的数据
掌握 Swift 框架下的微调全流程
34.4. 获取源码#
点击下方链接,获取任务完整源码 👇👇👇
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。