35. 【实战】自我认知微调#
35.1. 任务背景#
在大语言模型的实际应用场景中,模型默认的自我认知往往由其预训练或指令微调阶段的数据决定。例如,Qwen 系列模型在未经额外微调时,被问及 “你是谁” 或 “你是哪个公司开发的” 等问题时,会输出通用回答(如 “我是通义千问,由阿里云开发”)。
然而,在定制化场景中,我们往往需要模型输出预设的专属身份。这与模型默认的开放式回答存在明显差异。因此,需要借助自我认知微调,改变模型的自我认知。
35.2. 任务目标#
本次任务将在 Qwen2.5 基座模型上,通过自我认知微调(Self-Cognition Fine-tuning),让模型在回答”你是谁”、”你由谁开发”、”你能做什么”等自我认知类问题时,仅输出预先设定的身份描述。
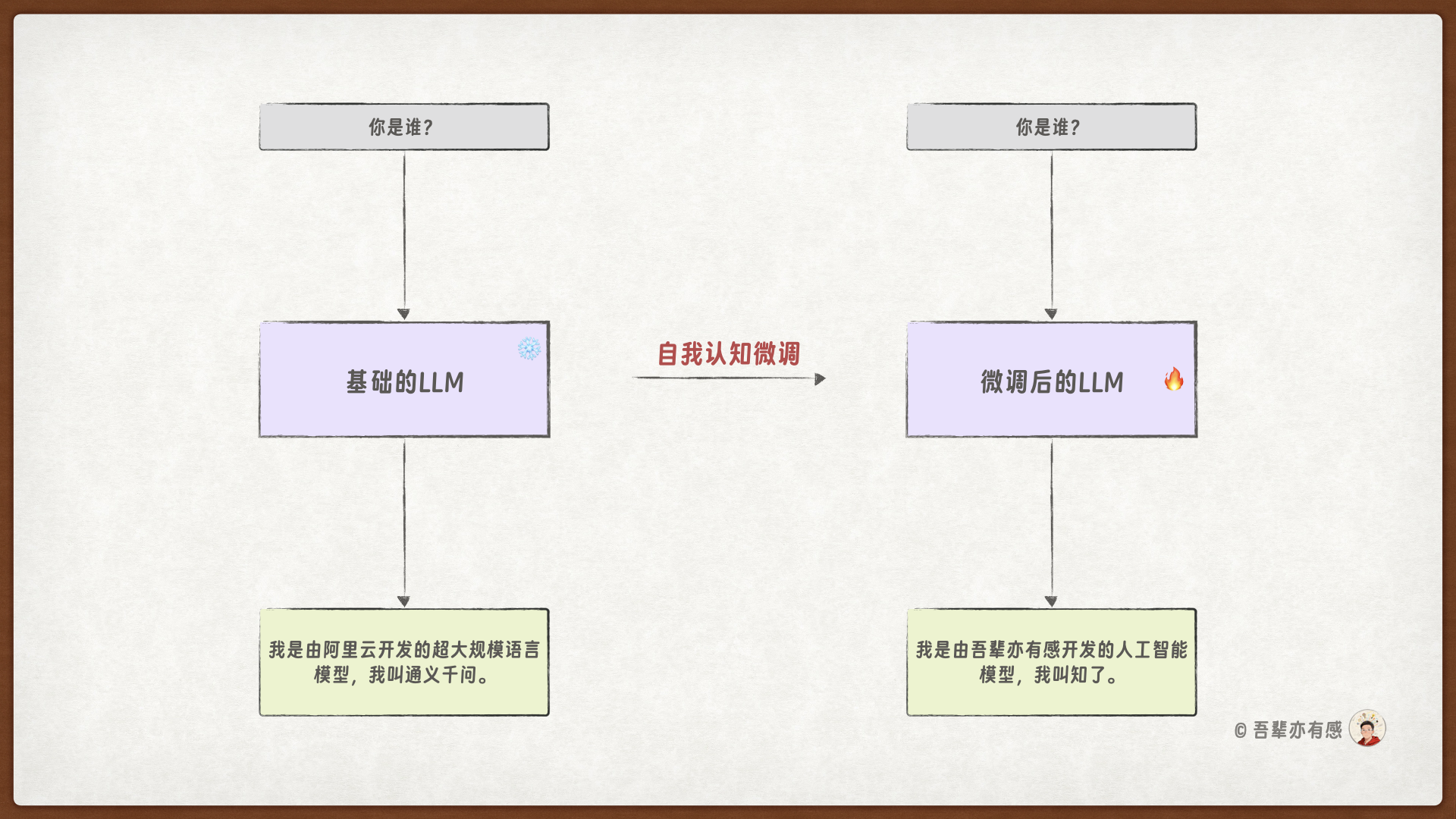
微调前:
用户:你是谁?
模型:我是由阿里云开发的超大规模语言模型,我叫通义千问。
微调后:
用户:你是谁?
模型:我是由吾辈亦有感团队开发的人工智能模型。
本次任务使用的基模、微调方式和微调框架如下:
基础模型:Qwen2.5-0.5B-Instruct
微调方式:LoRA
微调框架:Swift
35.3. 学习收获#
完成本次任务,你将能够:
掌握 Swift 框架的 LoRA 微调全流程
学会构建“自我认知”类问答的微调数据集
了解 LoRA 的关键参数及其作用
认识灾难性遗忘问题,通过数据混合防止灾难性遗忘
35.4. 获取源码#
点击下方链接,获取任务完整源码 👇👇👇
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。