
14. 注意力革命:Transformer#
本次实战会使用 Transformer 模型对加法计算器模型进行重构,助你快速掌握 Transformer 内部机制的实现细节。
14.1. 介绍#
在前面的章节中,我们利用循环神经网络处理序列数据,并基于门控循环单元(GRU)构建了一个具有编码器-解码器结构的加法计算模型。经过优化,该模型的准确率已提升至 92.25%。然而,循环神经网络固有的按时间步依次计算的方式仍存在两个主要局限:
长距离依赖的衰减:序列中较早位置的信息需要经过多个时间步才能传递到后端,在传播过程中容易发生信息衰减或丢失,从而影响模型对长距离依赖关系的建模能力。
串行计算的桎梏:随着序列长度的增加,模型的计算复杂度呈线性增长。同时,由于计算过程严格依赖时序,无法实现并行化,导致训练速度受到明显制约。
为克服上述问题,Transformer 模型摒弃了传统的循环结构,完全基于自注意力机制(Self-Attention)来捕捉序列内部的依赖关系。自注意力机制允许模型在处理每个位置时,直接关注序列中所有其他位置的信息,从而有效缓解了长距离信息丢失的问题。更重要的是,Transformer 能够同时对序列中的所有位置进行并行计算,大幅提升了训练效率。正是这些优势,使 Transformer 成为当今大语言模型的基础架构。
在本任务中,我们将使用 Transformer 重构加法计算模型,深入理解其内部机制。我们将逐一剖析 Transformer 的核心组件:多头自注意力机制、前馈网络、层归一化、残差连接以及位置编码等。通过本次实践,我们将切实体会到自注意力机制如何取代循环网络,并为后续学习 GPT 等大语言模型奠定坚实基础。
由于 Transformer 的机制相对复杂,为了便于大家理解和查阅,后续章节将对其各个模块进行独立详解。
14.2. 任务鸟瞰#
本次的任务目标是使用 Transformer 模型对加法计算器模型进行重构,并详细了解 Transformer 内部机制的实现细节。
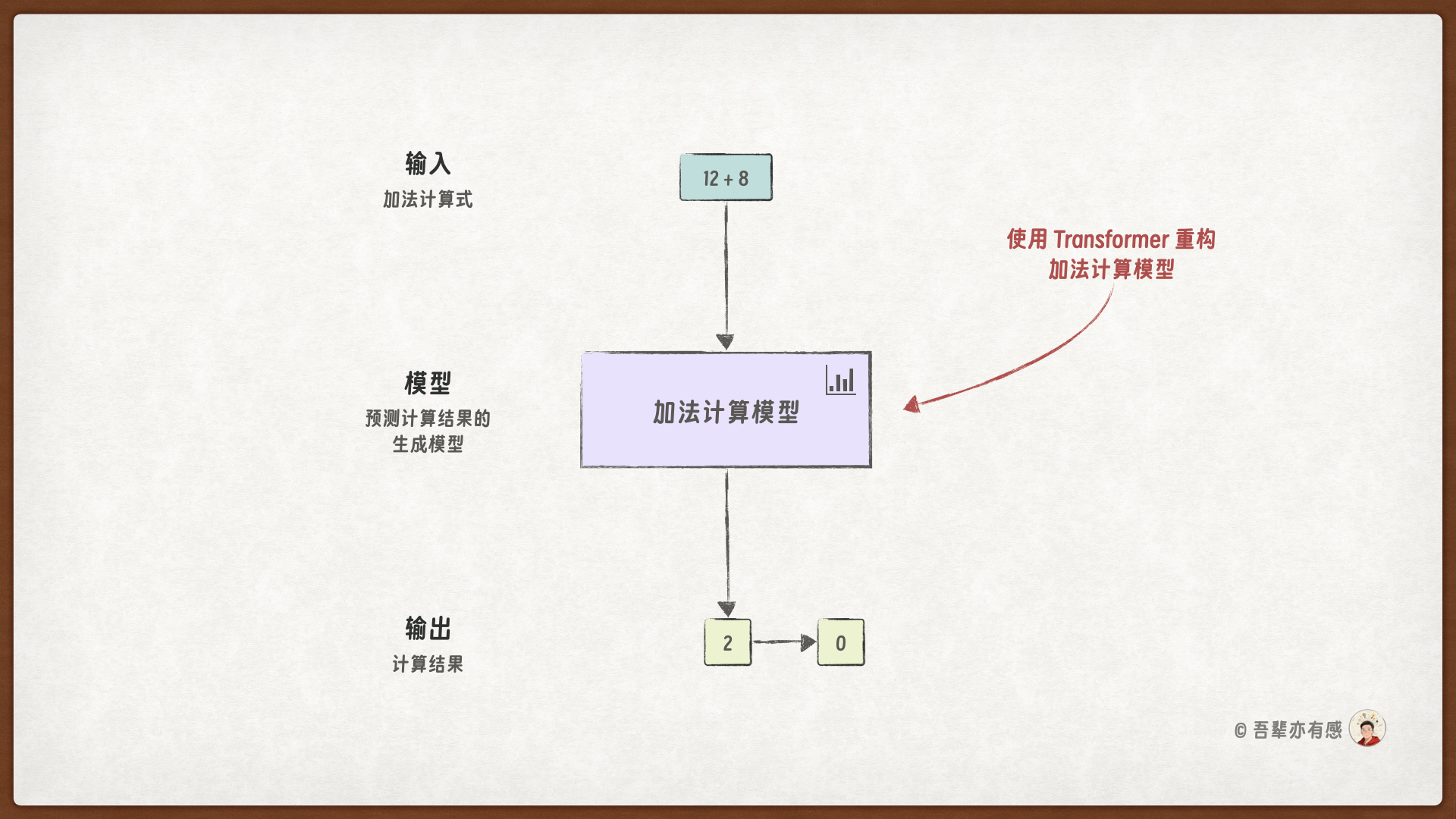
在 Transformer 出现之前,序列建模领域主要由循环神经网络(RNN)及其变体(如LSTM、GRU)主导。Transformer 摒弃了 RNN 的顺序处理方式,采用了一种全新的、完全基于注意力的编码器-解码器结构。其核心魅力在于能够并行处理整个输入序列,并直接计算序列中任意两个元素之间的关系权重。
14.3. 模型结构#
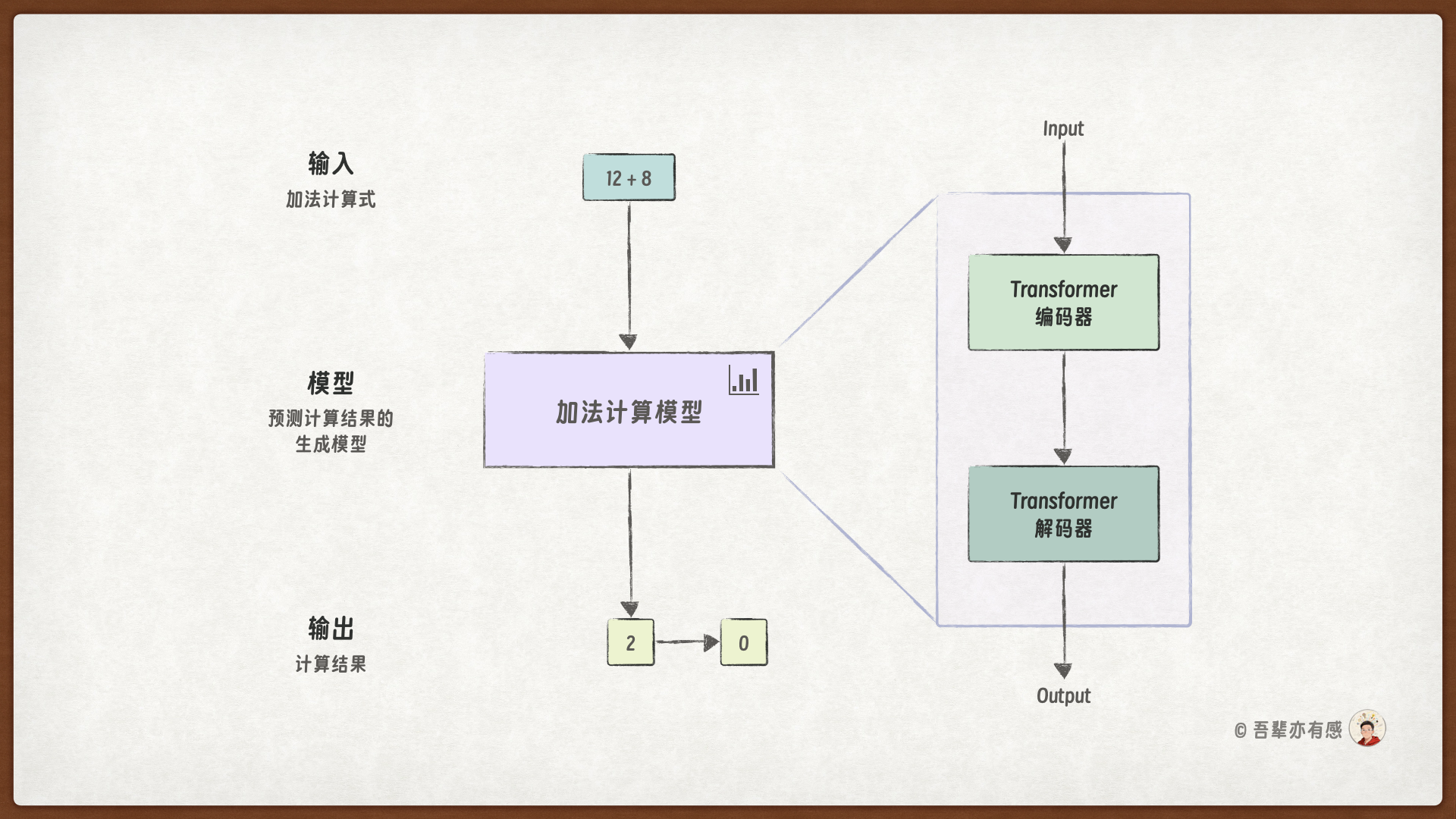
Transformer 模型也是 Seq2Seq 架构,其包含两个主要组件:编码器(Encoder)和解码器(Decoder)。编码器将输入序列编码为固定长度的特征向量,而解码器则根据编码器的输出,生成目标序列。
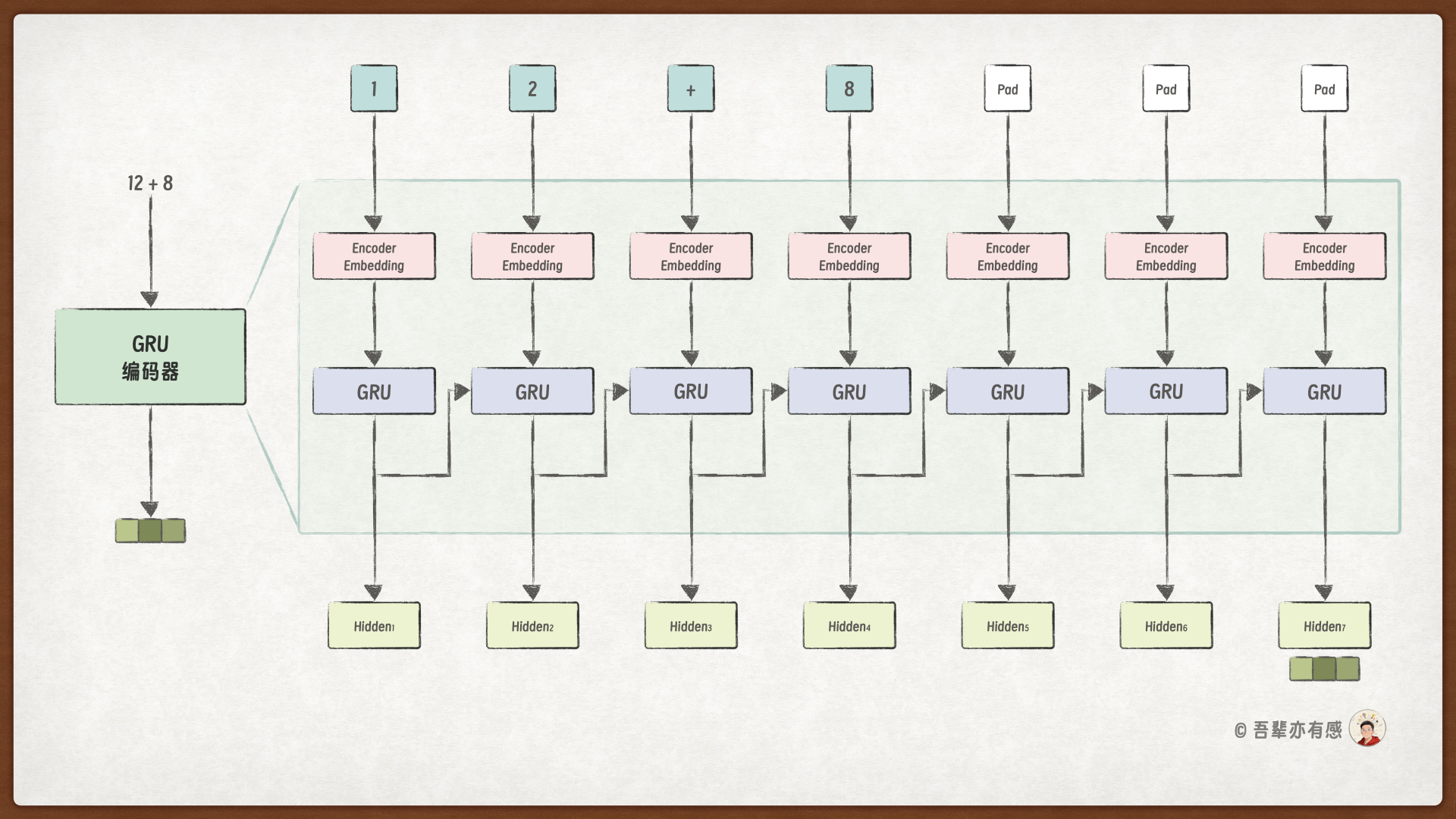
使用 Transformer 模型重构后的加法计算模型结构如下:
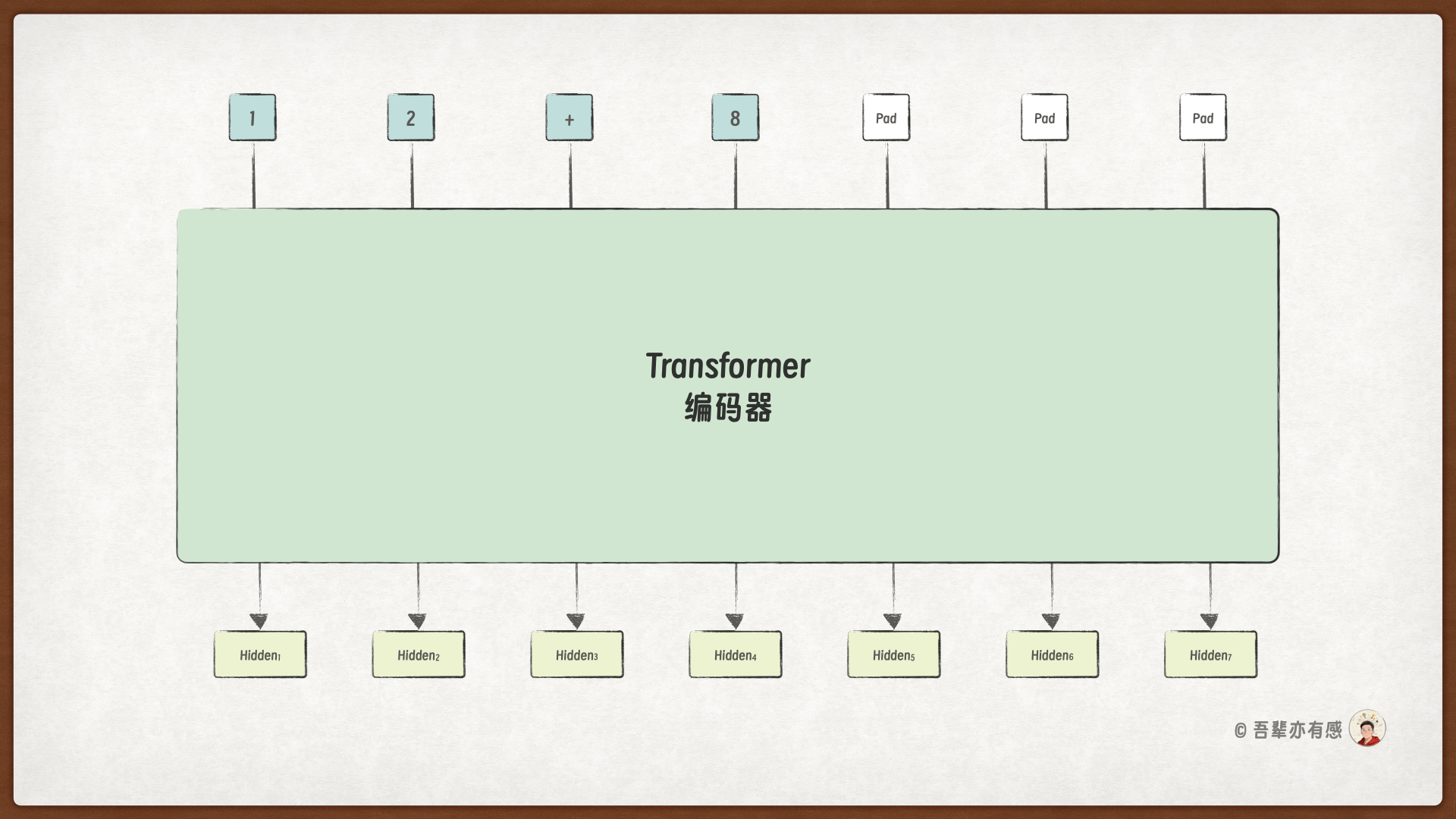
编码器负责提取输入的加法算式的隐藏特征:
解码器根据编码器的输出,生成计算结果序列:
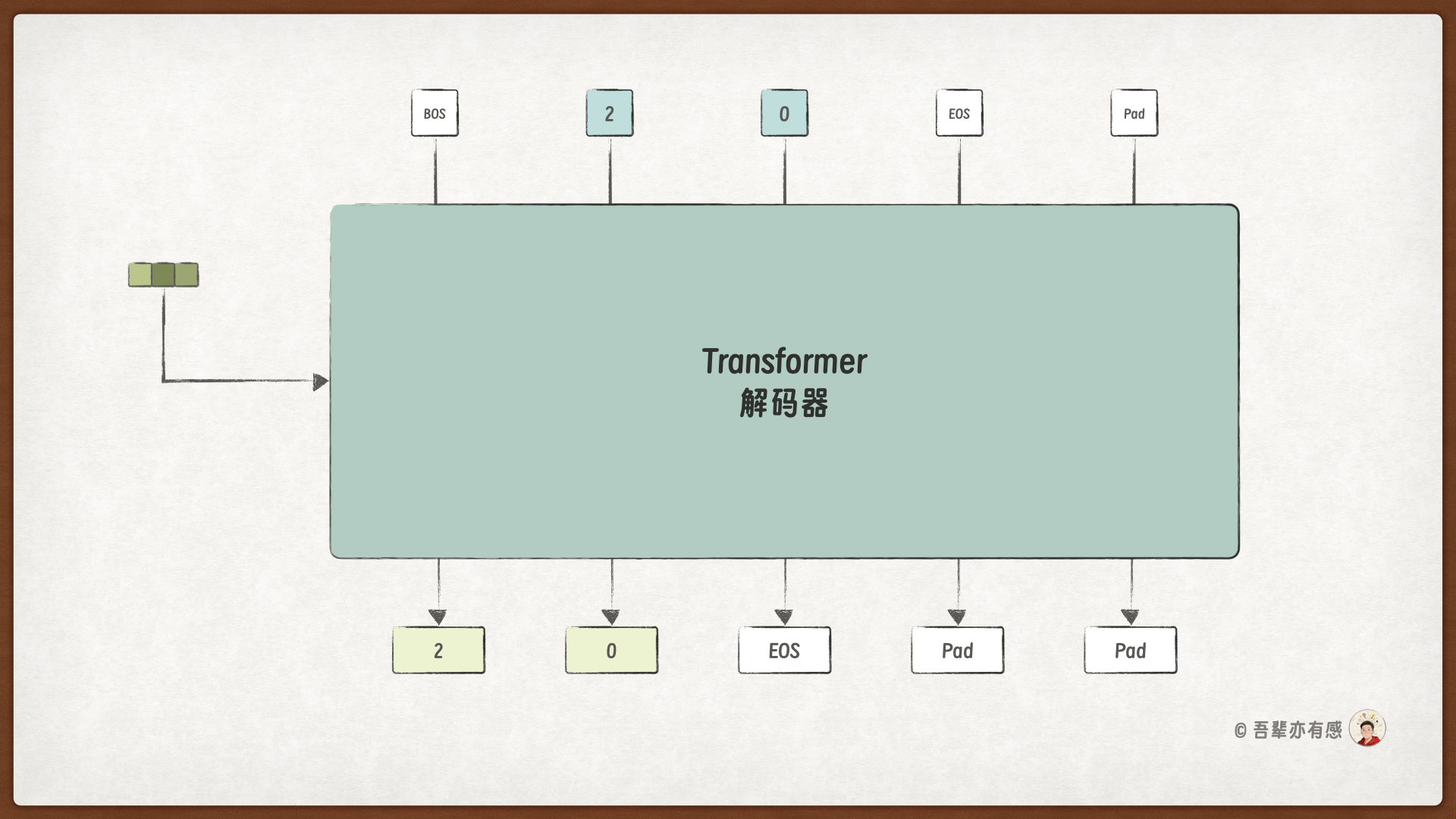
在深入模型实现细节之前,我们先准备训练所用的数据集。
14.4. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。