
13. 改进Seq2Seq模型:信息偷窥#
通过本次任务,你将学会如何使用信息偷窥改进 Seq2Seq 生成式模型的效果。
13.1. 介绍#
在上一章中,我们只是简单地反转输入数据,就将加法计算任务的准确率从 15.73% 提升为 27.03%。在这次实战中,我们将从模型结构角度,提高模型对信息的利用效率,从而进一步优化 Seq2Seq 模型的生成效果。
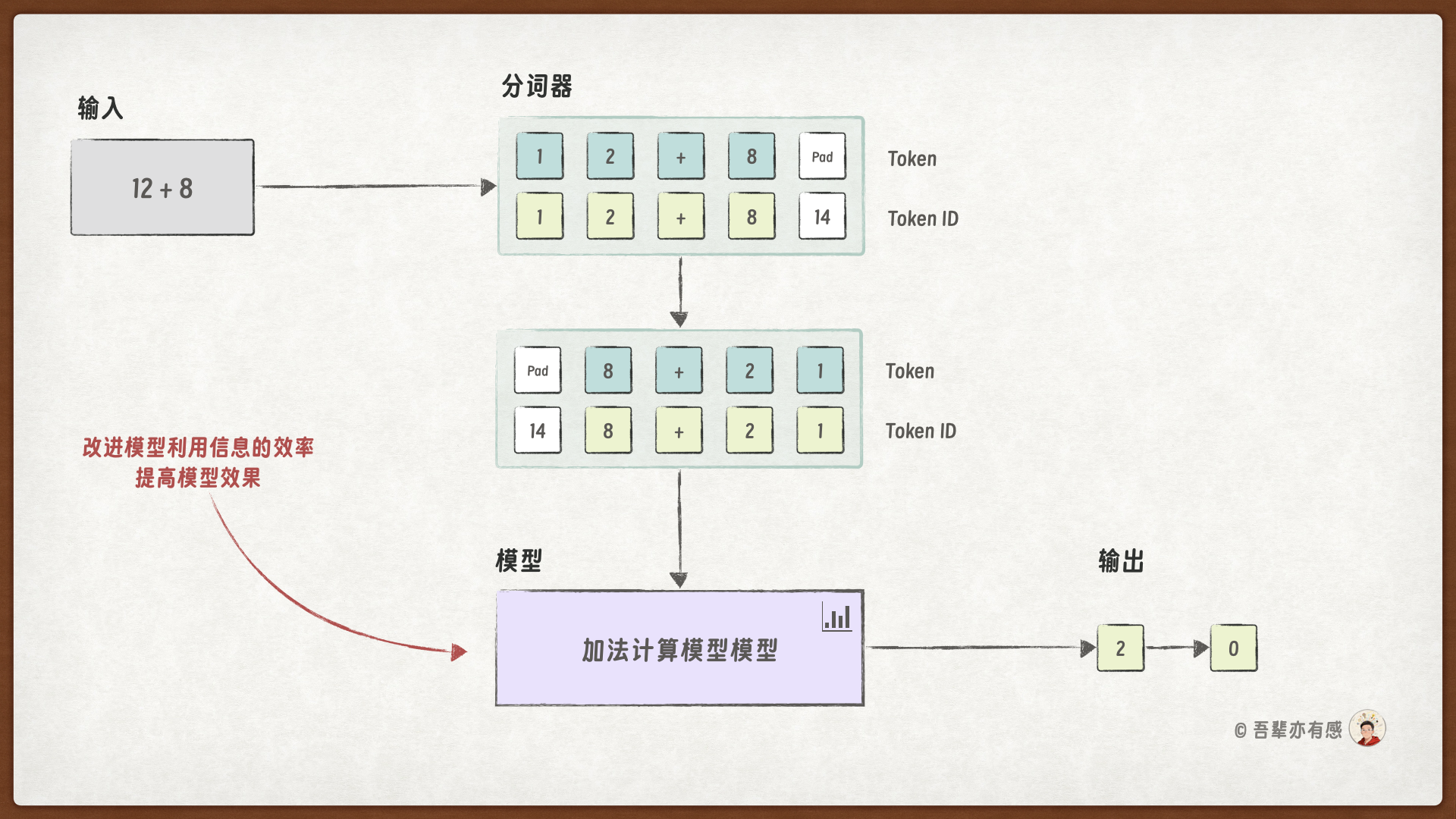
13.2. 任务鸟瞰#
在目前的模型结构中,编码器提取的算式隐藏特征只作为解码器的初始状态使用,导致模型无法充分利用输入数据中的信息。
如果模型能够充分利用加法算式隐藏特征中的信息,那么模型将能够生成更准确的结果。那么,如何提升模型对信息的利用效率呢?这里我们会使用 信息偷窥 提升模型效果。
13.3. 模型结构#
信息偷窥的思路也非常简单,来源于两个非常直接的思考:
解码器在提取序列特征时,是否可以在每个时间步都重新看一看算式的隐藏特征?
解码器在生成答案序列时,是否可以在每此生成时也重新看一看算式的隐藏特征?
引入信息偷窥,我们构建的编码器模型结构如下:
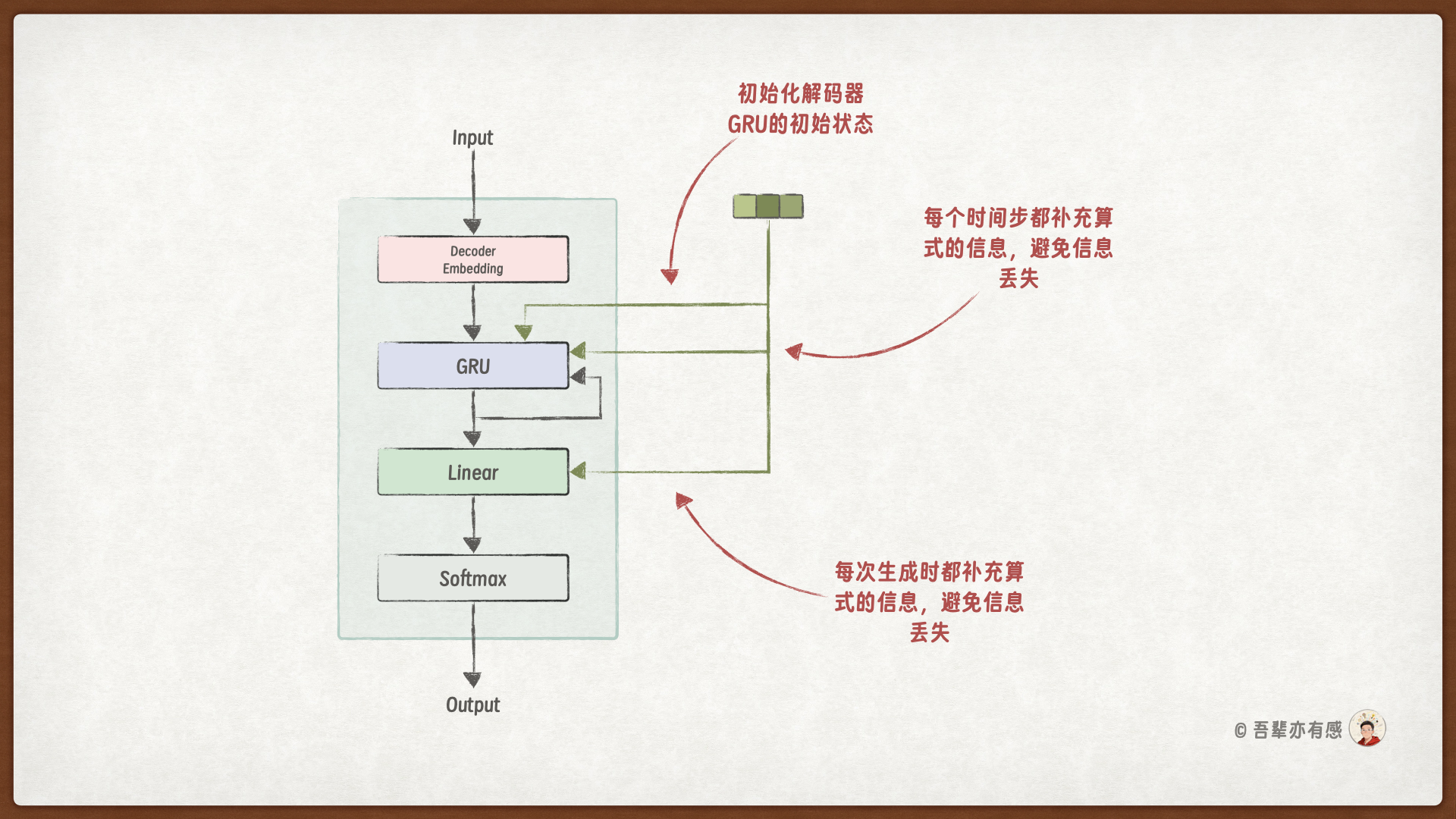
引入信息偷窥时,编码器在每个时间步解码的过程如下图所示:
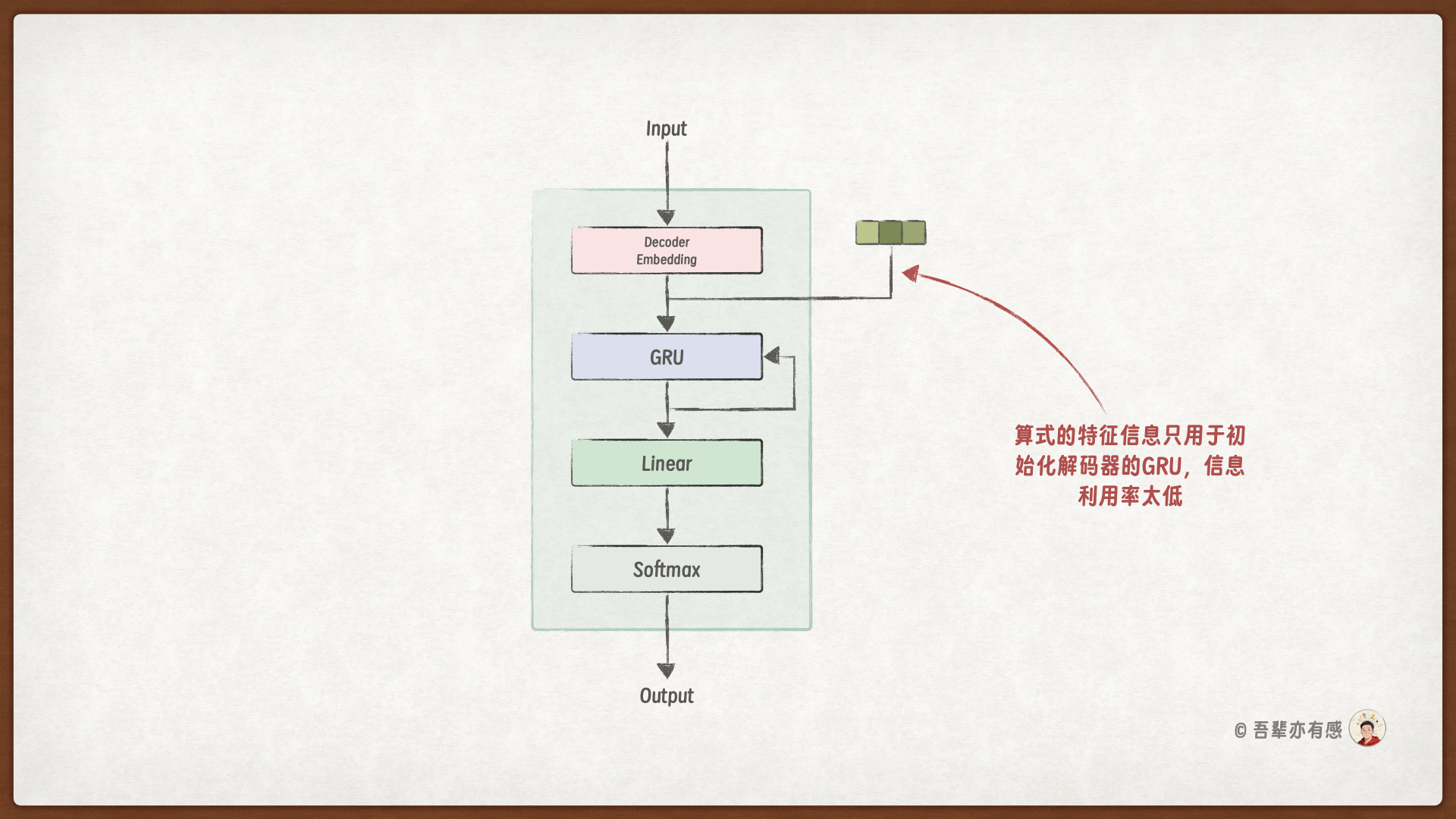
作为对比,不使用信息偷窥时解码的过程如下图所示:
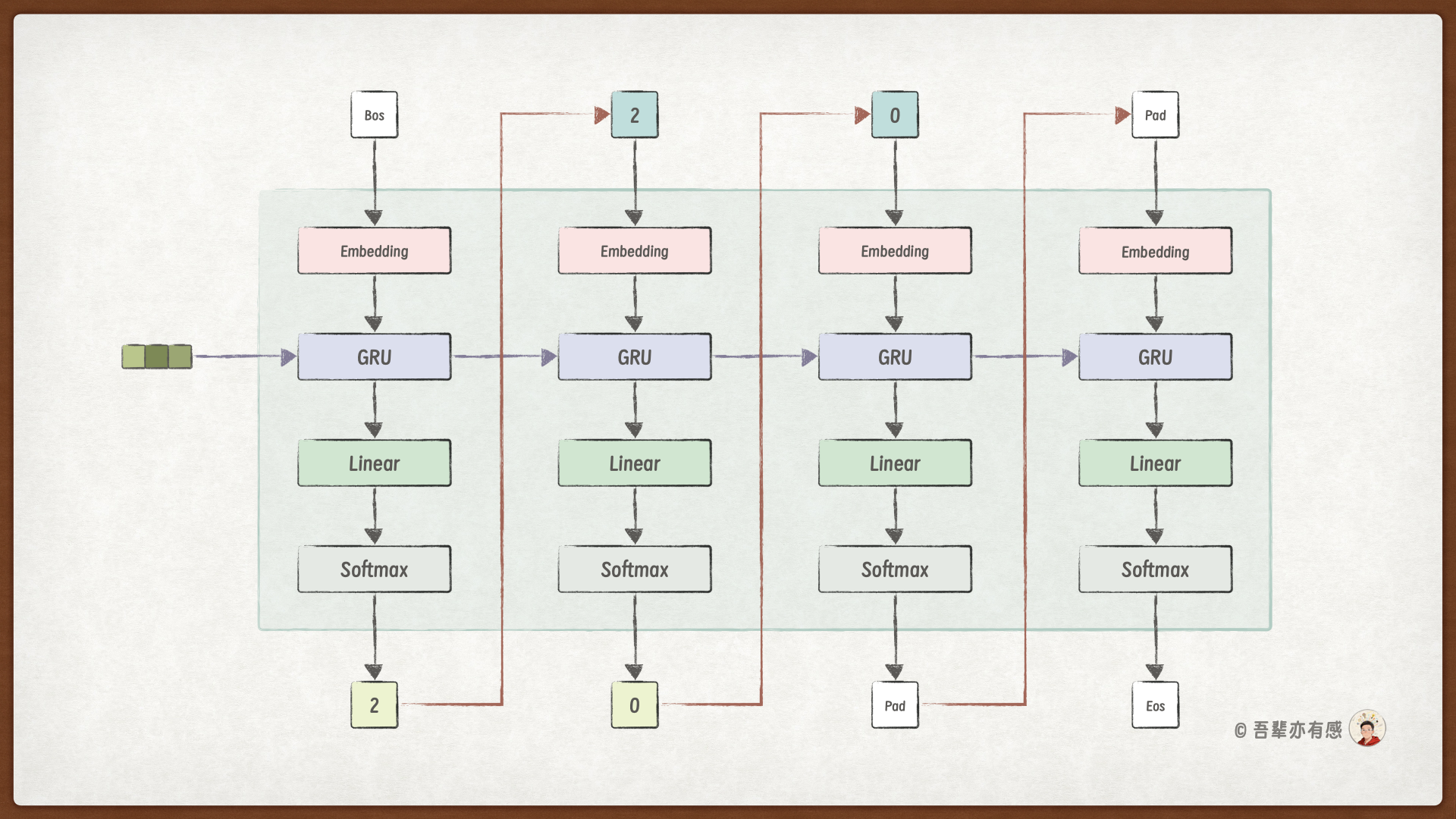
从这两个图中,我们可以看到,使用信息偷窥时,解码器模型结构有两处改动:
GRU 层除了词嵌入的结果外,还多了一个额外的输入,即算式隐藏特征(编码器的结果);
输出层除了 GRU 层的输出结果外,也多了一个额外的输入,同样是算式隐藏特征(编码器的结果)。
13.4. 环境配置#
下面我们开始本次的代码实战,照例我们先配置环境,方便大家进行代码复现。
13.4.1. 安装依赖#
!pip install --upgrade dsxllm
13.4.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
13.5. 数据准备#
本章只对模型结构进行优化,数据处理步骤与上一章相同,这里不再赘述。
13.5.1. 数据集下载#
13.5.2. 自定义分词器#
在分词时,需要进行长度对齐,处理过程如下:
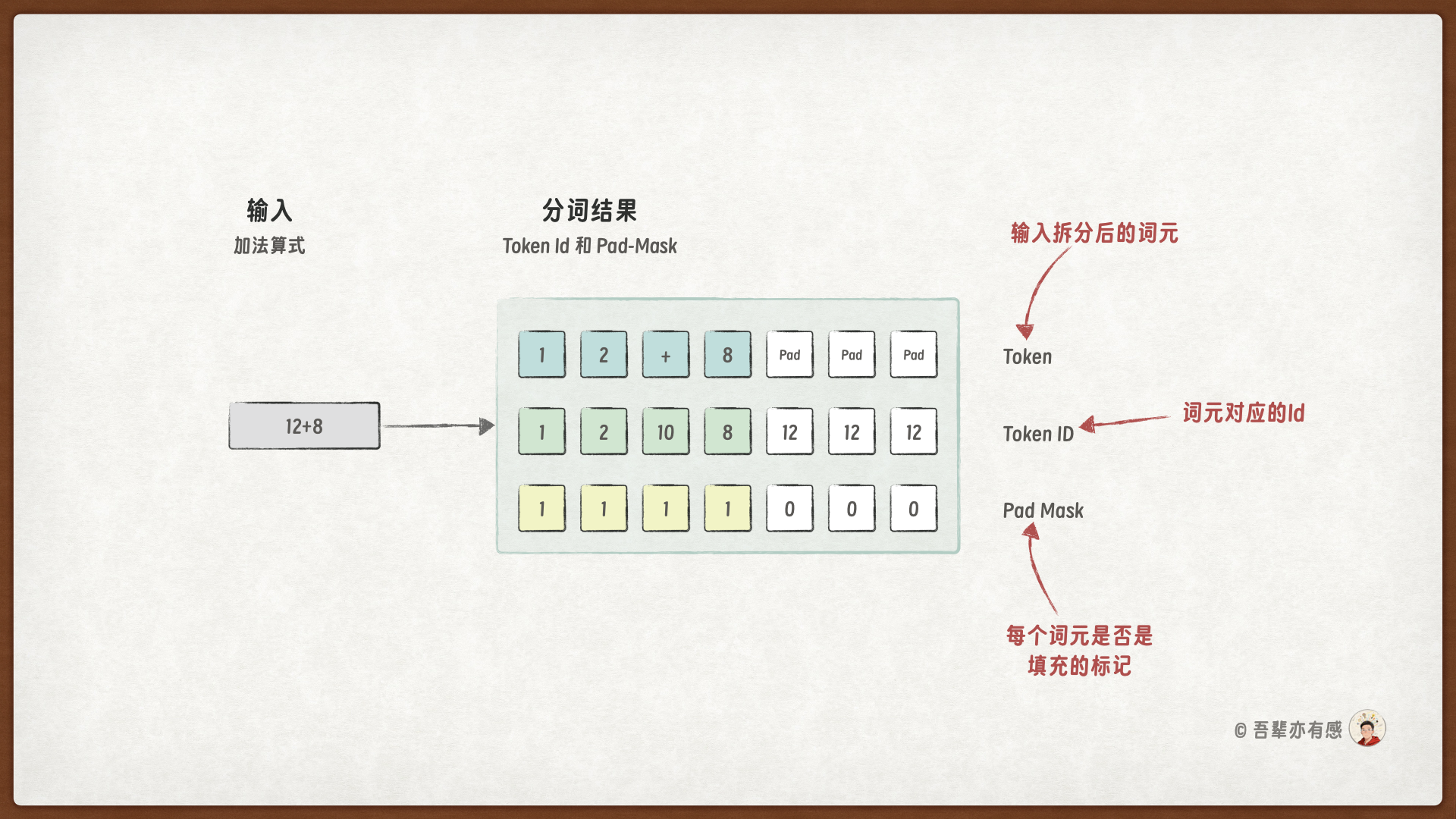
以 12+8 为例,最终会被处理成如下 json 格式:
[
{
"input_ids": [1, 2, 10, 8, 12, 12, 12],
"attention_mask": [1, 1, 1, 1, 0, 0, 0]
}
]
其中 input_ids 表示输入序列的 token ID 序列,attention_mask 表示输入序列的 pad-mask 序列。
13.5.2.1. 加法分词器的代码实现#
from dsxllm.util import print_table
import torch
class SimpleTokenizer:
def __init__(self, vocab, pad_token="<|pad|>", unk_token="<|unk|>", bos_token="<|bos|>", eos_token="<|eos|>"):
"""
初始化简单分词器
"""
self.vocab = vocab
# 反向词汇表 (id -> token)
self.ids_to_tokens = {v: k for k, v in self.vocab.items()}
# 特殊token
self.pad_token = pad_token
self.pad_token_id = self.vocab[pad_token]
self.unk_token = unk_token
self.unk_token_id = self.vocab[unk_token]
self.bos_token = bos_token
self.bos_token_id = self.vocab[bos_token]
self.eos_token = eos_token
self.eos_token_id = self.vocab[eos_token]
self.special_tokens = [self.pad_token, self.unk_token, self.bos_token, self.eos_token]
# 词汇表大小
self.vocab_size = len(self.ids_to_tokens)
def encode(self, text):
# 将文本拆分为单个字符和特殊标记
tokens = self._tokenize_special_tokens(text)
# 将每个token转换为对应的token ID
input_ids = [self.vocab[token] for token in tokens if token in self.vocab]
return input_ids
def _tokenize_special_tokens(self, text):
# 识别并处理特殊标记
tokens = []
i = 0
while i < len(text):
# 检查是否匹配特殊标记
for token in self.special_tokens:
if text[i:i + len(token)] == token:
tokens.append(token)
i += len(token)
break
else:
# 如果不是特殊标记,则逐个字符处理
tokens.append(text[i])
i += 1
return tokens
def decode(self, input_ids, skip_special_tokens=True):
# 如果 input_ids 是 torch.Tensor,则转换为列表
if isinstance(input_ids, torch.Tensor):
input_ids = input_ids.squeeze().tolist()
# 将token ID序列转换为对应的字符
tokens = [self.ids_to_tokens.get(id) for id in input_ids]
# 去除开始符和结束符
if skip_special_tokens:
tokens = [token for token in tokens if token not in self.special_tokens]
return ''.join(tokens)
def __call__(self, texts, max_length=None, padding=False, return_tensors=False):
"""
分词器主调用函数
"""
is_single_text = False
if isinstance(texts, str):
is_single_text = True
texts = [texts]
# 编码所有文本
all_token_ids = []
all_attention_masks = []
for text in texts:
token_ids = self.encode(text)
# 处理填充和注意力掩码
if padding and max_length is not None:
attention_mask = [1] * len(token_ids) + [0] * (max_length - len(token_ids))
token_ids += [self.pad_token_id] * (max_length - len(token_ids))
else:
attention_mask = [1] * len(token_ids)
all_token_ids.append(token_ids)
all_attention_masks.append(attention_mask)
if is_single_text:
all_token_ids = all_token_ids[0]
all_attention_masks = all_attention_masks[0]
# 转换为tensor
if return_tensors:
all_token_ids = torch.tensor(all_token_ids, dtype=torch.long)
all_attention_masks = torch.tensor(all_attention_masks, dtype=torch.long)
return {'input_ids': all_token_ids, 'attention_mask': all_attention_masks}
def info(self):
"""
打印分词器的详细信息
"""
# 通用信息表
info_data = [
["Vocabulary Size", self.vocab_size],
["Padding Token", f"{self.pad_token} (ID: {self.pad_token_id})"],
["Unknown Token", f"{self.unk_token} (ID: {self.unk_token_id})"],
["Start Token", f"{self.bos_token} (ID: {self.bos_token_id})"],
["End Token", f"{self.eos_token} (ID: {self.eos_token_id})"]
]
print_table("General Information", field_names=["Information", "Value"], data=info_data)
# 字符到ID的映射表
print_table("Token Mapping", field_names=["Token", "ID"], data=[
[char, char_id] for char, char_id in self.vocab.items()
])
# 编码解码示例表
example = "12+8" # 示例输入
encode_result = self(example, max_length=7, padding=True)
print_table("Encoding and Decoding Example", field_names=["Field", "Value"], data=[
["Input", example],
["Token Ids", encode_result['input_ids']],
["Pad Mask", encode_result['attention_mask']],
["Decode", self.decode(encode_result['input_ids'])]
])
13.5.2.2. 创建加法分词器的实例#
# 定义词汇表,将每个字符映射到唯一的索引编号
vocab = {
"0": 0,
"1": 1,
"2": 2,
"3": 3,
"4": 4,
"5": 5,
"6": 6,
"7": 7,
"8": 8,
"9": 9,
"+": 10,
"=": 11,
"<|pad|>": 12,
"<|unk|>": 13,
"<|bos|>": 14,
"<|eos|>": 15
}
# 使用定义的词汇表创建分词器实例
tokenizer = SimpleTokenizer(vocab)
# 打印分词器信息
tokenizer.info()
General Information:
+-----------------+------------------+
| Information | Value |
+-----------------+------------------+
| Vocabulary Size | 16 |
| Padding Token | <|pad|> (ID: 12) |
| Unknown Token | <|unk|> (ID: 13) |
| Start Token | <|bos|> (ID: 14) |
| End Token | <|eos|> (ID: 15) |
+-----------------+------------------+
Token Mapping:
+---------+----+
| Token | ID |
+---------+----+
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
| + | 10 |
| = | 11 |
| <|pad|> | 12 |
| <|unk|> | 13 |
| <|bos|> | 14 |
| <|eos|> | 15 |
+---------+----+
Encoding and Decoding Example:
+-----------+---------------------------+
| Field | Value |
+-----------+---------------------------+
| Input | 12+8 |
| Token Ids | [1, 2, 10, 8, 12, 12, 12] |
| Pad Mask | [1, 1, 1, 1, 0, 0, 0] |
| Decode | 12+8 |
+-----------+---------------------------+
13.5.3. 实现带反转的数据转换器#
class TextTransform:
def __init__(self, tokenizer: SimpleTokenizer, max_length=20, is_reverse=False):
self.tokenizer = tokenizer
self.max_length = max_length
self.is_reverse = is_reverse
def __call__(self, text):
if self.is_reverse:
# 进行反转
encoded = self.tokenizer(text, max_length=self.max_length, padding=True, return_tensors=True)
encoder_input_ids = encoded['input_ids']
encoder_pad_mask = encoded['attention_mask']
# 输入反转,注意:torch.flip 会创建新的张量,不会修改原张量
encoder_input_ids = torch.flip(encoder_input_ids, dims=[-1])
encoder_pad_mask = torch.flip(encoder_pad_mask, dims=[-1])
return {
"input_ids": encoder_input_ids,
"attention_mask": encoder_pad_mask,
}
else:
# 不进行反转
return self.tokenizer(text, max_length=self.max_length, padding=True, return_tensors=True)
13.5.4. 构造加法数据集#
以 16+75=91 为,将每个加法算式和对应的答案都转化成如下 json 格式:
{
'question': '16+75',
'answer': '91',
'encoder_input_ids': tensor([1, 6, 10, 7, 5, 12, 12]),
'encoder_pad_mask': tensor([1, 1, 1, 1, 1, 0, 0]),
'decoder_target_ids': tensor([ 9, 1, 12, 12]),
'decoder_pad_mask': tensor([1, 1, 0, 0])
}
转化后的数据集将包含以下字段:
question: 加法算式的原始文本answer: 对应的答案(便于评估测试)encoder_input_ids: 加法算式经过分词器转换得到的 Token ID 序列(编码器的输入)encoder_pad_mask: 对应的填充掩码(编码器输入的填充掩码)decoder_target_ids: 答案经过分词器转换得到的 Token ID 序列(解码器的目标输出)decoder_pad_mask: 答案对应的填充掩码(解码器输出的填充掩码)
from torch.utils.data import Dataset
class TextGenerationDataset(Dataset):
"""
文本生成任务的数据集类
用于处理序列到序列的文本生成任务,如加法计算等
"""
def __init__(
self,
questions,
answers,
encoder_transform: TextTransform,
decoder_transform: TextTransform,
):
"""
初始化数据集
Args:
questions: 输入问题列表
answers: 对应答案列表
encoder_transform: 编码器文本转换器
decoder_transform: 解码器文本转换器
"""
self.questions = questions # 存储输入问题列表
self.answers = answers # 存储对应答案列表
self.encoder_transform = encoder_transform # 编码器文本预处理工具
self.decoder_transform = decoder_transform # 解码器文本预处理工具
def __len__(self):
"""返回数据集大小"""
return len(self.questions)
def __getitem__(self, idx):
"""
获取指定索引的数据样本
Args:
idx: 样本索引
Returns:
dict: 包含处理后的输入输出数据的字典
"""
question = self.questions[idx] # 获取第idx个问题
answer = self.answers[idx] # 获取第idx个答案
# 对输入问题进行预处理
question_encoded = self.encoder_transform(question)
encoder_input_ids = question_encoded["input_ids"] # 编码器输入token ID序列
encoder_pad_mask = question_encoded["attention_mask"] # 编码器注意力掩码
# 对目标答案进行预处理
answer_encoded = self.decoder_transform(answer)
answer_ids = answer_encoded["input_ids"] # 解码器目标token ID序列
answer_pad_mask = answer_encoded["attention_mask"] # 解码器注意力掩码
# 返回完整的数据样本
return {
"question": question, # 原始问题文本
"answer": answer, # 原始答案文本
"encoder_input_ids": encoder_input_ids, # 编码器输入IDs
"encoder_pad_mask": encoder_pad_mask, # 编码器填充掩码
"decoder_target_ids": answer_ids, # 解码器目标IDs
"decoder_pad_mask": answer_pad_mask, # 解码器填充掩码
}
@classmethod
def from_file(
cls,
file_path,
encoder_transform: TextTransform,
decoder_transform: TextTransform,
):
"""
从txt文件加载数据集的类方法
Args:
file_path: 数据文件路径
encoder_transform: 编码器文本转换器
decoder_transform: 解码器文本转换器
Returns:
TextGenerationDataset: 数据集实例
Note:
txt格式应包含算式,使用等号分隔问题和答案
例如: "123+456=579"
"""
questions = [] # 存储解析出的问题
answers = [] # 存储解析出的答案
# 读取txt文件
with open(file_path, "r", encoding="utf-8") as f:
for line in f:
if line.strip() == "": # 跳过空行
continue
try:
# 查找等号的位置,将行分割为问题和答案
idx = line.find("=")
# 将样本添加到列表中: (question, answer),answer中去掉"="以及最后的"\n"
question = line[:idx] # 等号前的部分作为问题
answer = line[
idx + 1 :
].strip() # 等号后的部分作为答案(去除首尾空白)
questions.append(question)
answers.append(answer)
except Exception as e:
# 如果处理某行时出错,打印错误信息并跳过
print(f"Error processing line: {line}")
print(f"Error message: {e}")
continue
# 创建数据集实例
return cls(questions, answers, encoder_transform, decoder_transform)
13.5.5. 初始化数据模组#
加法数据模组继承自 LightningDataModule,用于统一管理训练、验证和测试数据集。
import lightning as L
from torch.utils.data import DataLoader
class TextDataModule(L.LightningDataModule):
"""
文本生成任务的数据模块
继承自LightningDataModule,用于管理训练、验证和测试数据的加载
"""
def __init__(
self,
batch_size,
encoder_transform: TextTransform,
decoder_transform: TextTransform,
train_data_file,
val_data_file="",
test_data_file="",
):
"""
初始化数据模块
Args:
batch_size: 批次大小
encoder_transform: 编码器文本转换器
decoder_transform: 解码器文本转换器
train_data_file: 训练数据文件路径
val_data_file: 验证数据文件路径(可选)
test_data_file: 测试数据文件路径(可选)
"""
super().__init__()
self.batch_size = batch_size # 设置批次大小
self.encoder_transform = encoder_transform # 编码器文本预处理转换器
self.decoder_transform = decoder_transform # 解码器文本预处理转换器
self.train_data_file = train_data_file # 训练数据文件路径
self.val_data_file = val_data_file # 验证数据文件路径
self.test_data_file = test_data_file # 测试数据文件路径
# 初始化数据集属性
self.test_dataset = None # 测试数据集
self.val_dataset = None # 验证数据集
self.train_dataset = None # 训练数据集
def prepare_data(self):
"""
准备数据的方法
用于下载数据集或进行一次性数据预处理操作
"""
pass
def setup(self, stage=None):
"""
设置数据集的方法
"""
# 加载训练数据集
self.train_dataset = TextGenerationDataset.from_file(
self.train_data_file,
encoder_transform=self.encoder_transform,
decoder_transform=self.decoder_transform,
)
# 加载验证数据集
if self.val_data_file == "":
# 如果没有指定验证集,则使用训练集作为验证集
self.val_dataset = self.train_dataset
else:
# 加载指定的验证数据集
self.val_dataset = TextGenerationDataset.from_file(
self.val_data_file,
encoder_transform=self.encoder_transform,
decoder_transform=self.decoder_transform,
)
# 加载测试数据集
if self.test_data_file == "":
# 如果没有指定测试集,则使用训练集作为测试集
self.test_dataset = self.train_dataset
else:
# 加载指定的测试数据集
self.test_dataset = TextGenerationDataset.from_file(
self.test_data_file,
encoder_transform=self.encoder_transform,
decoder_transform=self.decoder_transform,
)
def train_dataloader(self):
"""
返回训练数据加载器
Returns:
DataLoader: 训练数据的DataLoader对象
"""
return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
"""
返回验证数据加载器
Returns:
DataLoader: 验证数据的DataLoader对象
"""
return DataLoader(self.val_dataset, batch_size=self.batch_size)
def test_dataloader(self):
"""
返回测试数据加载器
Returns:
DataLoader: 测试数据的DataLoader对象
"""
return DataLoader(self.test_dataset, batch_size=self.batch_size)
13.6. 构建模型#
信息偷窥只作用于解码阶段,因此本次的改进只需要修改解码器。
13.6.1. 构建编码器#
import torch
class Encoder(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers=1):
super(Encoder, self).__init__()
# 词嵌入层
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
# GRU
self.gru = torch.nn.GRU(
input_size=embed_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
)
def forward(self, input_ids):
"""
前向传播
参数:
input_ids (Tensor): 输入序列的token IDs, shape: [batch_size, seq_len]
返回:
outputs (Tensor): 编码器所有时间步的输出, shape: [batch_size, seq_len, hidden_dim]
hidden (Tensor): 编码器最后时间步的隐藏状态, shape: [num_layers, batch_size, hidden_dim]
"""
embedded = self.embedding(input_ids)
outputs, hidden = self.gru(embedded)
return outputs, hidden
13.6.2. 构建解码器#
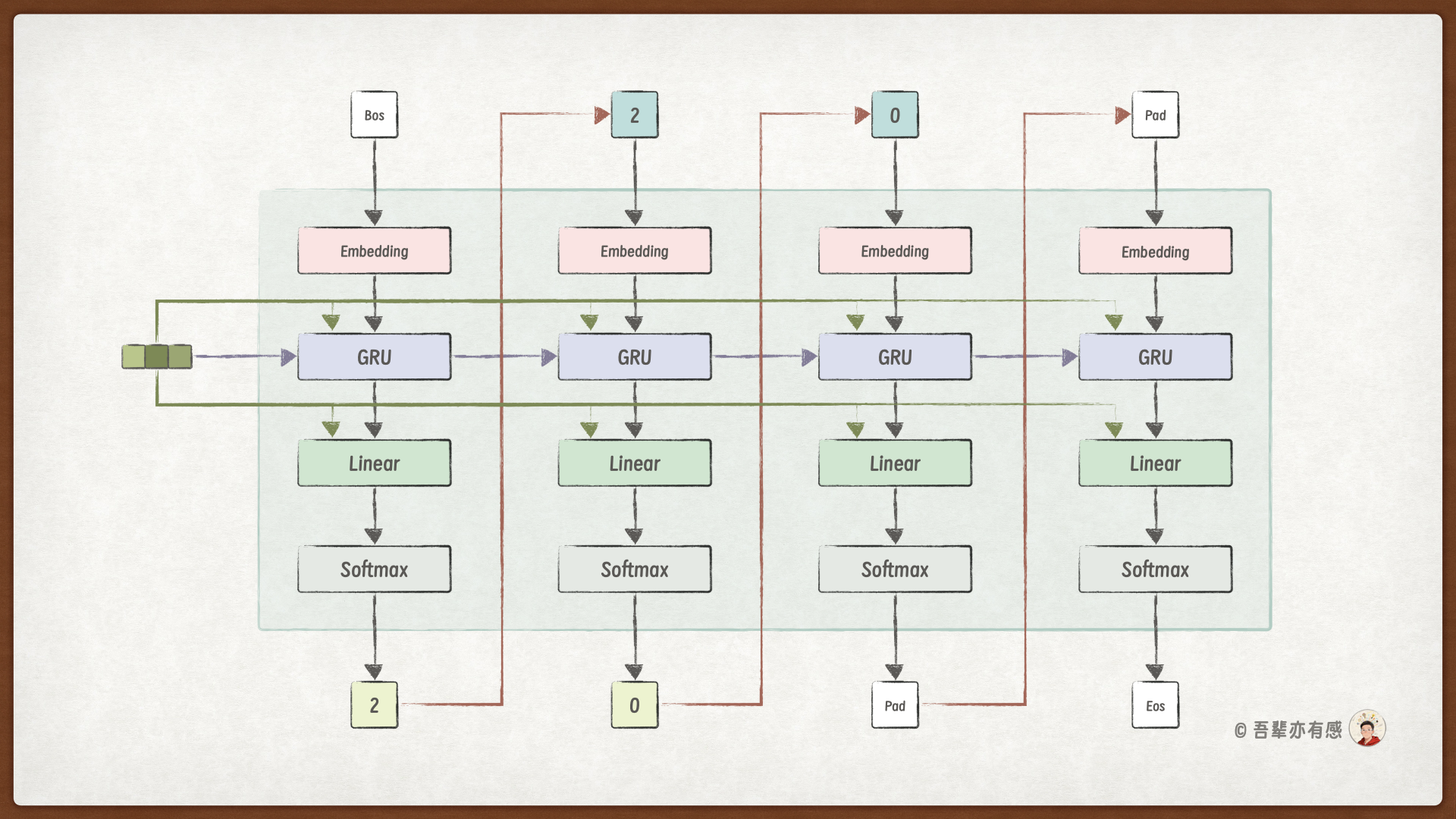
引入信息偷窥时,编码器在每个时间步解码的过程如下图所示:
从图中我们可以看到,引入信息偷窥需要对解码器做以下几点改动:
模型结构改动:
GRU 层:输入维度从
embed_dim扩充为embed_dim+hidden_dim输出层:输入维度从
hidden_dim扩充为hidden_dim+hidden_dim
前向计算
forward_step改动:GRU 层:需要拼接编码器最终输出的隐藏状态和词嵌入的结果,作为 GRU 层的输入
输出层:需要拼接编码器最终输出的隐藏状态和 GRU 层的输出,作为输出层的输入
其他部分保持不变,具体的实现代码如下。
class PeekDecoder(torch.nn.Module):
"""使用信息偷窥的解码器"""
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers=1):
super(PeekDecoder, self).__init__()
# 词嵌入层
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
# GRU解码器
self.gru = torch.nn.GRU(
input_size=embed_dim
+ hidden_dim, # GRU层:输入维度为 embed_dim + hidden_dim(🌟改进点🌟)
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
)
# 输出层:输入维度为hidden_dim + hidden_dim(🌟改进点🌟)
self.output_layer = torch.nn.Linear(
in_features=hidden_dim + hidden_dim, out_features=vocab_size
)
def forward(self, input_ids, encoder_hidden, encoder_output):
"""
前向传播 (用于训练,Teacher Forcing)
参数:
input_ids (Tensor): 目标序列的 token IDs, shape: [batch_size, tgt_seq_len]
encoder_hidden (Tensor): 编码器最后时间步的隐藏状态, shape: [num_layers, batch_size, hidden_dim]
这通常作为解码器初始隐藏状态。
encoder_output (Tensor): 编码器所有时间步的输出, shape: [batch_size, src_seq_len, hidden_dim]
用于提供全局上下文 ("peek")。
返回:
output_logits (Tensor): 每个时间步的词汇表分布, shape: [batch_size, tgt_seq_len, vocab_size]
decoder_hidden (Tensor): 解码器最后时间步的隐藏状态, shape: [num_layers, batch_size, hidden_dim]
"""
batch_size, tgt_seq_len = input_ids.size()
# 使用编码器最后的隐藏状态初始化解码器隐藏状态
decoder_hidden = encoder_hidden
outputs = []
# 循环遍历目标序列的每个时间步 (除了最后一个,因为没有下一个输入)
for t in range(tgt_seq_len):
# 取出当前时间步的输入 token ID
input_id = input_ids[:, t : t + 1] # Shape: [batch_size, 1]
# 调用 forward_step 处理单步
# 注意:我们需要将 encoder_output 传递给 forward_step,
# 或者在 forward_step 内部能够访问到它。
# 这里我们假设 forward_step 被修改为接受 encoder_output
output_logits_step, decoder_hidden = self.forward_step(
input_id, decoder_hidden, encoder_output
)
# 收集每一步的输出 logits (去掉序列长度维度 1)
outputs.append(
output_logits_step.squeeze(1)
) # Shape: [batch_size, vocab_size]
# 将所有时间步的输出堆叠起来
# outputs list contains tensors of [batch_size, vocab_size]
# After stack: [tgt_seq_len, batch_size, vocab_size]
# Transpose to: [batch_size, tgt_seq_len, vocab_size]
output_logits = torch.stack(outputs, dim=1)
return output_logits, decoder_hidden
def forward_step(self, input_id, decoder_hidden, encoder_output):
"""
单步解码:
- 输入:当前时间步的输入和隐藏状态
- 输出:当前时间步的输出和新的隐藏状态
"""
token_embed = self.embedding(input_id) # [batch_size, 1, embed_dim]
# 获取编码器最后一层的最后一个时间步的输出作为上下文向量
final_encoder_output = encoder_output[:, -1:, :] # [batch_size, 1, hidden_dim]
# 拼接编码器最终输出和词嵌入,作为 GRU 层的输入(🌟改进点🌟)
gru_input = torch.cat((token_embed, final_encoder_output), dim=-1)
output, decoder_hidden = self.gru(gru_input, decoder_hidden)
# 拼接编码器最终输出和GRU输出,作为输出层的输入(🌟改进点🌟)
output_with_context = torch.cat(
(output, final_encoder_output), dim=-1
) # [batch_size, 1, hidden_dim + hidden_dim]
output_logits = self.output_layer(output_with_context)
return output_logits, decoder_hidden
13.6.3. 构建完整的 Seq2Seq 模型#
使用 Encoder 和 PeekDecoder 构建完整的 Seq2Seq 模型。
13.6.3.1. Seq2Seq 加法计算模型的代码实现#
class SequenceGenerator(L.LightningModule):
def __init__(self, tokenizer: SimpleTokenizer, embed_dim, hidden_dim, num_layers=1, learning_rate=1e-3,
generate_max_length=4):
super().__init__()
# 实例化编码器和解码器
self.encoder = Encoder(tokenizer.vocab_size, embed_dim, hidden_dim, num_layers)
self.decoder = PeekDecoder(tokenizer.vocab_size, embed_dim, hidden_dim, num_layers) # 🌟改进点🌟:使用 PeekDecoder 代替原始的解码器
self.tokenizer = tokenizer
self.learning_rate = learning_rate
self.generate_max_length = generate_max_length # 添加最大长度属性
# 用于存储训练和验证过程中的指标
self.train_step_losses = []
self.train_epoch_losses = []
self.validation_step_outputs = []
self.validation_epoch_outputs = []
# 示例输入
self.example_input_array = (
torch.randint(0, tokenizer.vocab_size, (32, 10), dtype=torch.long),
torch.randint(0, tokenizer.vocab_size, (32, 5), dtype=torch.long)
)
def forward(self, input_ids, target_ids=None):
"""前向传播"""
batch_size = input_ids.size(0)
# 1. 编码阶段:提取输入序列特征
encoder_outputs, encoder_hidden = self.encoder(input_ids)
# 2. 解码阶段:生成输出序列
if target_ids is not None:
# 训练过程:使用真实目标序列作为输入(teacher forcing)
return self._decode_with_targets(encoder_outputs, encoder_hidden, target_ids, self.generate_max_length)
else:
# 推理过程:自回归生成序列
return self._decode_autoregressive(encoder_outputs, encoder_hidden, batch_size, self.generate_max_length)
def _decode_with_targets(self, encoder_outputs, encoder_hidden, target_ids, generate_max_length):
"""
训练阶段解码:使用teacher forcing
"""
batch_size = encoder_outputs.size(0)
# 初始化解码器输入为起始标记(这里假设用空格作为起始符,ID为12)
decoder_input = torch.full((batch_size, 1), self.tokenizer.bos_token_id, device=encoder_outputs.device,
dtype=torch.long)
decoder_hidden = encoder_hidden
decoder_outputs = []
# 使用目标序列作为输入,逐步解码
for i in range(generate_max_length):
# 🌟改进点🌟:在解码器解码时需要使用编码器的输出
decoder_output, decoder_hidden = self.decoder.forward_step(decoder_input, decoder_hidden, encoder_outputs)
decoder_outputs.append(decoder_output)
# 使用真实目标作为下一步输入
decoder_input = target_ids[:, i].unsqueeze(1)
# 拼接所有时间步的输出
decoder_outputs = torch.cat(decoder_outputs, dim=1)
return torch.nn.functional.log_softmax(decoder_outputs, dim=-1)
def _decode_autoregressive(self, encoder_outputs, encoder_hidden, batch_size, generate_max_length):
"""
推理阶段解码:自回归生成
"""
# 初始化解码器输入为起始标记
decoder_input = torch.full((batch_size, 1), self.tokenizer.bos_token_id,
device=encoder_outputs.device, dtype=torch.long)
decoder_hidden = encoder_hidden
decoder_outputs = []
for i in range(generate_max_length):
# 单步解码
# 🌟改进点🌟:在解码器解码时需要使用编码器的输出
decoder_output, decoder_hidden = self.decoder.forward_step(decoder_input, decoder_hidden, encoder_outputs)
decoder_outputs.append(decoder_output)
# 使用模型预测作为下一步输入
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach()
# 拼接所有时间步的输出
decoder_outputs = torch.cat(decoder_outputs, dim=1)
return torch.nn.functional.log_softmax(decoder_outputs, dim=-1)
def training_step(self, batch, batch_idx):
"""训练步骤"""
input_ids = batch["encoder_input_ids"]
target_ids = batch["decoder_target_ids"]
# 前向传播
outputs = self(input_ids, target_ids) # 训练时传入target_ids
# 计算损失 - 需要调整维度以适应交叉熵损失
# outputs: [batch_size, seq_len, vocab_size]
# target_ids: [batch_size, seq_len]
loss = torch.nn.functional.cross_entropy(
outputs.view(-1, outputs.size(-1)),
target_ids.view(-1)
)
"""
对于序列生成任务,通常我们会采用以下几种方式来计算准确率:
1. 序列级别准确率:整个生成序列完全匹配目标序列才算正确
2. token级别准确率:计算所有token中预测正确的比例
3. BLEU/ROUGE等评价指标:更复杂的文本生成评价指标
"""
# 计算token级别的准确率
preds = torch.argmax(outputs, dim=-1)
mask = (target_ids != self.tokenizer.pad_token_id) # 忽略填充位置
correct_tokens = ((preds == target_ids) & mask).sum().float()
total_tokens = mask.sum().float()
token_acc = correct_tokens / total_tokens
# 计算序列级别的准确率
# 对于每个序列,只有当所有非填充位置都预测正确才算正确
seq_correct = ((preds == target_ids) | ~mask).all(dim=1).float().mean()
# 记录日志
self.log('train_loss', loss)
self.log('train_token_acc', token_acc)
self.log('train_seq_acc', seq_correct)
# 存储损失以便后续使用
self.train_step_losses.append(loss.detach())
return loss
def validation_step(self, batch, batch_idx):
"""验证步骤"""
input_ids = batch["encoder_input_ids"]
target_ids = batch["decoder_target_ids"]
# 前向传播
outputs = self(input_ids)
# 计算预测值
preds = torch.argmax(outputs, dim=-1)
# 创建掩码以忽略填充值
mask = (target_ids != self.tokenizer.pad_token_id)
# 计算token级别的准确率
correct_tokens = ((preds == target_ids) & mask).sum().float()
total_tokens = mask.sum().float()
token_acc = correct_tokens / total_tokens if total_tokens > 0 else torch.tensor(0.0)
# 计算序列级别的准确率
seq_correct = ((preds == target_ids) | ~mask).all(dim=1).float().mean()
# 保存结果供epoch结束时使用
self.validation_step_outputs.append({
'preds': preds,
'target_ids': target_ids,
'token_acc': token_acc,
'seq_acc': seq_correct
})
if batch_idx % 50 == 0:
print(
f"Validation Step {batch_idx}: Token Accuracy={token_acc.item():.4f}, Seq Accuracy={seq_correct.item():.4f}")
def on_train_epoch_end(self):
"""在每个训练epoch结束时计算整体损失"""
if self.train_step_losses: # 确保列表不为空
# 计算并记录平均训练损失
avg_train_loss = torch.stack(self.train_step_losses).mean()
self.train_epoch_losses.append({
"epoch": self.current_epoch,
"loss": avg_train_loss.item() # 转换为 Python 数值
})
# 清空列表为下一个 epoch 做准备
self.train_step_losses.clear()
def on_validation_epoch_end(self):
"""在每个验证epoch结束时计算整体准确率"""
# 汇总所有预测结果和标签
all_preds = torch.cat([x['preds'] for x in self.validation_step_outputs])
all_target_ids = torch.cat([x['target_ids'] for x in self.validation_step_outputs])
# 1. 计算序列(样本)级别的准确率
# 创建掩码以标识非填充位置
mask = (all_target_ids != self.tokenizer.pad_token_id)
# 计算每个序列是否完全正确(所有非填充位置都预测正确)
seq_correct = ((all_preds == all_target_ids) | ~mask).all(dim=1)
# 序列总数
total_sequences = all_preds.size(0)
# 正确预测的序列数
correct_sequences = seq_correct.sum().item()
# 序列级别准确率
seq_acc = correct_sequences / total_sequences if total_sequences > 0 else 0.0
# 2. 计算 Token 级别的准确率
# 计算所有非填充位置的预测总数
total_tokens = mask.sum().item()
# 计算所有非填充位置预测正确的总数
correct_tokens = ((all_preds == all_target_ids) & mask).sum().item()
# Token 级别准确率
token_acc = correct_tokens / total_tokens if total_tokens > 0 else 0.0
# 3. 将评估结果保存到 validation_epoch_outputs 列表中
self.validation_epoch_outputs.append({
"epoch": self.current_epoch,
"总样本数": total_sequences,
"正确样本数": correct_sequences,
"样本准确率": round(seq_acc, 4),
"总Token数": total_tokens,
"正确Token数": correct_tokens,
"Token准确率": round(token_acc, 4)
})
# 记录日志
self.log('total_sequences', total_sequences)
self.log('correct_sequences', correct_sequences)
self.log('seq_acc', seq_acc)
self.log('total_tokens', total_tokens)
self.log('correct_tokens', correct_tokens)
self.log('token_acc', token_acc)
# 清空缓存
self.validation_step_outputs.clear()
def clear_cache(self):
"""清除缓存"""
self.train_step_losses.clear()
self.train_epoch_losses.clear()
self.validation_step_outputs.clear()
self.validation_epoch_outputs.clear()
def configure_optimizers(self):
"""配置优化器"""
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
def generate(self, input_ids):
"""
根据输入序列生成输出序列文本
参数:
input_ids (Tensor): 输入序列的token IDs, shape: [batch_size, seq_len]
返回:
generated_texts (list): 生成的文本列表
"""
# 1. 调用模型的 forward 方法 (推理模式,无 target_ids) 生成 logits
generated_logits = self(input_ids) # Shape: [batch_size, generate_max_length, vocab_size]
# 2. 获取概率最高的 token ID
generated_ids = torch.argmax(generated_logits, dim=-1) # Shape: [batch_size, generate_max_length]
# 3. 直接使用 tokenizer.decode 方法将 token ID 转换为文本
generated_texts = []
for i in range(generated_ids.size(0)): # 遍历 batch 中的每个样本
# 调用 tokenizer 的 decode 方法,并跳过特殊 token
text = self.tokenizer.decode(generated_ids[i], skip_special_tokens=True)
generated_texts.append(text)
return generated_texts
13.6.3.2. 查看 Seq2Seq 加法计算模型的详细信息#
from lightning.pytorch.utilities.model_summary import ModelSummary
# 创建加法计算模型实例:词嵌入维度128,隐藏层维度128
model = SequenceGenerator(tokenizer, embed_dim=128, hidden_dim=128)
# 使用 ModelSummary 获取模型详细信息
summary = ModelSummary(model, max_depth=-1)
print(summary)
| Name | Type | Params | Mode | FLOPs | In sizes | Out sizes
-------------------------------------------------------------------------------------------------------------------------------------
0 | encoder | Encoder | 101 K | train | 62.9 M | [32, 10] | [[32, 10, 128], [1, 32, 128]]
1 | encoder.embedding | Embedding | 2.0 K | train | 0 | [32, 10] | [32, 10, 128]
2 | encoder.gru | GRU | 99.1 K | train | 62.9 M | [32, 10, 128] | [[32, 10, 128], [1, 32, 128]]
3 | decoder | PeekDecoder | 154 K | train | 0 | ? | ?
4 | decoder.embedding | Embedding | 2.0 K | train | 0 | [32, 1] | [32, 1, 128]
5 | decoder.gru | GRU | 148 K | train | 37.7 M | [[32, 1, 256], [1, 32, 128]] | [[32, 1, 128], [1, 32, 128]]
6 | decoder.output_layer | Linear | 4.1 K | train | 1.0 M | [32, 1, 256] | [32, 1, 16]
-------------------------------------------------------------------------------------------------------------------------------------
255 K Trainable params
0 Non-trainable params
255 K Total params
1.022 Total estimated model params size (MB)
7 Modules in train mode
0 Modules in eval mode
101 M Total Flops
从模型详细信息中,我们可以看 decoder.gru 和 decoder.output_layer 层的输入维度参数与我们预期的一致。从 [32, 1, 128] 扩充到了 [32, 128, 256],因为我们将嵌入维度和隐藏维度都设置为了 128。
虽然这两个层的输入维度都是 256,但它们的含义却不同。
decoder.gru层:[batch_size, seq_len, embed_dim + hidden_dim]decoder.output_layer层:[batch_size, seq_len, hidden_dim + hidden_dim]
13.7. 模型训练与评估#
13.7.1. 初始化模型和训练器#
# 超参配置
batch_size = 50
encoder_max_length = 7
decoder_max_length = 4
# 1️⃣ 初始化分词器
tokenizer = SimpleTokenizer(vocab)
# 2️⃣ 初始化编码器和解码器的数据转换
encoder_transform = TextTransform(tokenizer, max_length=encoder_max_length, is_reverse=True)
decoder_transform = TextTransform(tokenizer, max_length=decoder_max_length)
# 3️⃣ 加载数据模组
train_data_file = "./dataset/addition_train.txt"
val_data_file = "./dataset/addition_val.txt"
# 此处的直接使用评估集进行评估
datamodule = TextDataModule(batch_size=batch_size, encoder_transform=encoder_transform,
decoder_transform=decoder_transform, train_data_file=train_data_file, val_data_file=val_data_file)
# 4️⃣ 初始化模型
model = SequenceGenerator(tokenizer, embed_dim=128, hidden_dim=128)
# 5️⃣ 初始化训练器
# max_epochs=12: 最大训练轮数为12
# log_every_n_steps=3: 每3个步骤记录一次日志
# check_val_every_n_epoch=1: 每1个epoch进行一次验证
# num_sanity_val_steps=0: 验证集的初始检查次数,设置为0表示不进行初始检查
# enable_progress_bar=False: 不显示进度条
trainer = L.Trainer(max_epochs=12, log_every_n_steps=3, check_val_every_n_epoch=1, num_sanity_val_steps=0,
enable_progress_bar=False)
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
13.7.2. 训练前评估#
训练前评估为模型性能建立初始性能基准。
# 直接调用验证函数进行训练前评估
trainer.validate(model=model, datamodule=datamodule)
💡 Tip: For seamless cloud uploads and versioning, try installing [litmodels](https://pypi.org/project/litmodels/) to enable LitModelCheckpoint, which syncs automatically with the Lightning model registry.
/Users/kong/opt/anaconda3/envs/dsx-ai/lib/python3.12/site-packages/lightning/pytorch/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Validation Step 0: Token Accuracy=0.0318, Seq Accuracy=0.0000
Validation Step 50: Token Accuracy=0.0440, Seq Accuracy=0.0000
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Validate metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ correct_sequences │ 2.0 │ │ correct_tokens │ 573.0 │ │ seq_acc │ 0.00039999998989515007 │ │ token_acc │ 0.036464300006628036 │ │ total_sequences │ 5000.0 │ │ total_tokens │ 15714.0 │ └───────────────────────────┴───────────────────────────┘
[{'total_sequences': 5000.0,
'correct_sequences': 2.0,
'seq_acc': 0.00039999998989515007,
'total_tokens': 15714.0,
'correct_tokens': 573.0,
'token_acc': 0.036464300006628036}]
在评估集的 5000 条数据上,只有 2 个样本的预测结果正确,模型训练前预测正确率为 0.03%,不具备预测效果。
13.7.3. 训练模型#
调用 trainer.fit() 训练 12 个轮次。
model.clear_cache()
trainer.fit(model=model, datamodule=datamodule)
┏━━━┳━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ 0 │ encoder │ Encoder │ 101 K │ train │ 62.9 M │ [32, 10] │ [[32, 10, 128], [1, 32, 128]] │ │ 1 │ decoder │ PeekDecoder │ 154 K │ train │ 0 │ ? │ ? │ └───┴─────────┴─────────────┴────────┴───────┴────────┴──────────┴───────────────────────────────┘
Trainable params: 255 K Non-trainable params: 0 Total params: 255 K Total estimated model params size (MB): 1 Modules in train mode: 7 Modules in eval mode: 0 Total FLOPs: 101 M
Validation Step 0: Token Accuracy=0.5032, Seq Accuracy=0.1000
Validation Step 50: Token Accuracy=0.4591, Seq Accuracy=0.0200
Validation Step 0: Token Accuracy=0.5860, Seq Accuracy=0.1400
Validation Step 50: Token Accuracy=0.6038, Seq Accuracy=0.2200
Validation Step 0: Token Accuracy=0.6815, Seq Accuracy=0.4200
Validation Step 50: Token Accuracy=0.6352, Seq Accuracy=0.2800
Validation Step 0: Token Accuracy=0.8153, Seq Accuracy=0.6400
Validation Step 50: Token Accuracy=0.7736, Seq Accuracy=0.5600
Validation Step 0: Token Accuracy=0.8981, Seq Accuracy=0.7600
Validation Step 50: Token Accuracy=0.8616, Seq Accuracy=0.6800
Validation Step 0: Token Accuracy=0.9490, Seq Accuracy=0.8600
Validation Step 50: Token Accuracy=0.9308, Seq Accuracy=0.8400
Validation Step 0: Token Accuracy=0.9554, Seq Accuracy=0.9000
Validation Step 50: Token Accuracy=0.9119, Seq Accuracy=0.8000
Validation Step 0: Token Accuracy=0.9427, Seq Accuracy=0.8800
Validation Step 50: Token Accuracy=0.9497, Seq Accuracy=0.9000
Validation Step 0: Token Accuracy=1.0000, Seq Accuracy=1.0000
Validation Step 50: Token Accuracy=0.9371, Seq Accuracy=0.8400
Validation Step 0: Token Accuracy=0.9873, Seq Accuracy=0.9600
Validation Step 50: Token Accuracy=0.9497, Seq Accuracy=0.8800
Validation Step 0: Token Accuracy=0.9745, Seq Accuracy=0.9400
Validation Step 50: Token Accuracy=0.9623, Seq Accuracy=0.9200
Validation Step 0: Token Accuracy=0.9936, Seq Accuracy=0.9800
Validation Step 50: Token Accuracy=0.9748, Seq Accuracy=0.9200
`Trainer.fit` stopped: `max_epochs=12` reached.
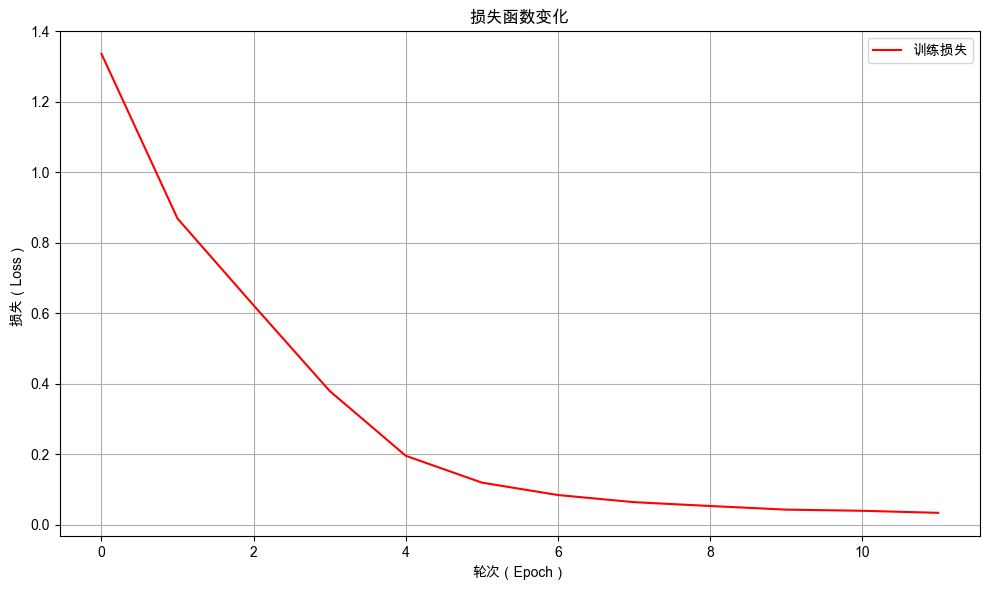
13.7.3.1. 训练过程可视化#
绘制训练过程中损失值的变化曲线。
from dsxllm.util import plot_loss_curves
plot_loss_curves(model.train_epoch_losses)
13.7.3.2. 查看模型评估记录#
查看训练过程中的评估结果,观察模型在验证集上的表现。
from dsxllm.util import to_dataframe
to_dataframe(model.validation_epoch_outputs)
| epoch | 总样本数 | 正确样本数 | 样本准确率 | 总Token数 | 正确Token数 | Token准确率 | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 5000 | 329 | 0.0658 | 15714 | 7973 | 0.5074 |
| 1 | 1 | 5000 | 829 | 0.1658 | 15714 | 9381 | 0.5970 |
| 2 | 2 | 5000 | 1988 | 0.3976 | 15714 | 11063 | 0.7040 |
| 3 | 3 | 5000 | 3237 | 0.6474 | 15714 | 12960 | 0.8247 |
| 4 | 4 | 5000 | 3983 | 0.7966 | 15714 | 14221 | 0.9050 |
| 5 | 5 | 5000 | 4228 | 0.8456 | 15714 | 14601 | 0.9292 |
| 6 | 6 | 5000 | 4411 | 0.8822 | 15714 | 14905 | 0.9485 |
| 7 | 7 | 5000 | 4525 | 0.9050 | 15714 | 15076 | 0.9594 |
| 8 | 8 | 5000 | 4591 | 0.9182 | 15714 | 15191 | 0.9667 |
| 9 | 9 | 5000 | 4646 | 0.9292 | 15714 | 15262 | 0.9712 |
| 10 | 10 | 5000 | 4683 | 0.9366 | 15714 | 15297 | 0.9735 |
| 11 | 11 | 5000 | 4613 | 0.9226 | 15714 | 15235 | 0.9695 |
13.7.4. 训练后评估#
与训练前的评估结果对比,确认模型训练效果是否有效。
# 直接调用验证函数进行训练前评估
trainer.validate(model=model, datamodule=datamodule)
/Users/kong/opt/anaconda3/envs/dsx-ai/lib/python3.12/site-packages/lightning/pytorch/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
Validation Step 0: Token Accuracy=0.9936, Seq Accuracy=0.9800
Validation Step 50: Token Accuracy=0.9748, Seq Accuracy=0.9200
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Validate metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ correct_sequences │ 4613.0 │ │ correct_tokens │ 15235.0 │ │ seq_acc │ 0.9225999712944031 │ │ token_acc │ 0.9695176482200623 │ │ total_sequences │ 5000.0 │ │ total_tokens │ 15714.0 │ └───────────────────────────┴───────────────────────────┘
[{'total_sequences': 5000.0,
'correct_sequences': 4613.0,
'seq_acc': 0.9225999712944031,
'total_tokens': 15714.0,
'correct_tokens': 15235.0,
'token_acc': 0.9695176482200623}]
这次模型训练后,5000 条评估数据有 4613 个样本的预测结果正确,模型训练后预测正确率从之前的 27.03% 提升为 92.25%,说明模型训练有效,进步非常巨大。
13.8. 使用模型进行预测#
使用一些测试算式进行推理预测,直观观察模型的预测效果。
from dsxllm.util import print_generation_predictions
# 1️⃣ 创建一些测试问题和答案
questions = ["829+33", "58+136", "22+593", "243+269", "1+1"]
answers = ["862", "194", "615", "512", "2"]
# 2️⃣ 使用与训练时统一的编码器 transform 方法对输入进行处理
question_encoded = encoder_transform(questions)
encoder_input_ids = question_encoded["input_ids"]
# 3️⃣ 使用模型进行预测
generated_texts = model.generate(encoder_input_ids)
# 4️⃣ 输出预测结果
print_generation_predictions(questions, answers, generated_texts)
🎯 生成结果 (准确率: 5/5 = 100.00%):
+---------+--------+--------+------+
| 输入 | 真实值 | 预测值 | 标记 |
+---------+--------+--------+------+
| 829+33 | 862 | 862 | ☑ |
| 58+136 | 194 | 194 | ☑ |
| 22+593 | 615 | 615 | ☑ |
| 243+269 | 512 | 512 | ☑ |
| 1+1 | 2 | 2 | ☑ |
+---------+--------+--------+------+
本次的加法计算模型在测试示例上,预测正确率达到了 100%,终于有些效果了。那么,为什么信息偷窥会如此有效呢?
思考一下:偷窥信息为何有效?
“偷窥信息”在解码器生成每个输出时,不仅能利用解码器当前的隐藏状态和上下文向量,还允许重复查看编码的编码信息。信息偷窥提高了信息利用效率。
13.9. 本章小结#
恭喜,你已经将加法计算模型的准确率提升到了 92.25%。从这两次对 Seq2Seq 模型的改进中可以看到:优化信息的传递效率和利用效率能非常有效的提升 Seq2Seq 模型的生成效果。
虽然我们将加法计算模型提升到了接近 95% 的准确率,但循环神经网络按时间步有序计算的固有困境是无法突破的,针对更长的输入提取隐藏特征的效果会逐渐变差,而 Transformer 模型则从根本上解决循环神经网络的这一问题,对信息的传递效率和利用效率有了质的提升。
下一章,我们将正式步入大语言模型的领域,揭开 Transformer 的神秘面纱。
13.10. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。