
1. 从零开始:机器何以学习?#
🍋 这是从一杯柠檬水开始的机器学习之旅。通过本次任务,你将学会不借助任何工具从零手动训练一个机器学习模型。
1.1. 任务背景#
你是一名程序员。最近发现,每到夏天,街边的柠檬水摊前总是大排长龙。你不禁想:如果能造一个机器人自动制作柠檬水,不就能开一家24小时无人摊位,带来持续的收入吗?
但关键是如何确定柠檬片和糖的比例——你和机器人都对此一无所知。幸好你的好友小美是城里最受欢迎的柠檬水摊主。她答应担任“柠檬水专家”,帮你训练机器人。
那么,问题来了,如何让机器人学会她制作柠檬水的秘诀呢?
聪明的你很快找到一个方法:
先请小美做一杯完美的柠檬水作为示范。
让机器人随机猜测一个柠檬与糖的配比(可以叫做
糖权),并试着做一杯。将机器人做的柠檬水与小美的进行对比。
如果太甜了就减小一点糖权,如果太酸了就增大一点糖权。
重复上面的步骤,最终就能学到小美制作柠檬水的秘诀了。
你已经掌握了机器学习的基本原理,现在开始你的机器学习之旅吧!
1.2. 最少必要知识#
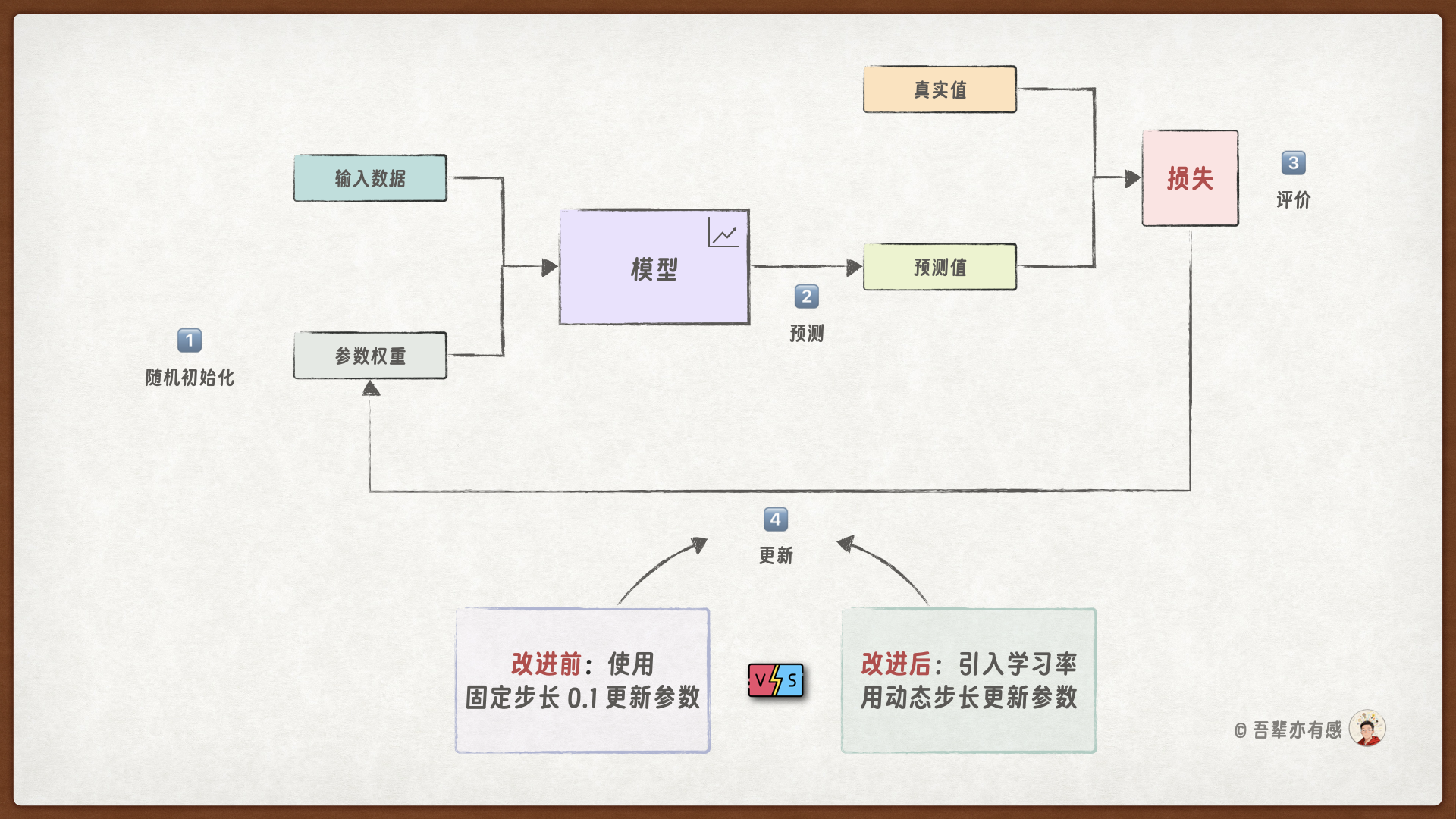
机器学习的基本流程
1.3. 任务鸟瞰#
1.3.1. 模型结构#
本次任务是训练一个模型,能够根据柠檬片数量预测糖的用量。模型结构如下:
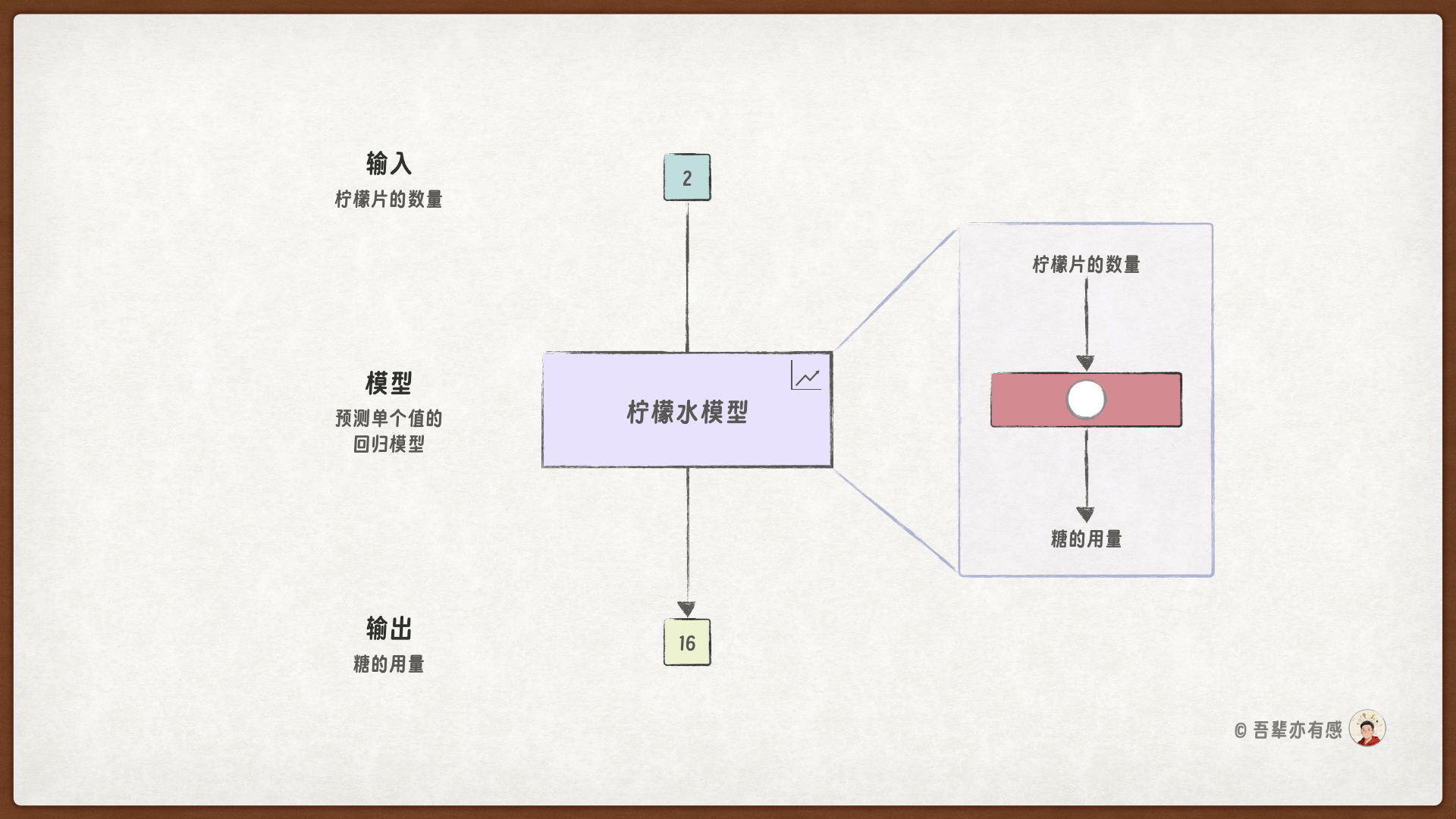
本次的模型是一个非常简单的回归模型,它只有一个输入(柠檬片数量)、一个参数(糖权)以及一个输出(糖的用量)。
开发一个机器学习模型通常遵循以下四个步骤:准备数据、模型定义、模型训练与模型评估等过程。下文将依此流程组织内容。
1.4. 环境配置#
在开始之前,我们先打印环境的版本号,避免因为环境不同而导致程序不能复现。
1.4.1. 安装依赖#
!pip install --upgrade dsxllm
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: dsxllm in /Users/kong/opt/anaconda3/envs/dsx-ai/lib/python3.12/site-packages (0.1.6)
1.4.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
1.5. 准备数据#
小美用 2 片柠檬片和 16 克糖做了一杯好喝的柠檬水。这杯成品既是一次完美的示范,也构成了我们模型的训练数据。
from dsxllm.util import print_table
# 准备训练数据
lemon = 2
sugar = 16
print_table(
f"训练数据",
["柠檬片(输入数据)", "放糖量(结果标签)"],
[[lemon, sugar]]
)
训练数据:
+--------------------+--------------------+
| 柠檬片(输入数据) | 放糖量(结果标签) |
+--------------------+--------------------+
| 2 | 16 |
+--------------------+--------------------+
1.6. 模型定义#
为机器人创建了一个名为 Model 的模型,这个模型只有一个参数 sugar_weight,用于表示每片柠檬片所对应的放糖量,我们把它称为糖权。
Model 的模型的类图如下:
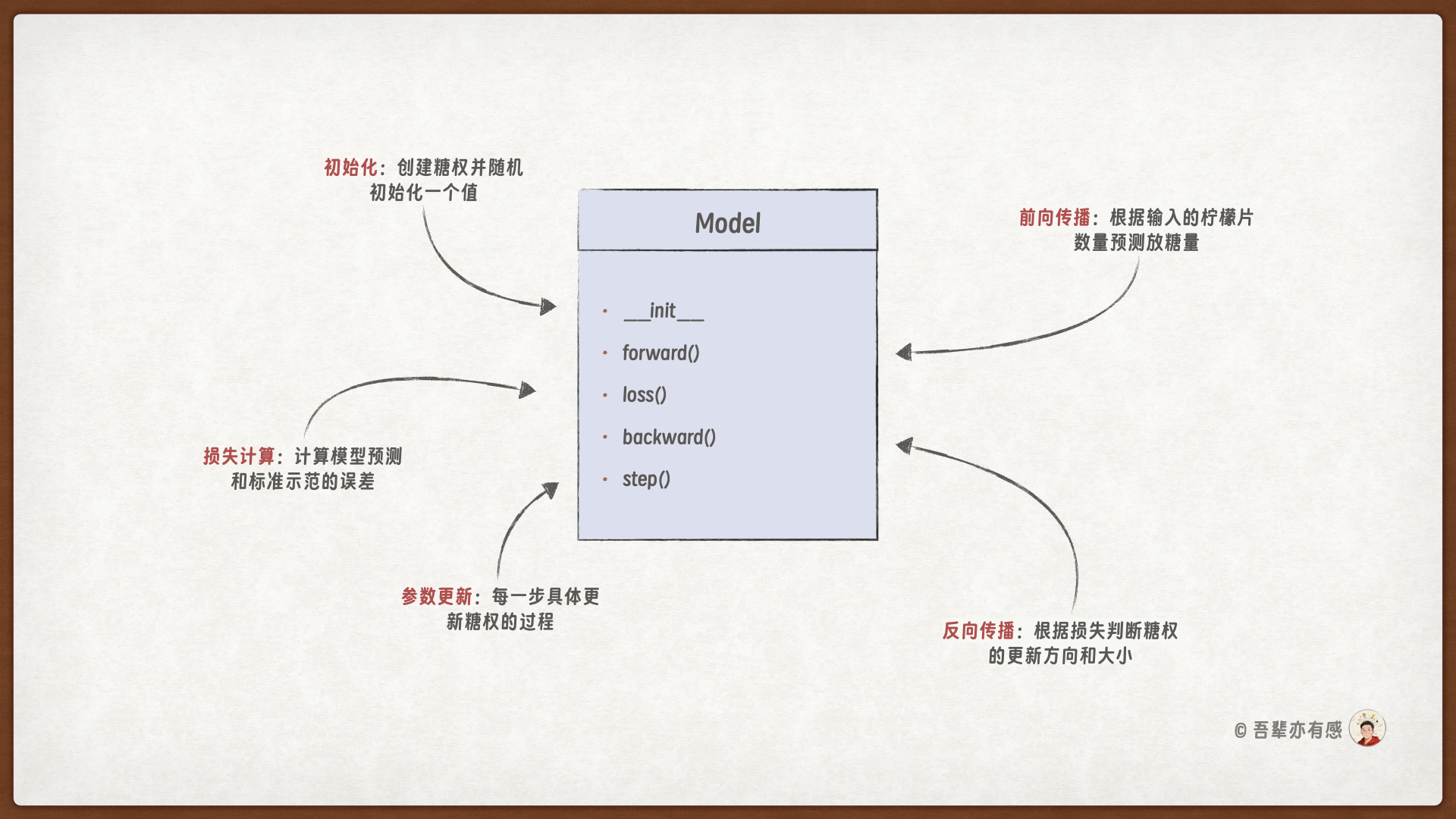
1.6.1. 柠檬水模型的代码实现#
import random
class Model:
def __init__(self):
# self.sugar_weight = random.uniform(0, 10)
# ❗️此处为了演示,将初始值固定为1.88,避免每次运行结果不一致
self.sugar_weight = 1.88
print(f"🚀 随机初始化的糖权: {self.sugar_weight}")
# 1️⃣ 计算模型预测值
def forward(self, lemon):
return self.sugar_weight * lemon
# 2️⃣ 计算模型预测和实际值之间的误差
def loss(self, pred_sugar, real_sugar):
return pred_sugar - real_sugar
# 3️⃣ 计算更新参数的方向和步长
def backward(self, loss):
if loss > 0:
# 如果损失值大于0,表示预测值偏大
return -0.1
elif loss < 0:
# 如果损失值小于0,表示预测值偏小
return 0.1
# 4️⃣ 更新糖权
def step(self, step):
self.sugar_weight += step
其中:
loss()函数直接使用预测的糖量直接减去真实的糖量,作为误差损失loss。backward()函数根据误差损失,判断参数更新方向,并返回更新步长。当
loss > 0,表示预测值偏大,需要减小参数的值,即更新参数的量为-0.1。当
loss < 0,表示预测值偏小,需要增大参数的值,即更新参数的量为0.1。
1.7. 模型训练#
创建一个模型实例,并开始训练。模型训练的目标是让计算机通过数据和对应的答案,从中自动学习到使其成立的规律和模式。
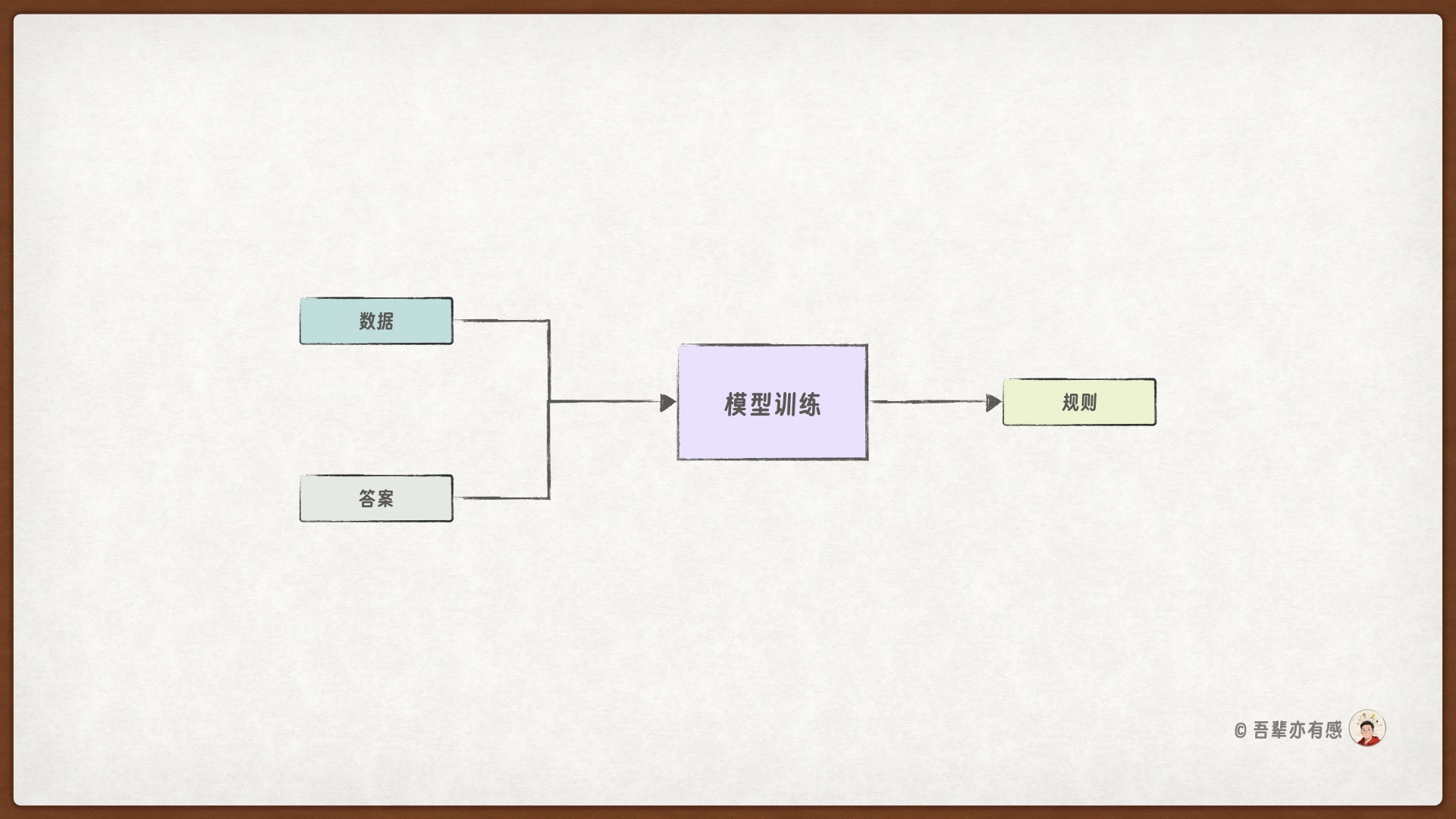
1.7.1. 模型训练的过程#
模型训练的循环过程分为四步,如下图所示:
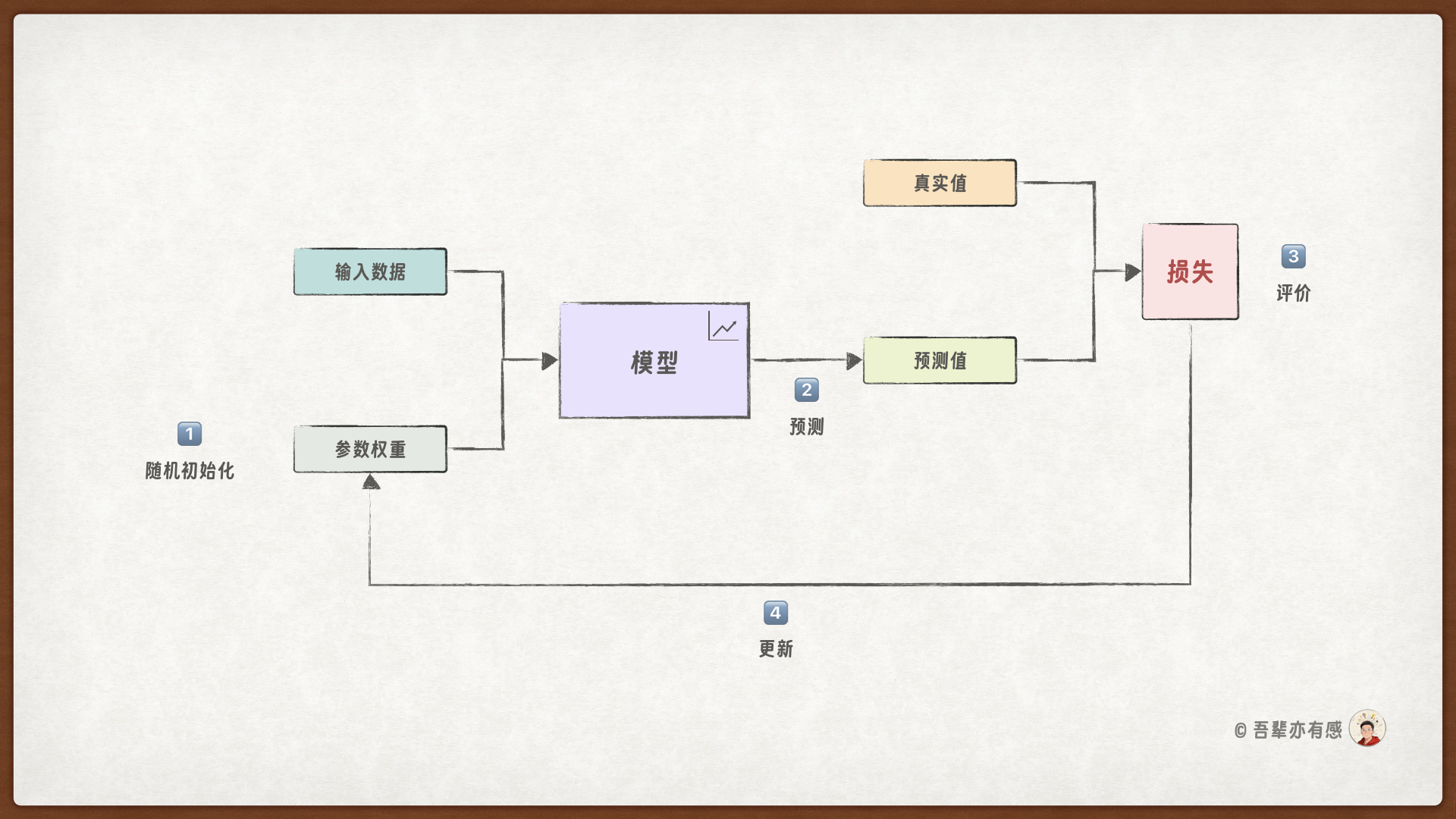
初始化模型:创建一个模型实例,并随机初始化参数权重。
模型预测:调用
forward()根据输入计算模型的预测结果。性能评价:通过
loss()计算模型预测值与真实值之间的误差损失,评价模型性能。权重更新:调用
backward()根据损失计算参数更新量,使用step()更新参数权重。
重复 2~4 步的循环进行训练,直到模型性能满足要求,在训练的过程中可以记录训练日志,用于追踪训练过程。
每完成一次训练循环,我们称之为一个轮次,也就是 epoch。
下面我们对柠檬水模型进行 100 个轮次的训练,查看模型学习的效果。
1.7.2. 模型训练的代码实现#
# 训练模型
# 创建模型实例
model = Model()
training_logs = []
# 训练模型
for epoch in range(100):
# 1. 使用模型进行预测
pred = model.forward(lemon)
# 2. 计算模型预测与真实值之间的误差
loss = model.loss(pred, sugar)
# 3. 计算参数更新的方向和步长
step = model.backward(loss)
# 4. 更新模型的参数
model.step(step)
# 记录训练日志,包括更新之后的权重(保留四位小数)
# 按照表头顺序调整:Epoch, 柠檬片数量, 当前糖权, 预测放糖量, 目标放糖量, 误差, 更新步长, 更新后权重
if epoch < 5 or epoch > 95 or epoch % 5 == 0:
training_logs.append([
epoch,
lemon,
round(model.sugar_weight - step, 4),
round(pred, 4),
sugar,
round(loss, 4),
round(step, 4),
round(model.sugar_weight, 4)
])
# 打印最终参数
print(f"✅ 模型学习到的糖权: {round(model.sugar_weight, 4)}\n")
print_table("📝 训练日志",
["Epoch", "柠檬片", "当前的糖权", "预测放糖量", "目标放糖量", "误差", "更新步长", "更新后糖权"],
training_logs)
🚀 随机初始化的糖权: 1.88
✅ 模型学习到的糖权: 8.08
📝 训练日志:
+-------+--------+------------+------------+------------+--------+----------+------------+
| Epoch | 柠檬片 | 当前的糖权 | 预测放糖量 | 目标放糖量 | 误差 | 更新步长 | 更新后糖权 |
+-------+--------+------------+------------+------------+--------+----------+------------+
| 0 | 2 | 1.88 | 3.76 | 16 | -12.24 | 0.1 | 1.98 |
| 1 | 2 | 1.98 | 3.96 | 16 | -12.04 | 0.1 | 2.08 |
| 2 | 2 | 2.08 | 4.16 | 16 | -11.84 | 0.1 | 2.18 |
| 3 | 2 | 2.18 | 4.36 | 16 | -11.64 | 0.1 | 2.28 |
| 4 | 2 | 2.28 | 4.56 | 16 | -11.44 | 0.1 | 2.38 |
| 5 | 2 | 2.38 | 4.76 | 16 | -11.24 | 0.1 | 2.48 |
| 10 | 2 | 2.88 | 5.76 | 16 | -10.24 | 0.1 | 2.98 |
| 15 | 2 | 3.38 | 6.76 | 16 | -9.24 | 0.1 | 3.48 |
| 20 | 2 | 3.88 | 7.76 | 16 | -8.24 | 0.1 | 3.98 |
| 25 | 2 | 4.38 | 8.76 | 16 | -7.24 | 0.1 | 4.48 |
| 30 | 2 | 4.88 | 9.76 | 16 | -6.24 | 0.1 | 4.98 |
| 35 | 2 | 5.38 | 10.76 | 16 | -5.24 | 0.1 | 5.48 |
| 40 | 2 | 5.88 | 11.76 | 16 | -4.24 | 0.1 | 5.98 |
| 45 | 2 | 6.38 | 12.76 | 16 | -3.24 | 0.1 | 6.48 |
| 50 | 2 | 6.88 | 13.76 | 16 | -2.24 | 0.1 | 6.98 |
| 55 | 2 | 7.38 | 14.76 | 16 | -1.24 | 0.1 | 7.48 |
| 60 | 2 | 7.88 | 15.76 | 16 | -0.24 | 0.1 | 7.98 |
| 65 | 2 | 7.98 | 15.96 | 16 | -0.04 | 0.1 | 8.08 |
| 70 | 2 | 8.08 | 16.16 | 16 | 0.16 | -0.1 | 7.98 |
| 75 | 2 | 7.98 | 15.96 | 16 | -0.04 | 0.1 | 8.08 |
| 80 | 2 | 8.08 | 16.16 | 16 | 0.16 | -0.1 | 7.98 |
| 85 | 2 | 7.98 | 15.96 | 16 | -0.04 | 0.1 | 8.08 |
| 90 | 2 | 8.08 | 16.16 | 16 | 0.16 | -0.1 | 7.98 |
| 95 | 2 | 7.98 | 15.96 | 16 | -0.04 | 0.1 | 8.08 |
| 96 | 2 | 8.08 | 16.16 | 16 | 0.16 | -0.1 | 7.98 |
| 97 | 2 | 7.98 | 15.96 | 16 | -0.04 | 0.1 | 8.08 |
| 98 | 2 | 8.08 | 16.16 | 16 | 0.16 | -0.1 | 7.98 |
| 99 | 2 | 7.98 | 15.96 | 16 | -0.04 | 0.1 | 8.08 |
+-------+--------+------------+------------+------------+--------+----------+------------+
从小美的示范中我们可以看到,符合当地口味的最佳糖权是 8.0,这一点模型是不知道的,模型学习的目标就是找到这个隐藏的糖权。
假设我们的模型猜测的最初糖权是 1.88 克,每个训练轮次只让模型更新 0.1 克的糖权。我们来看一下具体的过程:
机器人做的第 1 杯柠檬水,使用的糖权是
1.88克,放了3.76克的糖经过和小美的示范对比后,发现太酸了,少了
12.24克的糖,需要加糖机器人将糖权调大了
0.1克,现在的糖权从1.88克变成了1.98克机器人做了第 2 杯柠檬水,使用的糖权是
1.98克,放了3.96克的糖经过和小美的示范对比后,发现还是太酸了,少了
12.04克的糖,需要继续加糖经过
60次的反复尝试,机器人的糖权是7.98,接近小美所使用的8.0克。
我们好像什么都没有做,但机器人却从一次一次的试错中真的逐渐学到了小美制作柠檬水的秘诀!
问题似乎解决了,但聪明的你发现了两个小漏洞:
首先,在接近最佳口味时,会错过最佳的糖权,导致要么太甜了一点,要么太酸了一点,机器人总是学习不到最佳的糖权。
其次,机器人每次制作柠檬水,都会消耗一定的成本。机器人经过几十上百次的尝试,消耗大量的成本才能学到小美的秘诀。
那么,怎么让机器人学的又快又好呢?
1.7.3. 模型改进#
聪明的你马上又想到,我们能不能不让机器人每次都更新固定的糖权,而是让机器人从损失中动态的调整学习的幅度呢?
这里就要引入一个非常重要的概念:学习率。学习率决定了我们每次调整糖权的幅度,我们按照这个比例根据损失动态调整糖权,差距大就调的多一点,差距小就调的少一点。这样既能保证学习效率,又不会因为调整幅度过大而错过最优解。
固定学习步长和使用学习率的对比:
好想法!快来试试吧!
1.7.3.1. 模型的改进:引入学习率#
在 step() 中添加学习率参数,使得模型在训练过程中,能够根据损失动态调整参数更新的步长,从而提高学习效率。
import random
class Model:
def __init__(self):
# 随机初始化糖权
# self.sugar_weight = random.uniform(0, 50)
self.sugar_weight = 1.88
print(f"🚀 随机初始化的糖权: {self.sugar_weight}")
# 1️⃣ 计算模型预测值
def forward(self, lemon):
return self.sugar_weight * lemon
# 2️⃣ 计算模型预测值与真实值之间的误差
def loss(self, pred_sugar, real_sugar):
return pred_sugar - real_sugar
# 3️⃣ 🌟改进点 1 🌟:直接返回误差的值和更新的方向
def backward(self, loss):
# 使用负号控制更新的方向:太甜了就减糖,不够甜就加糖
return -loss
# 4️⃣ 🌟改进点 2 🌟:引入学习率动态的从损失中进行学习
def step(self, loss, learning_rate):
self.sugar_weight += loss * learning_rate
1.7.3.2. 学习的改进:使用学习率动态学习#
将学习率设置为10%,使用 loss 的十分之一来动态更新参数,而不是固定更新 0.1。
# 训练模型
# 创建模型实例
model = Model()
training_logs = []
learning_rate = 0.1
# 训练模型
for epoch in range(100):
# 1. 计算预测值
pred = model.forward(lemon)
# 2. 计算损失
loss = model.loss(pred, sugar)
# 3. 计算更新的梯度(方向)
step = model.backward(loss)
# 4. 🌟改进点 🌟:引入学习率动态的从损失中进行学习更新参数
model.step(step, learning_rate)
# 记录训练日志,包括更新之后的权重(保留四位小数)
# 按照表头顺序调整:Epoch, 柠檬盘, 当前糖权, 预测放糖量, 目标放糖量, 误差损失, 更新步长, 更新后权重
if epoch < 5 or epoch > 95 or epoch % 5 == 0:
training_logs.append([
epoch,
lemon,
round(model.sugar_weight - learning_rate * step, 4),
round(pred, 4),
sugar,
round(loss, 4),
round(step, 4),
round(model.sugar_weight, 4)
])
# 打印最终参数
print(f"✅ 模型学习到的糖权: {round(model.sugar_weight, 4)}")
print_table("📝 训练日志",
["Epoch", "柠檬片", "当前的糖权", "预测放糖量", "目标放糖量", "误差", "更新步长", "更新后糖权"],
training_logs)
🚀 随机初始化的糖权: 1.88
✅ 模型学习到的糖权: 8.0
📝 训练日志:
+-------+--------+------------+------------+------------+---------+----------+------------+
| Epoch | 柠檬片 | 当前的糖权 | 预测放糖量 | 目标放糖量 | 误差 | 更新步长 | 更新后糖权 |
+-------+--------+------------+------------+------------+---------+----------+------------+
| 0 | 2 | 1.88 | 3.76 | 16 | -12.24 | 12.24 | 3.104 |
| 1 | 2 | 3.104 | 6.208 | 16 | -9.792 | 9.792 | 4.0832 |
| 2 | 2 | 4.0832 | 8.1664 | 16 | -7.8336 | 7.8336 | 4.8666 |
| 3 | 2 | 4.8666 | 9.7331 | 16 | -6.2669 | 6.2669 | 5.4932 |
| 4 | 2 | 5.4932 | 10.9865 | 16 | -5.0135 | 5.0135 | 5.9946 |
| 5 | 2 | 5.9946 | 11.9892 | 16 | -4.0108 | 4.0108 | 6.3957 |
| 10 | 2 | 7.3429 | 14.6857 | 16 | -1.3143 | 1.3143 | 7.4743 |
| 15 | 2 | 7.7847 | 15.5693 | 16 | -0.4307 | 0.4307 | 7.8277 |
| 20 | 2 | 7.9294 | 15.8589 | 16 | -0.1411 | 0.1411 | 7.9436 |
| 25 | 2 | 7.9769 | 15.9538 | 16 | -0.0462 | 0.0462 | 7.9815 |
| 30 | 2 | 7.9924 | 15.9848 | 16 | -0.0152 | 0.0152 | 7.9939 |
| 35 | 2 | 7.9975 | 15.995 | 16 | -0.005 | 0.005 | 7.998 |
| 40 | 2 | 7.9992 | 15.9984 | 16 | -0.0016 | 0.0016 | 7.9993 |
| 45 | 2 | 7.9997 | 15.9995 | 16 | -0.0005 | 0.0005 | 7.9998 |
| 50 | 2 | 7.9999 | 15.9998 | 16 | -0.0002 | 0.0002 | 7.9999 |
| 55 | 2 | 8.0 | 15.9999 | 16 | -0.0001 | 0.0001 | 8.0 |
| 60 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 65 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 70 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 75 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 80 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 85 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 90 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 95 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 96 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 97 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 98 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
| 99 | 2 | 8.0 | 16.0 | 16 | -0.0 | 0.0 | 8.0 |
+-------+--------+------------+------------+------------+---------+----------+------------+
同样,我们的机器人猜测的糖权是 1.88 克,每次让机器人从差距中学习 0.1 比例来更新糖权。
我们来看一下具体过程:
机器人做的第一杯柠檬水,使用的糖权是
1.88克,放了3.76克的糖经过“撒糖哥”评估后,表示太酸了,少了
12.24克的糖,需要加糖机器人学习
0.1比例的差距,将糖权调大了1.224克,现在的糖权是3.104克这次只经过
20次的尝试,机器人的糖权就达到了7.9436,速度远远快于前面的学习方式
在第 55 次迭代时,机器人找到了最佳的糖权,这次没有在最佳位置来回的震荡。
太厉害了!我们的机器人彻底学会了小美制作柠檬水的秘诀!
1.8. 模型评估#
训练模型的目的是让模型从过去的数据中“学习”经验,用学到的经验来解决未见过但类似的新问题,这个过程称为模型预测或模型推理。
我们的机器人已经学会了制作柠檬水的配方,现在就来试试做一些新的柠檬水来评估模型的效果。
from dsxllm.util import print_regression_predictions
# 使用预训练的模型进行预测未见过的样本
lemons = [3, 4, 5]
real_sugars = [24, 32, 40]
pred_sugars = [model.forward(lemon) for lemon in lemons]
print_regression_predictions(lemons, real_sugars, pred_sugars, "🆕 制作新的柠檬水",
["柠檬片", "真实放糖量", "预测放糖量", "预测偏差", "预测精度"])
🆕 制作新的柠檬水:
+--------+------------+------------+----------+----------+
| 柠檬片 | 真实放糖量 | 预测放糖量 | 预测偏差 | 预测精度 |
+--------+------------+------------+----------+----------+
| 3 | 24 | 24.0 | -0.0000 | 100.00% |
| 4 | 32 | 32.0 | -0.0000 | 100.00% |
| 5 | 40 | 40.0 | -0.0000 | 100.00% |
+--------+------------+------------+----------+----------+
我们发现,虽然小美只给我们示范了如何使用 2 片柠檬片做柠檬水,但机器人却可以神奇的预测出 3、4、5 片柠檬所放的糖量,真是青出于蓝而胜于蓝,居然能处理从来没见过的新情况,具有非常好的泛化性!
提示
简言之,机器学习就是通过数据驱动的方式,让计算机从经验中“学习”,用学到的经验来解决未见过但类似的新问题。
机器学习的实现可以分成两步:训练和预测,分别对应着归纳和演绎。
归纳是“学”,是从具体到一般的总结。
演绎是“用”,是从一般到具体的应用。
1.9. 本章小结#
本章通过一个简单的“柠檬水模型”,直观地介绍了机器学习的基本流程,这是大家理解人工智能的基础。开发一个机器学习模型通常遵循以下四个步骤:数据准备、模型定义、模型训练与模型评估。模型的训练是一个迭代的过程,通过不断迭代,模型能够逐渐学习到数据中的规律,并用于预测新数据。另外,模型训练过程中,我们引入了学习率,使得模型能够根据误差动态调整学习幅度,从而实现更快速、精确的收敛。
本次任务根据柠檬片数量预测糖的用量,是一个典型单参数的回归任务。任务虽然简单,却能帮我们认识到机器学习的本质,机器学习是一个从具体数据中“归纳”规律,并将规律“演绎”应用于新问题的过程。下一章,我们将以此为基础探索更复杂的任务。
1.10. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。